
Where we’re at A few weeks ago I posted a (lengthy) Perl script (and explanation) for running deduplication analysis against…
Where we’re at A few weeks ago I posted a (lengthy) Perl script (and explanation) for running deduplication analysis against…
If you use NetWorker with Data Domain, you’ve probably sometimes wanted to know which of your clients have the best…

OK, let’s look at common data protection challenges through the eyes of memes again! I’m a big fan of backup…

Let’s start the week off by thinking of a few data protection topics through the awesome window of memes, shall…

Here’s a typical sort of challenge: you’ve got a workload running in public cloud, but there’s a strong desire to…

Here’s a topic that comes up from time to time: block size in deduplication. (Note here I’m using the term…
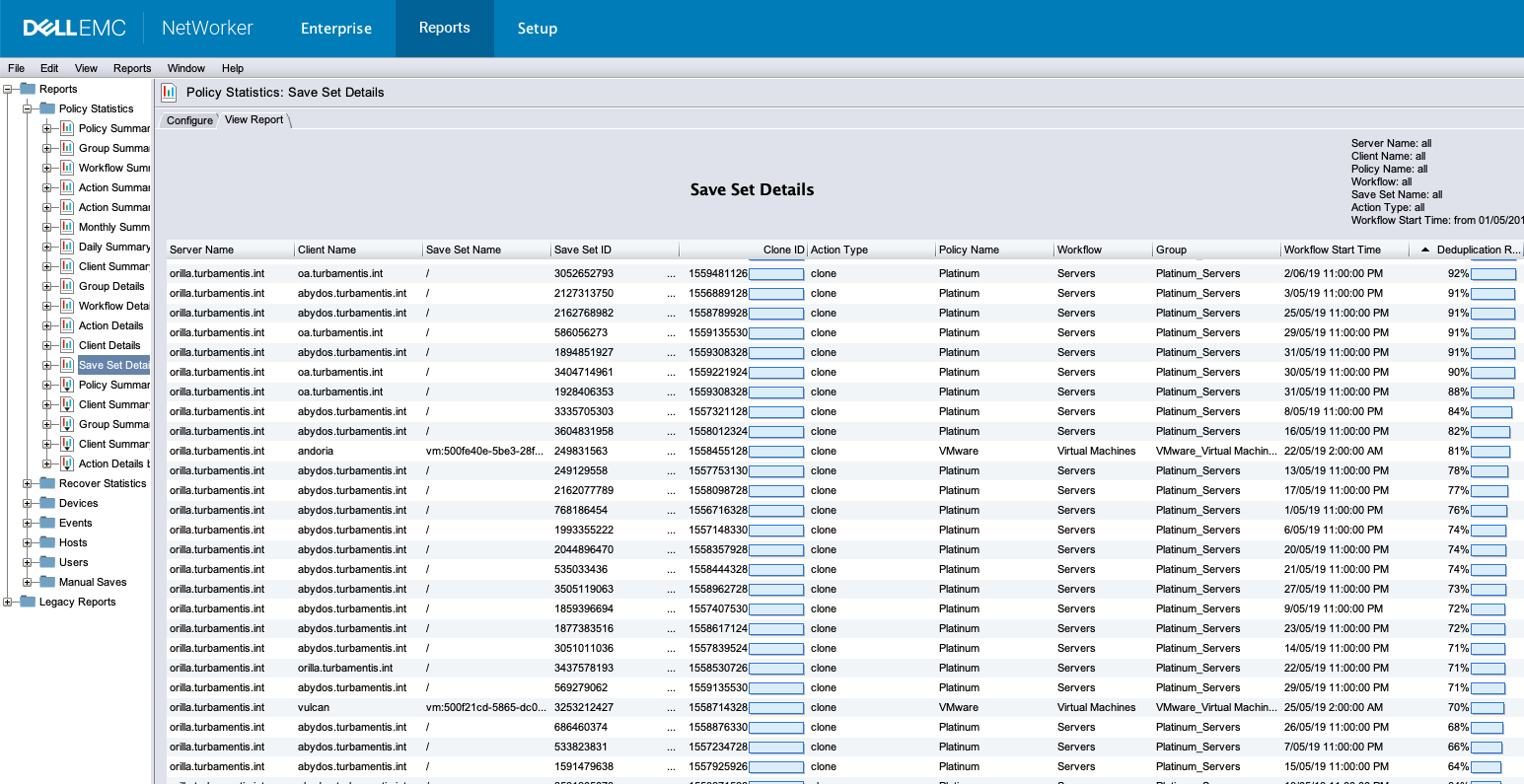
Sometimes, backups don’t deduplicate as you’d expect them to. Someone, somewhere, decided that spare 5TB on a server would be…

Some blogging history On 25 January 2009, I published the first article on what was then the NetWorker Blog: How…
Introduction When you’re writing backups to tape, capacity reclamation is pretty straight forward (unless you’re using an archive product that…

Introduction When NetWorker 18.1 was released, it wasn’t just the core NetWorker environment that got an update – the application…