
Data protection lessons from a tomato? Have I gone mad?
Bear with me.
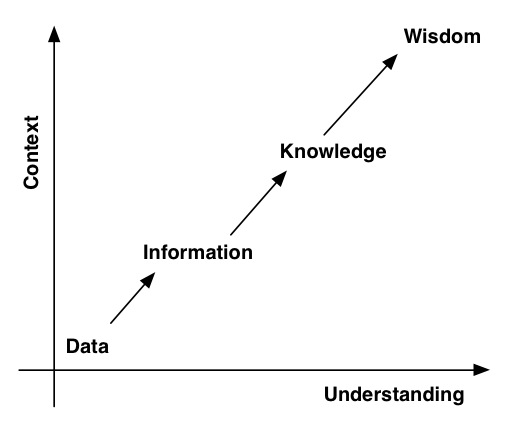 If you’ve done any ITIL training, the above diagram will look familiar to you. Rather unimaginatively, it’s called the DIKW model:
If you’ve done any ITIL training, the above diagram will look familiar to you. Rather unimaginatively, it’s called the DIKW model:
Data > Information > Knowledge > Wisdom
A simple, practical example of what this diagram/model means is the following:
- Data – Something is red, and round.
- Information – It’s a tomato.
- Knowledge – Tomato is a fruit.
- Wisdom – You don’t put tomato in a fruit salad.
That’s about as complex as DIKW gets. However, being a rather simple concept, it means it can be used in quite a few areas.
When it comes to data protection, its purpose is obvious: the criticality of the data to business wisdom will have a direct impact on the level of protection you need to apply to it.
In this case, I’m expanding the definition of wisdom a little. According to my Apple dashboard dictionary, wisdom is:
the quality of having experience, knowledge, and good judgement; the quality of being wise
Further, we can talk about wisdom in terms of accumulated experience:
the body of knowledge and experience that develops within a specified society or period.
So corporate wisdom is about having the experience and knowledge required to act with good judgement, and represents the sum of the knowledge and experience a corporation has built up over time.
If you think about wisdom in terms of corporate wisdom, then you’ll understand my point. For instance, a key database for a company – or the email system – represents a tangible chunk of corporate wisdom. Core fileservers will also be pretty far up the scale. It’s unlikely, on the other hand (in a business with appropriate storage policies) that the files on a regular end-user’s desktop or laptop will go much beyond information in the DIKW scale.
Of course, there are always exceptions. I’ll get to that in a moment.
What this comes back to pretty quickly is the need for Information Lifecycle Protection. End users and the business overall are typically not interested in data – they’re interested in information. They don’t care, as such, about the backup of /u01/app/oracle/data/CORPTAX/data01.dbf – they care about the corporate tax database. That, of course, means that the IT group and the business need to build service level agreements around business functions, not servers and storage. As ITIL teaches, the agreements about networks, storage, servers, etc., come in the form of operational level agreements between the segments of IT.
Ironically, years before studying ITIL, it’s something I covered in my book in the notion of establishing system dependency maps:
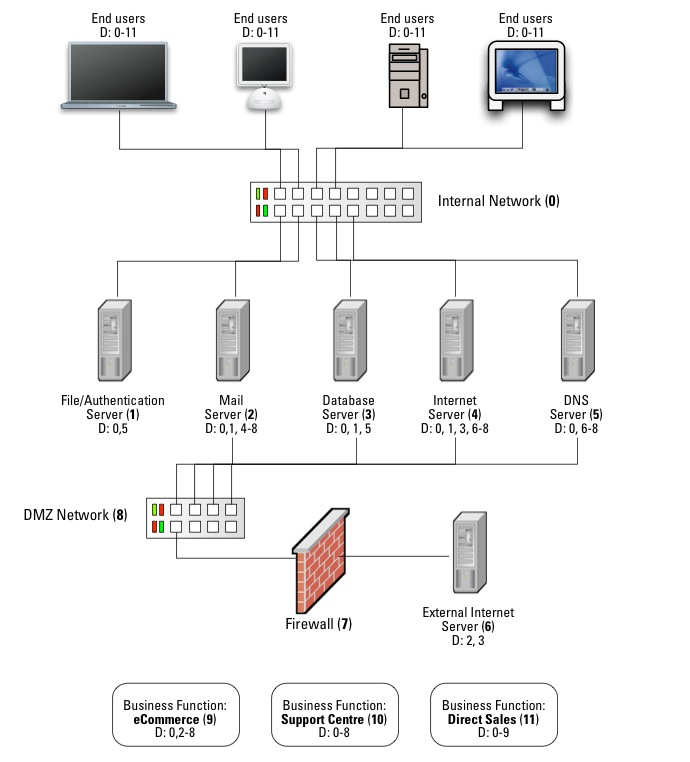
(In the diagram, the number in parentheses beside a server or function is it’s reference number; D:X means that it depends on the nominated referenced server/function X.)
What all this boils down to is the criticality of one particular activity when preparing an Information Lifecycle Protection system within an organisation: Data classification. (That of course is where you should catch any of those exceptions I was talking about before.)
In order to properly back something up with the appropriate level of protection and urgency, you need to know what it is.
Or, as Stephen Manley said the other day:
OH at Starbucks – 3 page essay ending with ‘I now have 5 pairs of pants, not 2. That’s 3 more.’ Some data may not need to be protected.
Some data may not need to be protected. Couldn’t have said it better myself. Of course, I do also say that it’s better to backup a little bit too much data than not enough, but that’s not something you should see as carte blanche to just backup everything in your environment at all times, regardless of what it is.
The thing about data classification is that most companies do it without first finding all their data. The first step, possibly the hardest step, is first becoming aware of the data distribution within the enterprise. If you want to skip reading the post linked to in the previous sentence, here’s the key information from it:
- Data – This is both the core data managed and protected by IT, and all other data throughout the enterprise which is:
- Known about – The business is aware of it;
- Managed – This data falls under the purview of a team in terms of storage administration (ILM);
- Protected – This data falls under the purview of a team in terms of backup and recovery (ILP).
- Dark Data – To quote [a] previous article, “all those bits and pieces of data you’ve got floating around in your environment that aren’t fully accounted for”.
- Grey Data – Grey data is previously discovered dark data for which no decision has been made as yet in relation to its management or protection. That is, it’s now known about, but has not been assigned any policy or tier in either ILM or ILP.
- Utility Data – This is data which is subsequently classified out of grey data state into a state where the data is known to have value, but is not either managed or protected, because it can be recreated. It could be that the decision is made that the cost (in time) of recreating the data is less expensive than the cost (both in literal dollars and in staff-activity time) of managing and protecting it.
- Noise – This isn’t really data at all, but are all the “bits” (no pun intended) that are left which are neither grey data, data or utility data. In essence, this is irrelevant data, which someone or some group may be keeping for unnecessary reasons, and in actual fact should be considered eligible for either deletion or archival and deletion.
Once you’ve found your data, you can classify it. What’s structured and unstructured? What’s the criticality of the data? (I.e., what level of business wisdom does it relate to?)
But even then, you’re not quite ready to determine what your information lifecycle protection policy will be for the data – well, not until you have a data lifecycle policy, which at its simplest, looks something like this:

Of course, there’s a lot of time and a lot of decisions bunched up in that diagram, but the lifecycle of data within an organisation is actually that simple at the conceptual level. Or rather, it should be. If you want to read more about data lifecycle, click here for the intro piece – there’s several accompanying pieces listed at the bottom of the article.
When considered from a backup perspective, the end goal of a data lifecycle policy though is simple:
Backup only that which needs to be backed up.
If data can be deleted, delete it.
If data can be archived, archive it.
The logical implication of course is – if you can’t classify it, if you can’t determine its criticality, then the core backup mantra, “always better to backup a little bit more than not enough” takes precedence, and you should be working out how to back it up. Obviously, as a fall back rule, it works, but it’s best to design your overall environment and data policies to avoid it.
So to summarise:
- Following the DIKW model, the closer data is to representing corporate wisdom, the more critical its information lifecycle protection requirements will be.
- In order to determine that criticality you first have to find the data within your environment.
- Once you’ve found the data in your environment, you have to classify it.
- Once you’ve classified it, you can build a data lifecycle policy for it.
- And then you can configure the appropriate information lifecycle protection for it.
If you think back to EMC’s work towards mitigating the effects of accidental architectures, you’ll see where I was coming from in talking about the importance of procedural change to arrest further accidental architectures. It’s a classic ER technique – identify, triage and heal.
And we can learn all this from a tomato, sliced and salted with the DIKW model.