So you’ve got your primary data stored on one array and it replicates to another array. How many backup copies do you need?

There’s no doubt we’re spawning more and more copies and pseudo-copies of our data. So much so that EMC’s new Enterprise Copy Data Management (eCDM) product was announced at EMC World. (For details on that, check out Chad’s blog here.)
With many production data sets spawning anywhere between 4 and 10 copies, and sometimes a lot more, a question that gets asked from time to time is: why would I need to duplicate my backups?
It seems a fair question if you’re using array to array replication, but let’s stop for a moment and think about the different types of data protection being applied in this scenario:
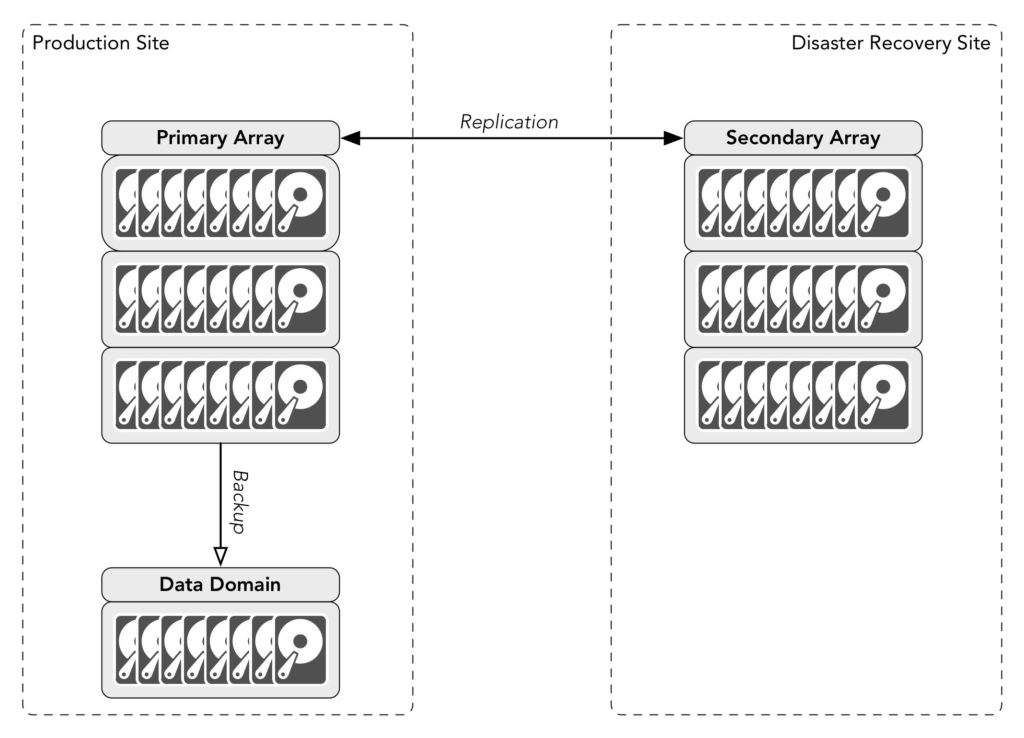
Let’s say we’ve got two sites, production and disaster recovery, and for the sake of simplicity, a single SAN at each site. The two SANs replicate between one another. Backups are taken at one of the sites – in this example, the production site. There’s no duplication of the backups.
Replication is definitely a form of data protection, but its primary purpose is to provide a degree of fault tolerance – not true fault tolerance of course (that requires more effort), but the idea is that if the primary array is destroyed, there’s a copy of the data on the secondary array and it can take over production functions. Replication can also factor into maintenance activities – if you need to repair, update or even replace the primary array, you can failover operations to the secondary array, work on the primary, then fail back when you’re ready.
In the world of backups there’s an old saying however: nothing corrupts faster than a mirror. The same applies to replication…
“Ahah!”, some interject at this point, “What if the replication is asynchronous? That means if corruption happens in the source array we can turn off replication between the arrays! Problem solved!”
Over a decade ago I met an IT manager who felt the response to a virus infecting his network would be to have an operator run into the computer room and use an axe to quickly chop all the network connections away from the core switches. That might actually be more successful than relying on noticing corruption ahead of asynchronous replication windows and disconnecting replication links.
So if there’s corruption in the primary array that infects the secondary array – that’s no cause for concern, right? After all there’s a backup copy sitting there waiting and ready to be used. The answer is simple – replication isn’t just for minor types of fault tolerance or being able to switch production during maintenance operations, it’s also for those really bad disasters, such as something taking out your datacentre.
At this point it’s common to ‘solve’ the problem by moving the backups onto the secondary site (even if they run cross-site), creating a configuration like the following:
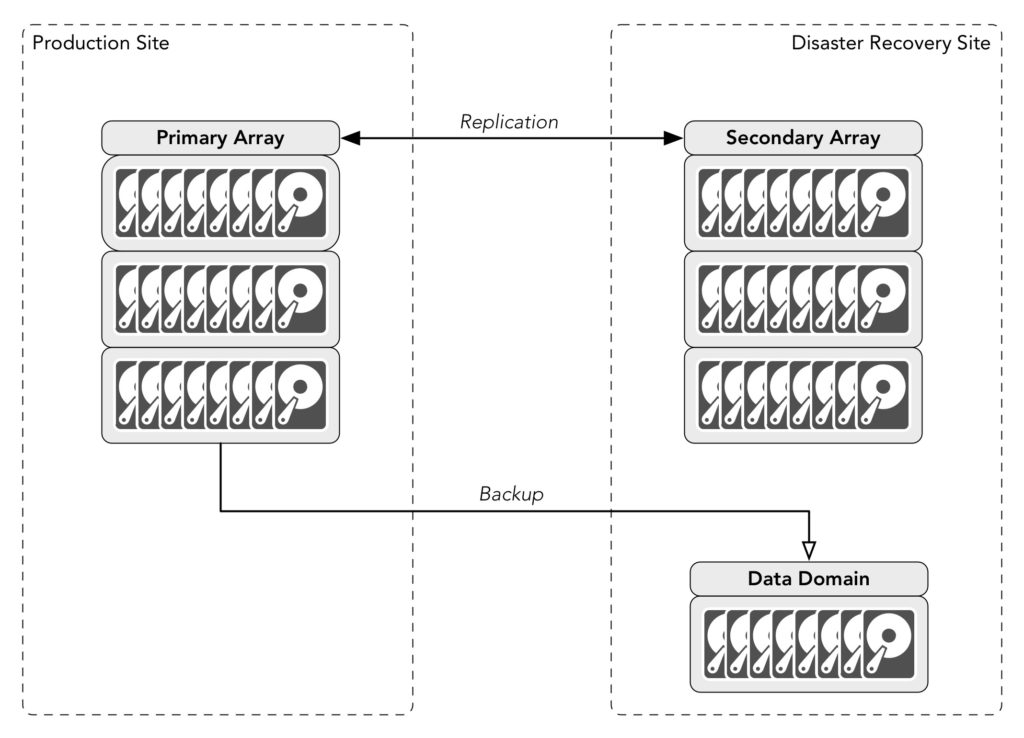
The thinking goes like this: if there’s a disaster at the primary site, the disaster recovery site not only takes over, but all our backups are there waiting to be used. If there’s a disaster at the disaster recovery site instead, then no data has been lost because all the data is still sitting on the production array.
Well, in only one very special circumstance: if you only need to keep backups for one day.
Backups typically offer reasonably poor RPO and RTO compared to things like replication, continuous data protection, continuous availability, snapshots, etc. But they do offer historical recoverability often essential to meet compliance requirements. Having to provide a modicum of recoverability for 7 years is practically the default these days – medical organisations typically have to retain data for the life of the patient, engineering companies for the lifespan of the construction, and so on. That’s not all backups of course – depending on your industry you’ll likely generate your long term backups either from your monthlies or your yearlies.
Aside: The use of backups to facilitate long term retention is a discussion that’s been running for the 20 years I’ve been working in data protection, and that will still be going in a decade or more. There are strong, valid arguments for using archive to achieve long term retention, but archive requires a data management policy, something many companies struggle with. Storage got cheap and the perceived cost of doing archive created a strong sense of apathy that we’re still dealing with today. Do I agree with that apathy? No, but I still have to deal with the reality of the situation.
So let’s revisit those failure scenarios again that can happen with off-site backups but no backup duplication:
- If there’s a disaster at the primary site, the disaster recovery site takes over, and all backups are preserved
- If there’s a disaster at the secondary site, the primary site is unaffected but the production replica data and all backups are lost: short term operational recovery backups and longer term compliance/legal retention backups
Is that a risk worth taking? I had a friend move interstate recently. The day after he moved in, his neighbour’s house burnt down. The fire spread to his house and destroyed most of his possessions. He’d been planning on getting his contents insurance updated the day of the fire.
Bad things happen. Taking the risk that you won’t lose your secondary site isn’t really operational planning, it’s casting your fate to the winds and relying on luck. The solution below though doesn’t rely on luck at all:
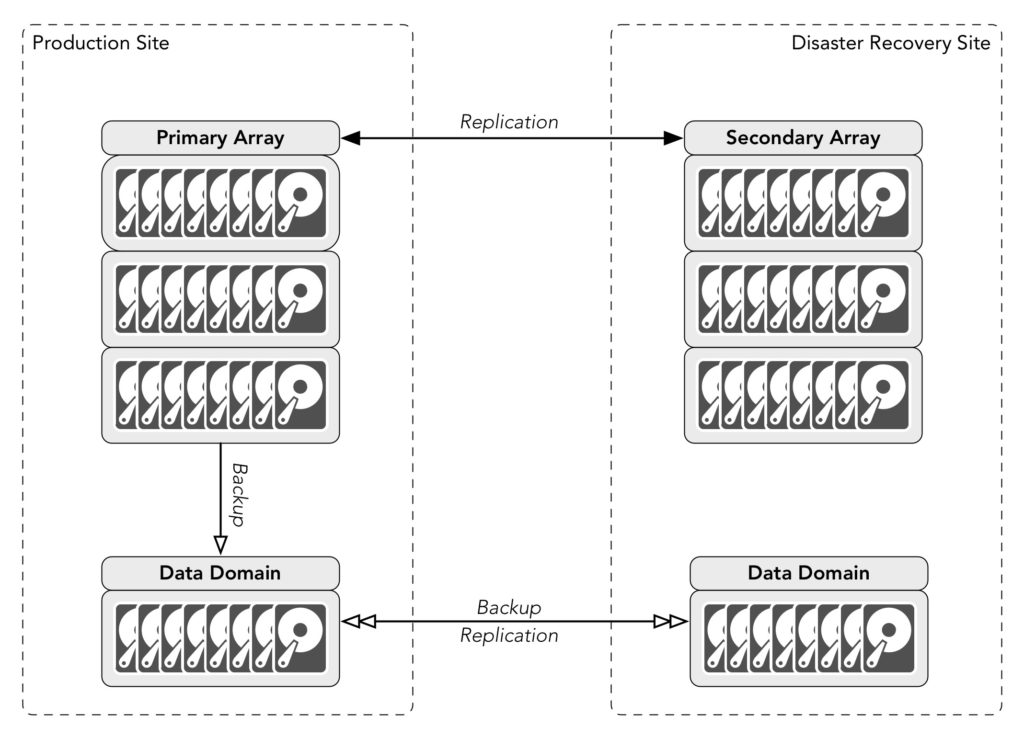
There’s undoubtedly a cost involved; each copy of your data has a tangible cost regardless of whether that’s a primary copy or a secondary copy. Are there some backups you won’t copy? That depends on your requirements: there may for instance be test systems you need to backup, but there’s no need to have a secondary copy of them, but such decisions still have to be made on a risk vs cost basis.
Replication is all well and good, but it’s not a get-out-of-gaol card for avoiding cloned backups.