I’ve been working with backups for 20 years, and if there’s been one constant in 20 years I’d say that application owners (i.e., DBAs) have traditionally been reluctant to have other people (i.e., backup administrators) in control of the backup process for their databases. This leads to some environments where the DBAs maintain control of their backups, and others where the backup administrators maintain control of the database backups.

So the question that many people end up asking is: which way is the right way? The answer, in reality is a little fuzzy, or, it depends.
When we were primarily backing up to tape, there was a strong argument for backup administrators to be in control of the process. Tape drives were a rare commodity needing to be used by a plethora of systems in a backup environment, and with big demands placed on them. The sensible approach was to fold all database backups into a common backup scheduling system so resources could be apportioned efficiently and fairly.
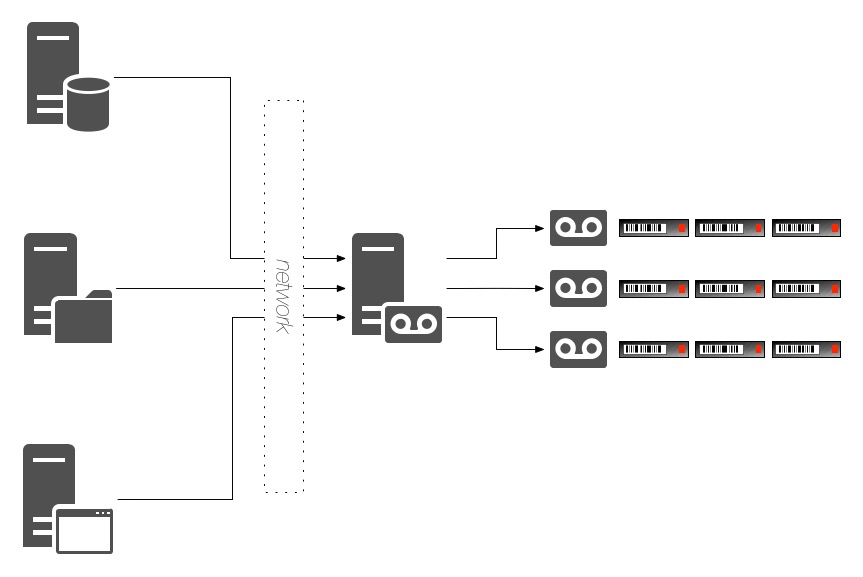
With limited tape resources and a variety of systems to protect, backup administrators needed to exert reasonably strong controls over what backed up when, and so in a number of organisations it was common to have database backups controlled within the backup product (e.g., NetWorker), with scheduling negotiated between the backup and database administrators. Where such processes have been established, they often continue – backups are, of course, a reasonably habitual process (and for good cause).
For some businesses though, DBAs might feel there was not enough control over the backup process – which might be agreed with based on the mission criticality of the applications running on top of the database, or because of the perceived licensing costs associated with using a plugin or module from the backup product to backup the database. So in these situations if a tape library or drives weren’t allocated directly to the database, the “dump and sweep” approach became quite common, viz.:
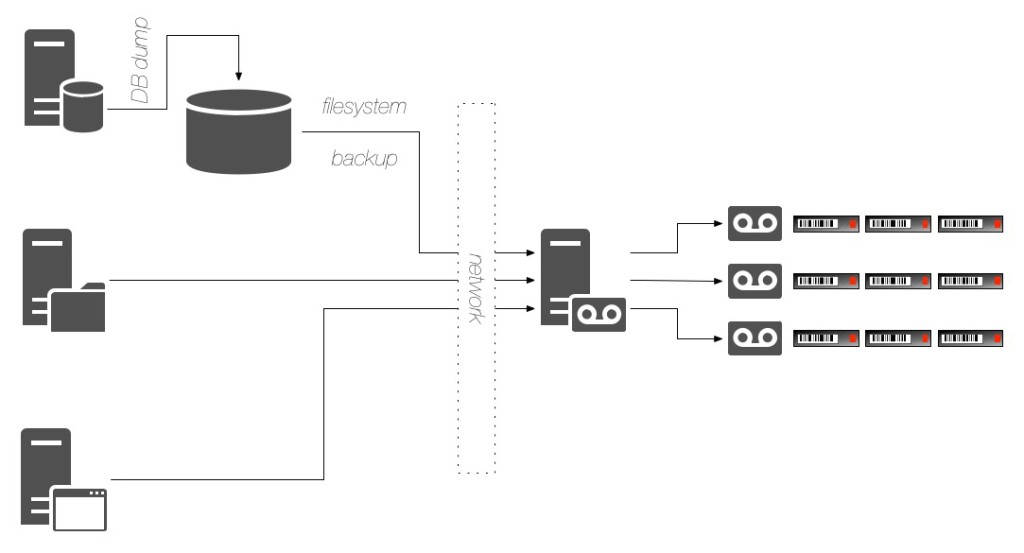
One of the most pervasive results of the “dump and sweep” methodology however is the amount of primary storage it uses. Due to it being much faster than tape, database administrators would often get significantly larger areas of storage – particularly as storage became cheaper – to conduct their dumps to. Instead of one or two days, it became increasingly common to have anywhere from 3-5 days of database dumps sitting on primary storage being swept up nightly by a filesystem backup agent.
Dump and sweep of course poses problems: in addition to needing large amounts of primary storage, the first backup for the database is on-platform – there’s no physical separation. That means the timing of getting the database backup completed before the filesystem sweep starts is critical. However, the timing for the dump is controlled by the DBA and dependent on the database load and the size of the database, whereas the timing of the filesystem backup is controlled by the backup administrator. This would see many environments spring up where over time the database grew to a size it wouldn’t get an off-platform backup for 24 hours – until the next filesystem backup happened. (E.g., a dump originally taking an hour to complete would be started at 19:00. The backup administrators would start the filesystem backup at 20:30, but over time the database backups would grow and wouldn’t complete until say, 21:00. Net result could be a partial or failed backup of the dump files the first night, with the second night being the first successful backup of the dump.)
Over time backup to disk entered popularity to overcome the overnight operational challenges of tape, then grew, and eventually the market has expanded to include deduplication storage, purpose built backup appliances and even when I’d normally consider to be integrated data protection appliances – ones where the intelligence (e.g., deduplication functionality) is extended out from the appliance to the individual systems being protected. That’s what we get, for instance, with Data Domain: the Boost functionality embedded in APIs on the client systems leveraging distributed segment processing to have everything being backed up participate in its own deduplication. The net result is one that scales better than the traditional 3-tier “client/server/{media server|storage node}” environment, because we’re scaling where it matters: out at the hosts being protected and up at protection storage, rather than adding a series of servers in the middle to manage bottlenecks. (I.e., we remove the bottlenecks.)
Even as large percentages of businesses switched to deduplicated storage – Data Domains mostly from a NetWorker perspective – and had the capability of leveraging distributed deduplication processes to speed up the backups, that legacy “dump and sweep” approach, if it had been in the business, often remained in the business.
We’re far enough into this now that I can revisit the two key schools of thought within data protection:
- Backup administrators should schedule and control backups regardless of the application being backed up
- Subject Matter Experts (SMEs) should have some control over their application backup process because they usually deeply understand how the business functions leveraging the application work
I’d suggest that the smaller the business, the more correct the first option is – or rather, when an environment is such that DBAs are contracted or outsourced in particular, having the backup administrator in charge of the backup process is probably more important to the business. But that creates a requirement for the backup administrator to know the ins and outs of backing up and recovering the application/database almost as deeply as a DBA themselves.
As businesses grow in size and as the number of mission critical systems sitting on top of databases/applications grow, there’s equally a strong opinion the second argument is correct: the SMEs need to be intimately involved in the backup and recovery process. Perhaps even more so, in a larger backup environment, you don’t want your backup administrators to actually be bottlenecks in a disaster situation (and they’d usually agree to this as well – it’s too stressful).
With centralised disk based protection storage – particularly deduplicating protection storage – we can actually get the best of both worlds now though. The backup administrators can be in control of the protection storage and set broad guidance on data protection at an architectural and policy level for much of the environment, but the DBAs can leverage that same protection storage and fold their backups into the overall requirements of their application. (This might be to even leverage third party job control systems to only trigger backups once batch jobs or data warehousing tasks have completed.)
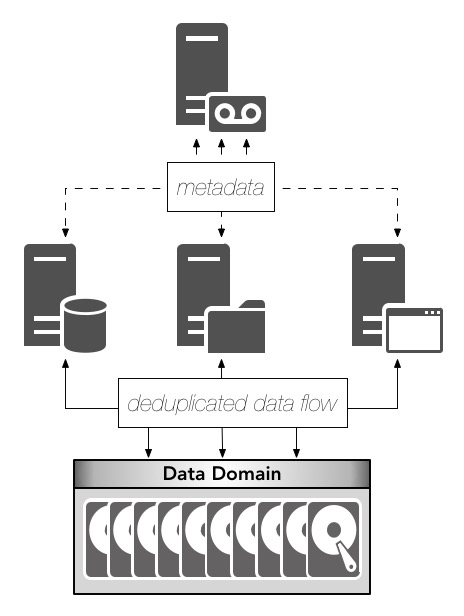
That particular flow is great for businesses that have maintained centralised control over the backup process of databases and applications, but what about those where dump and sweep has been the design principle, and there’s a desire to keep a strong form of independence on the backup process, or where the overriding business goal is to absolutely limit the number of systems database administrators need to learn so they can focus on their job? They’re definitely legitimate approaches – particularly so in larger environments with more mission critical systems.
That’s why there’s the Data Domain Boost plugins for Applications and Databases – covering SAP, DB2, Oracle, SQL Server, etc. That gives a slightly different architecture, viz.:
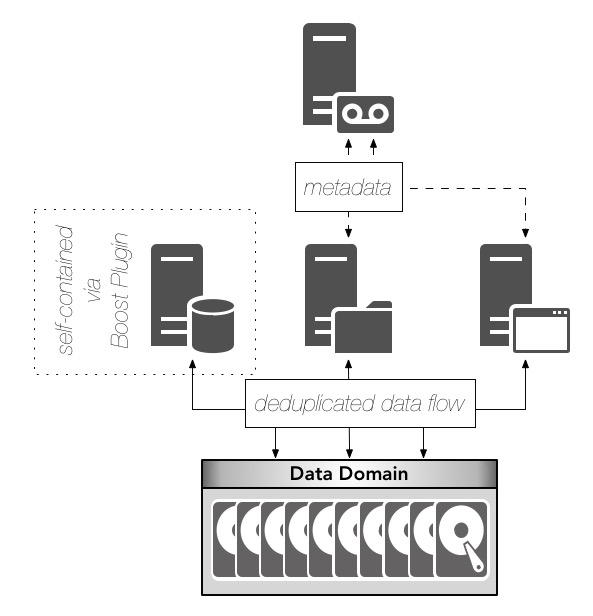
In that model, the backup server (e.g., NetWorker) still controls and coordinates the majority of the backups in the environment, but the Boost Plugin for Databases/Applications is used on the database servers instead to allow complete integration between the DBA tools and the backup process.
So returning to the initial question – which way is right?
Well, that comes down to the real question: which way is right for your business? Pull any emotion or personal preferences out of the question and look at the real architectural requirements of the business, particularly relating to mission critical applications. Which way is the right way? Only your business can decide.
Here’s a thought I’ll leave you with though: there’s two critical components to being able to make the choice completely based on business requirements:
- You need centralised protection storage where there aren’t the traditional (tape-inherited) limitations on concurrent device access
- You need a data protection framework approach rather than a data protection monolith approach
The former allows you to make decisions without being impeded by arbitrary practical/physical limitations (e.g., “I can’t read from a tape and write to it at the same time”), and more importantly, the latter lets you build an adaptive data protection strategy using best of breed components at the different layers rather than squeezing everything into one box and making compromises at every step of the way. (NetWorker, as I’ve mentioned before, is a framework based backup product – but I’m talking more broadly here: framework based data protection environments.)
Happy choosing!
One more dimension: segregation of duties. Nobody wants data loss or corruption as this could take a company down; you can’t just reinstall a database as you would with an application server; and failure is a certainty in any complex system. Sooner or later something will crash leading to data loss or corruption of all database instances. Sometimes, this can be caused by an malicious/incompetent/tired DBA, sysadmin or storage admin; and in this case you MUST have a working backup from which you can restore.
Every enterprise has it’s own level of paranoid behavior dictating what level of protection they desire to prevent one individual to significantly affect the business. Depending on this dose, some just trust the DBA that he/she is taking appropriate measures to protect from failures, this is their job after-all :-); Others might request reports from the DBA showing that there is a periodic backup scheduled and is running successfully; some might enforce having somebody else from the DBA controlling the backup schedule to protect from the DBA, and different persons as backup administrators and primary storage administrators; some might even require another admin (DBA/backup) run periodic restore tests to ensure data integrity. And I’m sure in some environments they thought about even more controls than the above 🙂
Personally, witnessing backup (actually restore) failure on a high importance system, I prefer to have a backup admin in charge of controlling the schedule and making sure it is running, and the DBA testing the restore periodically and checking the backup system is setup according to the SLA.
And actually, the first time I heard about DD Boost, was from our EMC Backup presale telling me specifically about every Oracle DBAs desire to make sure the backup is working because it’s their job in the end to get the database in some working order and how this can help. Since DD Boost is line speed, you can just setup the Networker job according to the SLA, controlled by the backup admin; and the Oracle DBA can setup how many jobs he want via RMAN DD Boost, and it will have minimum impact on the DataDomain since it will deduplicate everything, so: everybody happy; the backup admin has control of all backup environment, and the DBA has the peace of mind of having exactly how many “copies” he desires.
Dragos, these are good points, but not every business feels the same way. Some businesses very much want or need (from an operational perspective) the DBAs to be in charge of the backups due to the complexity of starting them based on other workloads and primary activity processing completing. In the end though having the choice to do both types of actions is the important option.