One question that comes up every now and then concerns having an optimal approach to Data Domain Boost devices in NetWorker when doing both daily and monthly backups.
Under NetWorker 7.x and lower, when the disk backup architecture was considerably less capable (resulting in just one read nsrmmd and one write nsrmmd for each ADV_FILE or Data Domain device) it was invariably the case that you’d end up with quite a few devices, with typically no more than 4 as the target/max sessions setting for each device.
With NetWorker 8 having the capability of running multiple nsrmmds per device, the architectural reasons around splitting disk backup have diminished. For ADV_FILE devices, unless you’re using a good journaling filesystem that can recover quickly from a crash, you’re likely still going to need multiple filesystems to avoid the horror of a crash resulting in a 8+ hour filesystem check. (For example, on Linux I tend to use XFS as the filesystem for ADV_FILE devices for precisely this reason.)
Data Domain is not the same as conventional ADV_FILE devices. Regardless of whether you allocate 1 or 20 devices in NetWorker from a Data Domain server, there’s no change in LUN mappings or background disk layouts. It’s all a single global storage pool. What I’m about to outline is what I’d call an optimal solution for daily and monthly backups using boost. (As is always the case, you’ll find exceptions to every rule, and NetWorker lets you achieve the same result using a myriad of different techniques, so there are potentially other equally optimal solutions.)
Pictorially, this will resemble the following:
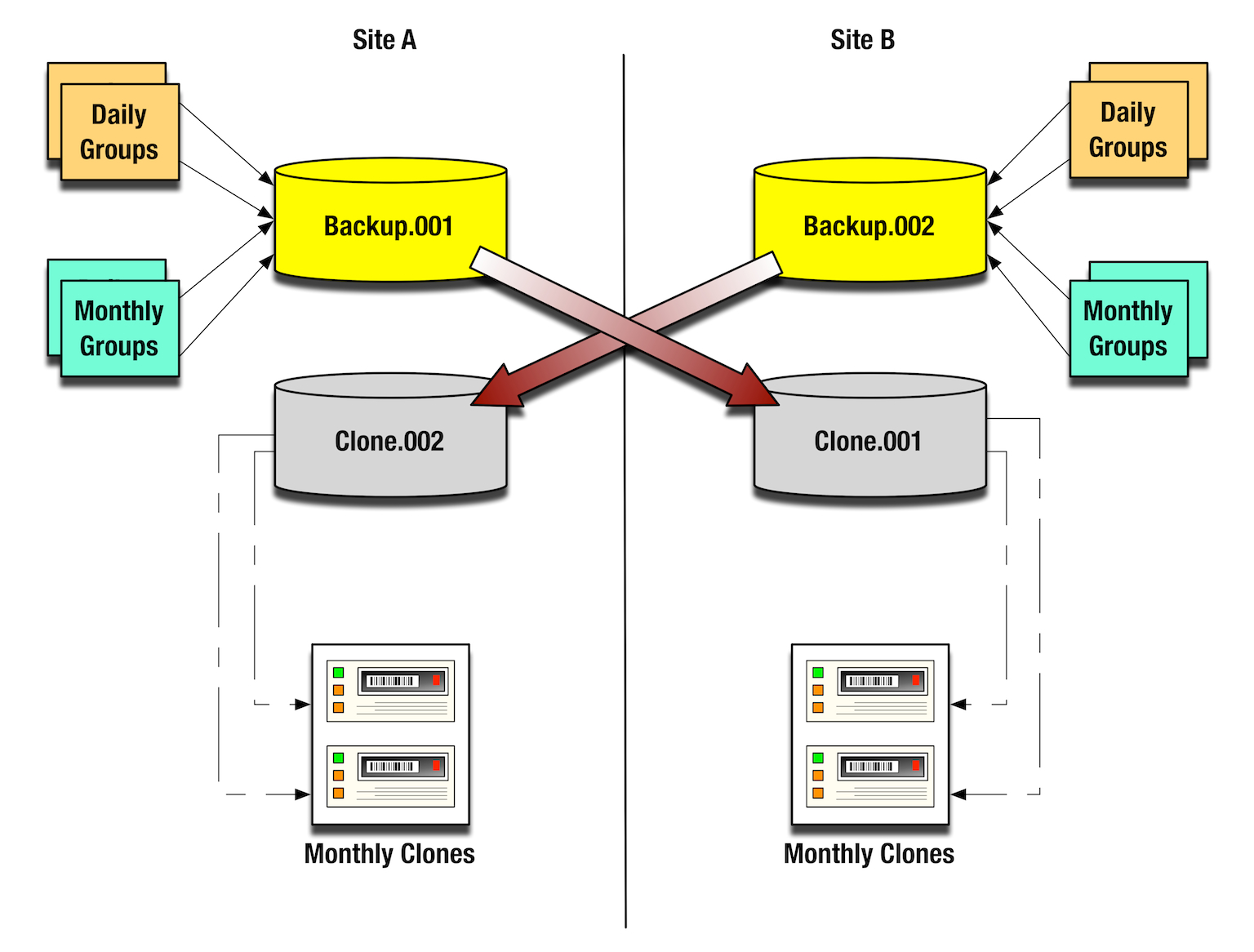
The daily backups will be kept on disk for their entire lifetime, and the monthly backups will be kept on disk for a while, but cloned out to tape so that they can be removed from disk to preserve space over time.
A common enough approach under NetWorker 7.6 and below was to have a bunch of devices defined at each site, half for daily backups and half for monthly backups, before any clone devices were factored into consideration.
These days, between scheduled cloning policies and Data Domain boost, it can be a whole lot simpler.
All the “Daily” groups and all the “Monthly” groups can write to the same backup device in each location. Standard group based cloning will be used to copy the backup data from one site to the other – NetWorker/Boost controlled replication. (If you’re using NetWorker 8.1, you can even enable the option to have NetWorker trigger the cloning on a per saveset basis within the group, rather than waiting for each group to end before cloning is done.)
If you only want the backups from the Monthly groups to stay on the disk devices for the same length of time as the Daily retention period, you’ve got a real winning situation – you can add an individual client to both the relevant Daily and Monthly groups, with the client having the daily retention period assigned to it. If you want the backups from the Monthly groups to stay on disk, it’ll be best to keep two separate client definitions for each client – one with the daily retention period, and one with the on-disk monthly retention period.
Monthly backups would get cloned to tape using scheduled clone policies. For the backups that need to be transferred out to tape for longer-term retention, you make use of the option to set both browse and retention time for the cloned savesets. (You can obviously also make use of the copies option for scheduled cloning operations and generate two tape copies for when the disk copy expires.)
In this scenario, the Monthly backups are written to disk with a shorter retention period, but cloned out to tape with the true long-term retention. This ensures that the disk backup capacity is managed automatically by NetWorker while long-term backups are stored for their required retention period.
Back to the Data Domain configuration however, the overall disk backup configuration itself is quite straight forward: with multiple nsrmmd processes running per device, the same result is achieved with one Data Domain Boost device as would have been achieved with multiple Boost devices under 7.6.x and lower.
Great post! You mentioned using XFS under Linux for AFTDs. I wanted to bring to your and your readers’ attention a known bug on SUSE Linux Enterprise Server (SLES) 11 service pack 1 with Linux kernel versions prior to 2.6.32.49-0.3.1. Novell bug 721830 describes a “Memory Reclaim Recursion Deadlock on Locked Inode Buffer” resulting in a deadlock situation.
To resolve the issue, users should patch their kernels to 2.6.32.49-0.3.1 or higher.
There is one thing which should be mentioned here too (though not directly directed). When (and if) planning such setup you benefit more from setup where instead of 1 DD box on each site you have 2 and second one is always used as replication target. I didn’t see EMC pushing such setup officially, but Quantum in their presales attempts did and they did quite openly stated that such setup gives less overload on their boxes (actually, they did offer such setup cheaper with more storage for less money with licenses included). With Data Domain, similar (well, the same) rule applies.
This is pretty much the scenario which we use as well. However, we already sort the data at the backup time:
– 2 storage nodes with 1 DD each
– 2 pools (1 for backups to be cloned, 1 for the data which remains uncloned). Client retention is 1 month.
– 2 DD devices for the each pool at each side (failover approach)
– 1 large silo for the clone jobs from the ‘to clone’ volumes, receiving the data directly from the backup media (6 LTO5s/node).
We set the SS retention for the clones via command line to 18 months.
However, instead of controlling the clones’ retention policy via separate groups, we actually use scripts to start 1 clone job/device, only cloning the fulls made during the first week. This has several benefits:
– The runtime of the group is shorter as cloning is offloaded.
– If you must restart a group you can do this earlier.
– A ‘hung’ clone job does not affect the backup group.
– You can have multiple clone jobs running at the same time.
– If one clone job fails, you can easily restart it. In fact the script has been setup that way that it runs the query on a daily base. So missed clones will automatically be picked up the next day.
Your has a better redundancy but of course it is more expensive.
IMHO ours is easier to manage as it avoids the necessity to have multiple groups. And it is more flexible.
Hi Carsten,
As I mentioned, there’s multiple ways to achieve the scenario, but there’s a few things I’d note:
(a) As you pointed out, my scenario provides greater redundancy. It does also provide for a similar flexibility to what you’re describing. After all, a clone policy can be used to only clone the full backups for a particular group if you so desire.
(b) You can have multiple clone jobs running at the same time. Under 8.0 and higher you can run multiple clones from the same device/volume now, and you can arrange the subsequent clone operations by groups if you wish so as to have concurrent cloning from a single Data Domain volume.
Cheers,
Preston.
Using same design