I’m a big fan of lab testing – it’s the only way you can safely work out how to do potentially destructive activities, it’s a great way to practice, and it’s equally a great way of evaluating.
A deduplication appliance is a big investment. You’re not just buying disk, you’re buying a chunk of intellectual property and some really smart approaches to data storage. So even with various (and sometimes amazing) levels of discounting available from many vendors from their RRP deduplication appliances, buying such an appliance is sometimes a considerable stretch for organisations who like to evaluate technology first.
As we know from the yearly NetWorker survey, use of deduplication is going through the roof:
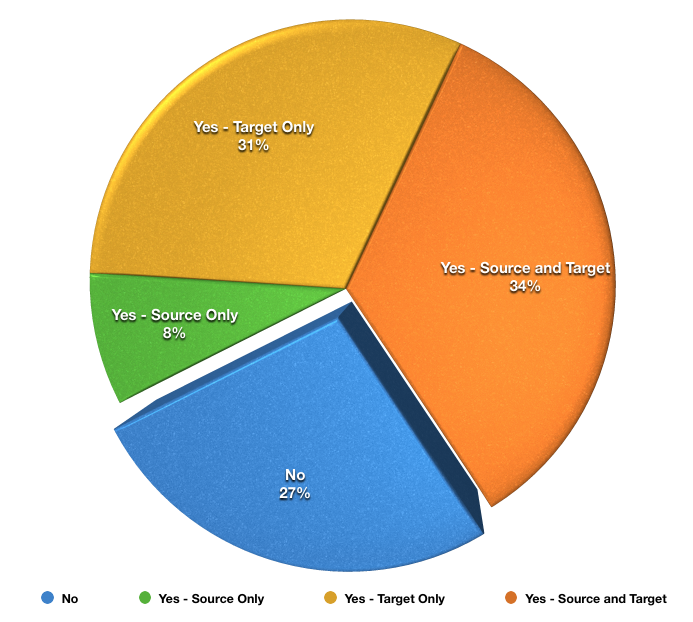
A whopping 63% of surveyed NetWorker users last year were making use of deduplication in some form or another. The No category has shrunk substantially even from 2012, where it was 37%. Deduplication is undoubtedly a technology that is well and truly in the middle of the product adoption bell curve.
So if you’re not using deduplication yet, the chances are it’ll be something you need to consider on your next technology refresh, unless you’re one of those exceptionally small sites or your overall data is of a type that doesn’t lend itself to deduplication.
The best way to see what deduplication might achieve for you in terms of storage capacity is to get it running within your environment, and thankfully, that’s now achievable thanks to the general reliability of SDFS. If you’re not aware of SDFS, it’s the keystone product from Opendedup, an open source Linux project. Since I first looked at it a couple of years ago, the product has matured considerably.
My lab server consists of NetWorker 8.1.1.3 running on a virtual machine (Parallels) with CentOS 6.5, 64-bit, with SDFS 2.0.0-2 installed on top. SDFS offers a deduplicating filesystem via a FUSE (user level) mounted filesystem. Two cores have been allocated (3.5GHz Intel Core i7), as has 8GB of RAM. The RAM is critical – SDFS says 8GB is preferred, but having initially tried it on a physical machine with just 4GB of RAM in it, the results were awful. Consider 8GB of RAM to be mandatory in this instance.
For the purposes of testing, I created a 128GB filesystem which was to be the destination data for the deduplication filesystem, and under Parallels (similar scenario for VMware), I provisioned the disk as a fully expanded file, so that data growth within the virtual machine wouldn’t trigger expansion processes in Parallels.
The 128GB filesystem was created as ext4, mounted in /filesys, and on that filesystem I created a directory called ‘ddfs’.
The command to create the deduplication filesystem was:
# mkfs.sdfs --base-path /filesys/ddfs --volume-capacity 120GB --volume-name backup00 --hash-type VARIABLE_MURMUR3
That created a 120GB deduplication filesystem (i.e., maximum size it would use from the host storage is 120GB) named ‘backup00’ and, via the hash-type instruction, using variable block size deduplication algorithms.
I then created a new directory mount point area, /dedupe, and mounted the filesystem there:
# mount.sdfs backup00 /dedupe
Note that the SDFS mount operation doesn’t actually exit, so that has to be run in another terminal session.
After that, I created a single ADV_FILE device in NetWorker called ‘SDFS’, pointing to /dedupe as the device access information/path, and I was ready to start the backup testing.
I started with doing full backups of the root filesystem of two Linux clients, one with 4GB of used capacity and the other with 4.1GB capacity, and ran a series of full backups, one after the other.
First full backup
Filesystem Size Used Avail Use% Mounted on sdfs:/etc/sdfs/backup00-volume-cfg.xml:6442 121G 5.0G 116G 5% /dedupe
Second full backup
Filesystem Size Used Avail Use% Mounted on sdfs:/etc/sdfs/backup00-volume-cfg.xml:6442 121G 6.4G 114G 6% /dedupe
Third full backup
Filesystem Size Used Avail Use% Mounted on sdfs:/etc/sdfs/backup00-volume-cfg.xml:6442 121G 5.7G 115G 5% /dedupe
Fourth full backup
Filesystem Size Used Avail Use% Mounted on sdfs:/etc/sdfs/backup00-volume-cfg.xml:6442 121G 6.5G 114G 6% /dedupe
Fifth full backup
Filesystem Size Used Avail Use% Mounted on sdfs:/etc/sdfs/backup00-volume-cfg.xml:6442 121G 7.2G 113G 6% /dedupe
Sixth full backup
Filesystem Size Used Avail Use% Mounted on
sdfs:/etc/sdfs/backup00-volume-cfg.xml:6442
121G 8.0G 113G 7% /dedupe
Seventh full backup
Filesystem Size Used Avail Use% Mounted on
sdfs:/etc/sdfs/backup00-volume-cfg.xml:6442
121G 9.0G 112G 8% /dedupe
At this point, I decided to fold in the root filesystems from four other Linux hosts, test03, test04, test05 and test06, with each of them having a used capacity of 3.5GB, 3.5GB, 3.5GB and 3.4GB respectively.
After a new full backup of everything, including test01 and test02, the deduplication filesystem stood at:
Filesystem Size Used Avail Use% Mounted on
sdfs:/etc/sdfs/backup00-volume-cfg.xml:6442
121G 13G 108G 11% /dedupe
From a NetWorker perspective, it was quite a different story:
[root@sdfs ~]# mminfo -mv | grep SDFS SDFS.001 74 GB 100% 25/05/15 0 KB 0 0 KB 8388349 0 adv_file
So that was 74GB of backed up data, deduplicated down to 13GB of used capacity.
Write performance was variable, depending on what data was being streamed at any moment (as you’d expect in any backup-to-disk scenario), and it’s obviously the case that the better configured your deduplication appliance, the better performance you’ll get – particularly given the entire process is being handled by Java. That said, here’s some actual screen shots:
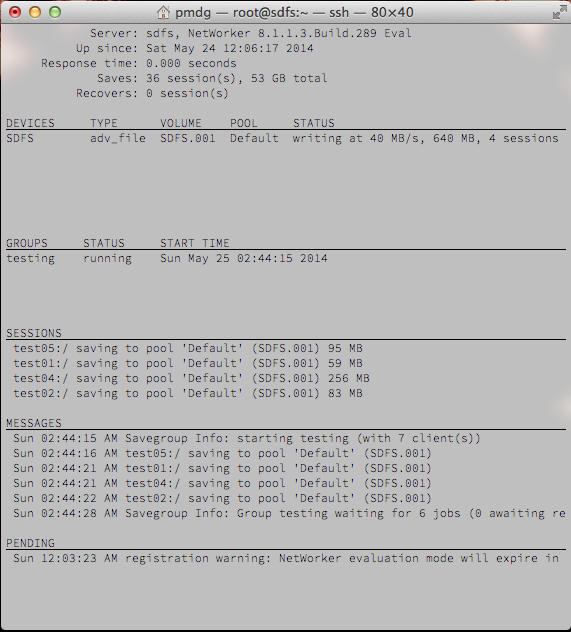
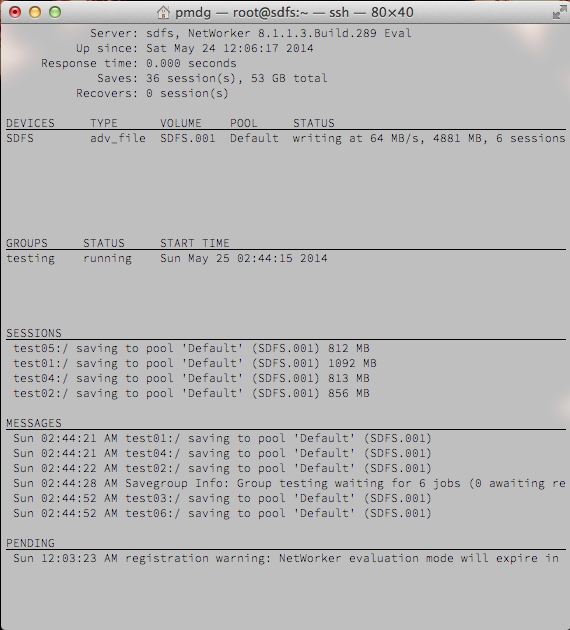
I would be remiss if I didn’t show an example of what performance could occasionally drop to, though I’ll equally note that normally the ‘poor’ performance figures were at more around the 2000-5000KB/s mark:
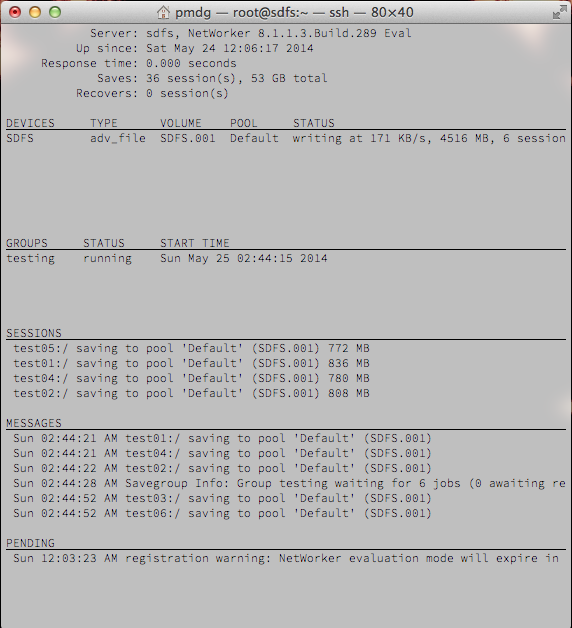
(Of course, that’s not ideal, but I’d not be recommending use of SDFS as an example of deduplication results with NetWorker if that was a consistent exemplar of the performance I encountered.)
To continue testing, I then added a Windows 2008 R2 system to the mix. It had approximately 18.6GB of used capacity on a single C:\ drive, and a full NetWorker backup of it comprised of:
- 14GB C:\
- 14KB DISASTER RECOVERY:\
- 4771KB WINDOWS ROLES AND FEATURES:\
This increased the deduplication filesystem to 19GB used (from 13GB previous), and the volume used capacity in NetWorker to 89GB. One last full backup of the Windows client yielded 105GB in total written to the backup volume, with a total of 22GB used on the actual deduplication filesystem.
At the conclusion of my basic lab tests, SDFS was yielding a deduplication ratio of around 4.7x – certainly nothing to be sneezed at.
More importantly though, if I were the backup or IT manager for a business looking at refreshing my environment, I’d already be seeing that deduplication is something to seriously consider, and that’s just with a series of straight forward filesystem tests run over a period of 24 hours. Comprehensive testing will take more time, but is not difficult to achieve – spin up a few additional production filesystem snapshots, mount them on an appropriate host, then back them up to an SDFS-Enabled Linux NetWorker server. In this scenario, the effects of daily delta change on deduplication capacity via incrementals can be simulated by doing a daily refresh of the snapshot mount.
More importantly though, this can be used to effectively determine the cumulative deduplication ratios that can be achieved against your own data. One of the key selling points of deduplication, after all, is that it allows you to keep more of your backups online for a longer period of time – instead of having a hard limit that is approached linearly with the amount of data you’re backing up, deduplication storage will absorb repeated backup data like Tatalus would have absorbed water had he ever been able to reach it.
Particularly when you consider Data Domain, SDFS only gives you a partial picture. The extreme levels of integration with cloning, synthetic fulls and virtual machine backups, as well as source-based deduplication via Boost-enabled clients makes a lab server running SDFS seem entirely primitive – but in itself that’s a good lesson: if you can achieve that using a free, easy to construct deduplication appliance, imagine what you’re going to get out of a well-integrated piece of equipment that does its best to avoid rehydrating your data until you absolutely need it rehydrated.
If you’re still on the fence about deduplication, or even resolutely staring away from it, spinning up a Linux NetWorker server with SDFS enabled in your lab may give you a big eye opening experience on what deduplication could offer your business.
[Addendum – 7 April 2015]
Reinforcing my insistence above that SDFS should only be used for lab testing with NetWorker, I’d actually suggest it isn’t production ready in any way. I had a lab server running SDFS a while ago and noticed a few oddities in cloning which lead me to dive deep into SDFS logs to note that it would occasionally hit a scenario where it couldn’t actually write or dedupe content, and instead of actually generating a write error, would instead just write gibberish to the filename nominated by the process trying to write. That’s totally unacceptable. So please, please make sure if you run up SDFS for deduplication testing it’s only for deduplication testing and not for anything serious!
But if i would use suche a free solution, i still had to license the used Disk Capacity right ?
You’d need a disk capacity license for the amount of backups NetWorker writes (i.e., what the rehydrated amount is).
I would not advocate using SDFS in a production environment – simply its use in a lab environment (where you would install NetWorker in eval mode and not need licenses) to confirm the suitability of deduplication in your production environment. For production level dedupe, I’d still be recommending fully supported and well integrated products, such as Data Domain.