In the 90s, if you wanted to define a “disaster recovery” policy for your datacentre, part of that policy revolved around tape. Back then, tape wasn’t just for operational recovery, but also for disaster recovery – and even isolated recovery. In the 90s of course, we weren’t talking about “isolated recovery” in the same way we do now, but depending on the size of the organisation, or its level of exposure to threats, you might occasionally find a company that would make three copies of data – the on-site tape, the off-site tape, and then the “oh heck, if this doesn’t work we’re all ruined” tape.

These days, whatever you might want to use tape for within a datacentre (and yes, I’ll admit that sometimes it may still be necessary, though I’d argue far less necessary than the average tape deployment), something you most definitely don’t want to use it for is disaster recovery.
The reasoning is simple – time. To understand what I mean, let’s look at an example.
Let’s say your business has an used data footprint for all production systems of just 300 TB. I’m not talking total storage capacity here, just literally the occupied space across all DAS, SAN and NAS storage just for production systems. For the purposes of our discussion, I’m also going to say that based on dependencies and business requirements, disaster recovery means getting back all production data. Ergo, getting back 300 TB.
Now, let’s also say that your business is using LTO-7 media. (I know LTO-8 is out, but not everyone using tape updates as soon as a new format becomes available.) The key specifications on LTO-7 are as follows:
- Uncompressed capacity: 6 TB
- Max speed without compression: 300 MB/s
- Typical rated compression: 2.5:1
Now, I’m going to stop there. When it comes to tape, I’ve found the actual compression ratios achieved to be wildly at odds with reality. Back when everyone used to quote a 2:1 compression ratio, I found that tapes yielding 2:1 or higher were in the extreme, and the norm was more likely 1.4:1, or 1.5:1. So, I’m not going to assume you’re going to get compression in the order of 2.5:1 just because the tape manufacturers say you will. (They also say tapes will reliably be OK on shelves for decades…)
A single LTO-7 tape, if we’re reading or writing at full speed, will take around 5.5 hours to go end-to-end. That’s very generously assuming no shoe-shining and that the read or write can be accomplished as a single process – either via multiplexing, or a single stream. Let’s say you get 2:1 compression on the tape. That’s 12 TB, but still takes 5.5 hours to complete (assuming a linear increase in tape speed. And at 600MB/s, that’s getting iffy – but again, bear with me.)
Drip, drip, drip.
Now, tape drives are always expensive – so you’re not going to see enough tape drives to load one tape per drive, fill the tape, and bang, your backup is done for your entire environment. Tape libraries exist to allow the business to automatically switch tapes as required, avoiding that 1:1 relationship between backup size and the number of drives used.
So let’s say you’ve got 3 tape drives. That means in 5.5 hours, using 2:1 compression and assuming you can absolutely stream at top speed for that compression ratio, you can recover 36 TB. (If you’ve used tape for as long as me, you’ll probably be chuckling at this point.)
So, that’s 36 TB in the first 5.5 hours. At this point, things are already getting a little absurd, so I’ll not worry about the time it takes to unload and load new media. The next 36 TB is done in another 5.5 hours. If we continue down that path, our first 288 TB will be recovered after 44 hours. We might then assume our final 12TB fitted snugly on a single remaining tape – which will take another 5.5 hours to read, getting us to a disaster recovery time of 49.5 hours.
Drip, drip, drip.
Let me be perfectly frank here: those numbers are ludicrous. The only way you have a hope of achieving that sort of read speed in a disaster recovery for that many tapes is if you are literally recovering a 300 TB filesystem filled almost exclusively with 2GB files that each can be compressed down by 50%. If your business production data doesn’t look like that, read on.
Realistically, in a disaster recovery situation, I’d suggest you’re going to look at at least 1.5x the end-to-end read/write time. For all intents and purposes, that assumes the tapes are written with say, 2-way multiplexing and we can conduct 2 reads across it, where each read is able to use filemark-seek-forward (FSFs) to jump over chunks of the tape.
5.5 hours per tape becomes 8.25 hours. (Even that, I’d say, is highly optimistic.) At that point, the 49.5 hour recovery is a slightly more believable 74.25 hour recovery. Slightly. That’s over 3 days. (Don’t forget, we still haven’t factored in tape load, tape rewind, and tape unload times into the overall scope.)
Drip, drip, drip.
What advantage do we get if we read from disk instead of tape? Well, if we’re going to go down that path, we’re going to get instant access (no load, unload or seek times), and concurrency (highly parallel reads – recovering fifty systems at a time, for instance).
But here’s the real kicker. Backup isn’t disaster recovery. And particularly, tape backup is disaster recovery in the same way that a hermetically sealed, 100% barricaded house is safety from a zombie apocalypse. (Eventually, you’re going to run out of time, i.e., food and water.)
This is, quite frankly, where the continuum comes into play:

More importantly, this is where picking the right data protection methodology for the SLAs (the RPOs and RTOs) is essential, viz.:
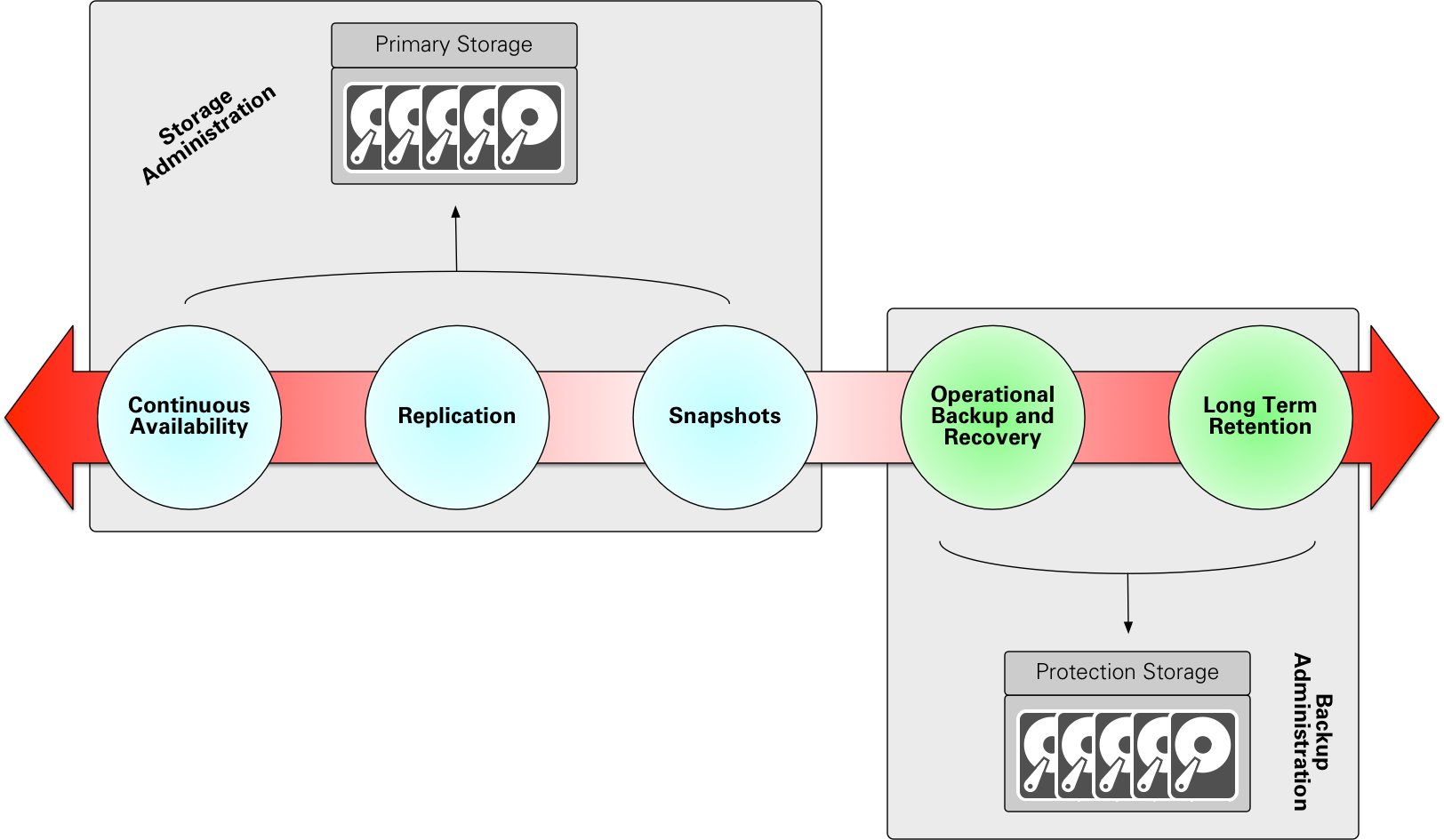
Backup and recovery systems might be a fallback position when all other types of disaster recovery have been exhausted, but at the point you’ve decided to conduct a disaster recovery of your entire business from physical tape, you’re in a very precarious position. It might have been a valid option in the 90s, but in a modern data protection environment, there’s a plethora of higher level systems that should be built into a disaster recovery strategy. I’ve literally seen examples of companies when, faced with having to do a complete datacentre recovery from tape, taking a month or more to get back operational. (If ever.)
Like the old saying goes – if all you have is a hammer, everything looks like a nail. “Backup only” companies have a tendency to encourage you to think as backup as a disaster recovery function, or even to think of disaster recovery/business continuity as someone else’s problem. Talking disaster recovery is easiest when able to talk to someone across the entire continuum.
Otherwise you may very well find your business perfectly safely barricaded into a hermetically sealed location away from the zombie hoard, watching your food and water supplies continue to decrease hour by hour, day by day. Drip, drip, drip.
Planning holistic data protection strategies is more than just backup – and it’s certainly more than just tape. That’s why Data Protection: Ensuring Data Availability looks at the entire data storage protection spectrum. And that’s why I work for DellEMC, too. It’s not just backup. It’s about the entire continuum.