
Introduction Here’s a question I get asked quite frequently: “If we have a vault, how will the vault team know…
Introduction Here’s a question I get asked quite frequently: “If we have a vault, how will the vault team know…

One of the most useful recoveries you can do in Avamar, NetWorker or PowerProtect Data Manager is the changed block…

One of the changes introduced in NetWorker 19.3 was the inclusion of file-level recoverability from traditional backups via the NetWorker…

Here’s a really great function of NetWorker: being able to kick off the recovery of multiple virtual machines simultaneously. One…

While Avamar has options for automating the test of virtual machine recoveries, it’s not functionality that’s present in NetWorker. Recently…

In this continuing PPDM basics series, I wanted to step you through the process of the following two activities: Performing…

Let’s start the week off by thinking of a few data protection topics through the awesome window of memes, shall…
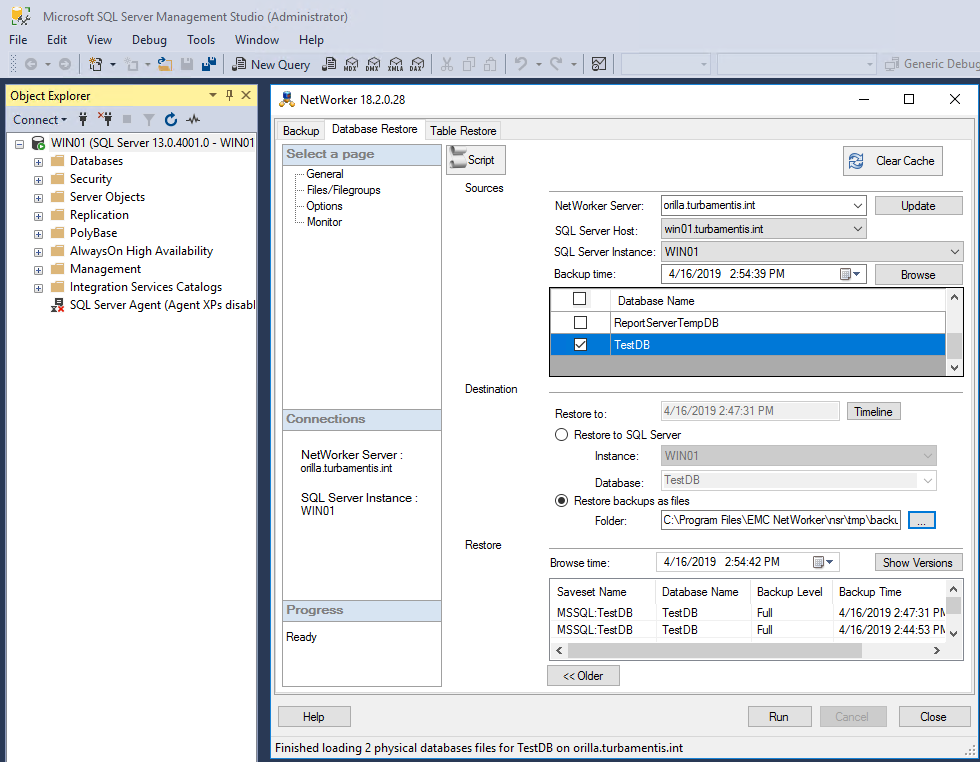
You don’t always want to be able to recover a database backup as a live database – either overwriting an existing…

Let’s consider a theoretical scenario: your business has been hit by Ransomware, and a chunk of data on a fileserver…

Introduction When NetWorker 18.1 was released, it wasn’t just the core NetWorker environment that got an update – the application…