A while ago, I gave away a utility I find quite handy in lab and testing situations called genbf. If you’ll recall, it can be used to generate large files which are not susceptible to compression or deduplication. (You can find that utility here.)
At the time I mentioned another utility I use called generate-filesystem. While genbf is designed to produce potentially very large files that don’t yield to compression, generate-filesystem (or genfs2 as I’m now calling it) is designed to create a random filesystem for you. It’s not the same of course as taking say, a snapshot copy of your production fileserver, but if you’re wanting a completely isolated lab and some random content to do performance testing against, it’ll do the trick nicely. In fact, I’ve used it (or predecessors of it) multiple times when I’ve blogged about block based backups, filesystem density and parallel save streams.

Overall it produces files that don’t yield all that much to compression. A 26GB directory structure with 50,000 files created with it compressed down to just 25GB in a test I ran a short while ago. That’s where genfs2 comes in handy – you can create really dense test filesystems with almost no effort on your part. (Yes, 50,000 files isn’t necessarily dense, but that was just a small run.)
It is however random by default on how many files it creates, and unless you give it an actual filesystem count limit, it can easily fill a filesystem if you let it run wild. You see, rather than having fixed limits for files and directories at each directory level, it works with upper and lower bounds (which you can override) and chooses a random number at each time. It even randomly chooses how many directories it nests down based on upper/lower limits that you can override as well.
Here’s what the usage information for it looks like:
$ ./genfs2.pl -h
Syntax: genfs2.pl [-d minDir] [-D maxDir] [-f minFile] [-F maxFile] [-r minRecurse] [-R maxRecurse] -t target [-s minSize] [-S maxSize] [-l minLength] [-L maxLength] [-C] [-P dCsize] [-T mfc] [-q] [-I]
Creates a randomly populated directory structure for backup/recovery
and general performance testing. Files created are typically non-
compressible.
All options other than target are optional. Values in parantheses beside
explanations denote defaults that are used if not supplied.
Where:
-d minDir Minimum number of directories per layer. (5)
-D maxDir Maximum number of directories per layer. (10)
-f minFile Minimum number of files per layer. (5)
-F maxFile Maximum number of files per layer. (10)
-r minRecurse Minimum recursion depth for base directories. (5)
-R maxRecurse Maximum recursion depth for base directories. (10)
-t target Target where directories are to start being created.
Target must already exist. This option MUST be supplied.
-s minSize Minimum file size (in bytes). (1 K)
-S maxSize Maximum file size (in bytes). (1 MB)
-l minLength Minimum filename/dirname length. (5)
-L maxLength Maximum filename/dirname length. (15)
-P dCsize Pre-generate random data-chunk at least dcSize bytes.
Will default to 52428800 bytes.
-C Try to provide compressible files.
-I Use lorem ipsum filenames.
-T mfc Specify maximum number of files that will be created.
Does not include directories in count.
-q Quiet mode. Only print updates to the file-count.
E.g.:
./genfs2.pl -r 2 -R 32 -s 512 -S 65536 -t /d/06/test
Would generate a random filesystem starting in /d/06/test, with a minimum
recursion depth of 2 and a maximum recursion depth of 32, with a minimum
filesize of 512 bytes and a maximum filesize of 64K.
Areas where this utility can be useful include:
- …filling a filesystem with something other than /dev/zero
- …testing anything to do with dense filesystems without needing huge storage space
- …doing performance comparisons between block based backup and regular backups
- …doing performance comparisons between parallel save streams and regular backups
This is one of those sorts of utilities I wrote once over a decade ago and have just done minor tweaks on it here and there since then. There’s probably a heap of areas where it’s not optimal, but it’s done the trick, and it’s done it relatively fast enough for me. (In other words: don’t judge my programming skills based on the code – I’ve never been tempted to optimise it.) For instance, on a Mac Book Pro 13″ writing to a 2TB LaCie Rugged external via Thunderbolt, the following command takes 6 minutes to complete:
$ ./genfs2.pl -T 50000 -t /Volumes/Storage/FSTest -d 5 -D 15 -f 10 -F 30 -q -I
Progress:
Pre-generating random data chunk. (This may take a while.)
Generating files. Standby.
--- 100 files
--- 200 files
--- 300 files
...
--- 49700 files
--- 49800 files
--- 49900 files
--- 50000 files
Hit maximum file count (50000).
I don’t mind waiting 6 minutes for 50,000 files occupying 26GB. If you’re wondering what the root directory from this construction looks like, it goes something like this:
$ ls /Volumes/Storage/FSTest/ at-eleifend/ egestas elit nisl.dat eget.tbz2 facilisis morbi rhoncus.7r interdum lacinia-in-rhoncus aliquet varius-nullam-a/ lobortis mi-malesuada aenean/ mi mi netus-habitant-tortor-interdum rhoncus.mov mi-neque libero risus-euismod ante.gba non-purus-varius ac.dat quis-tortor-enim-sed-lorem pellentesque pellentesque/ sapien-in auctor-libero.anr tincidunt-adipiscing-eleifend.xlm ut.xls
Looking at the file/directory breakdown on GrandPerspective, you’ll see it’s reasonably evenly scattered:
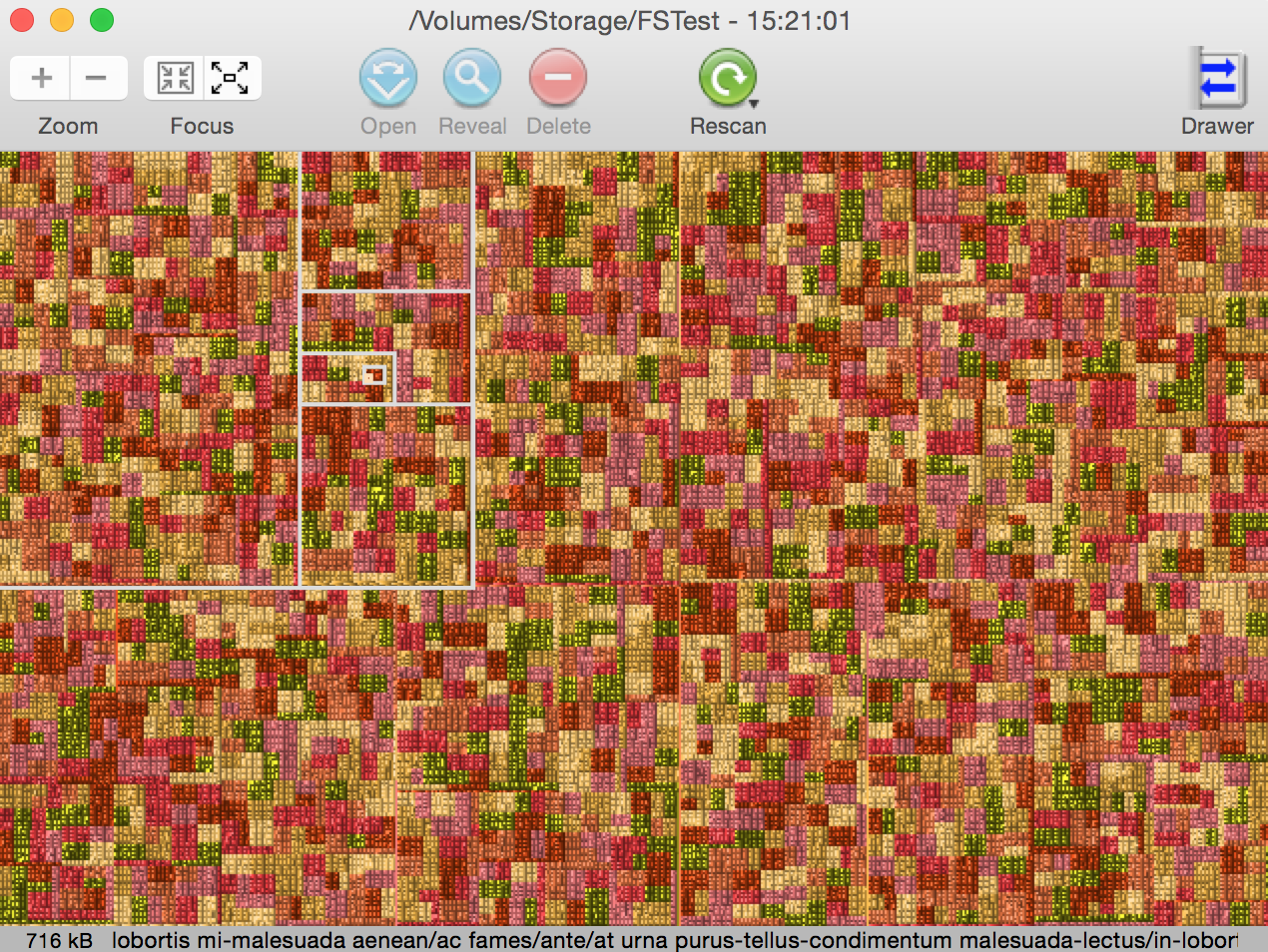
Since genfs2 doesn’t do anything with the directory you give it other than add random files to it, you can run it multiple times with different parameters – for instance, you might give an initial run to create 1,000,000 small files, then if you’re wanting a mix of small and large files, execute it a few more times to give yourself some much larger random files distributed throughout the directory structure as well.
Now here’s the caution: do not, definitely do not run this on one of your production filesystems, or any filesystem where running out of space might cause a data loss or access failure.
If you’re wanting to give it a spin or make use of it, you can freely download it from here.
Hi Preston
If you ever need a similar funtion in a Windows environment, then visit Bingo’s homepage here: http://avus-cr.de/utilities_en.html
Best regards and congrats with your new job
Ole
Hi Ole,
Thanks! The script should run on Windows with ActiveState installed – though I haven’t run it there for a few years.
Cheers,
Preston