Introduction
There’s something slightly deceptive about the title for my blog post. Did you spot it?
It’s: vs. It’s a common mistake to think that Cloud Boost and Cloud Tier compete with one another. That’s like suggesting a Winnebago and a hatchback compete with each other. Yes, they both can have one or more people riding in them and they can both be used to get you around, but the actual purpose of each is typically quite different.
It’s the same story when you look at Cloud Boost and Cloud Tier. Of course, both can move data from A to B. But the reason behind each, the purpose for each is quite different. (Does that mean there’s no overlap? Not necessarily. If you need to go on a 500km holiday and sleep in the car, you can do that in a hatchback or a Winnebago, too. You can often get X to do Y even if it wasn’t built with that in mind.)
So let’s examine them, and look at their workflows as well as a few usage examples.
Cloud Boost
First off, let’s consider Cloud Boost. Version 1 was released in 2014, and since then development has continued to the point where CloudBoost now looks like the following:
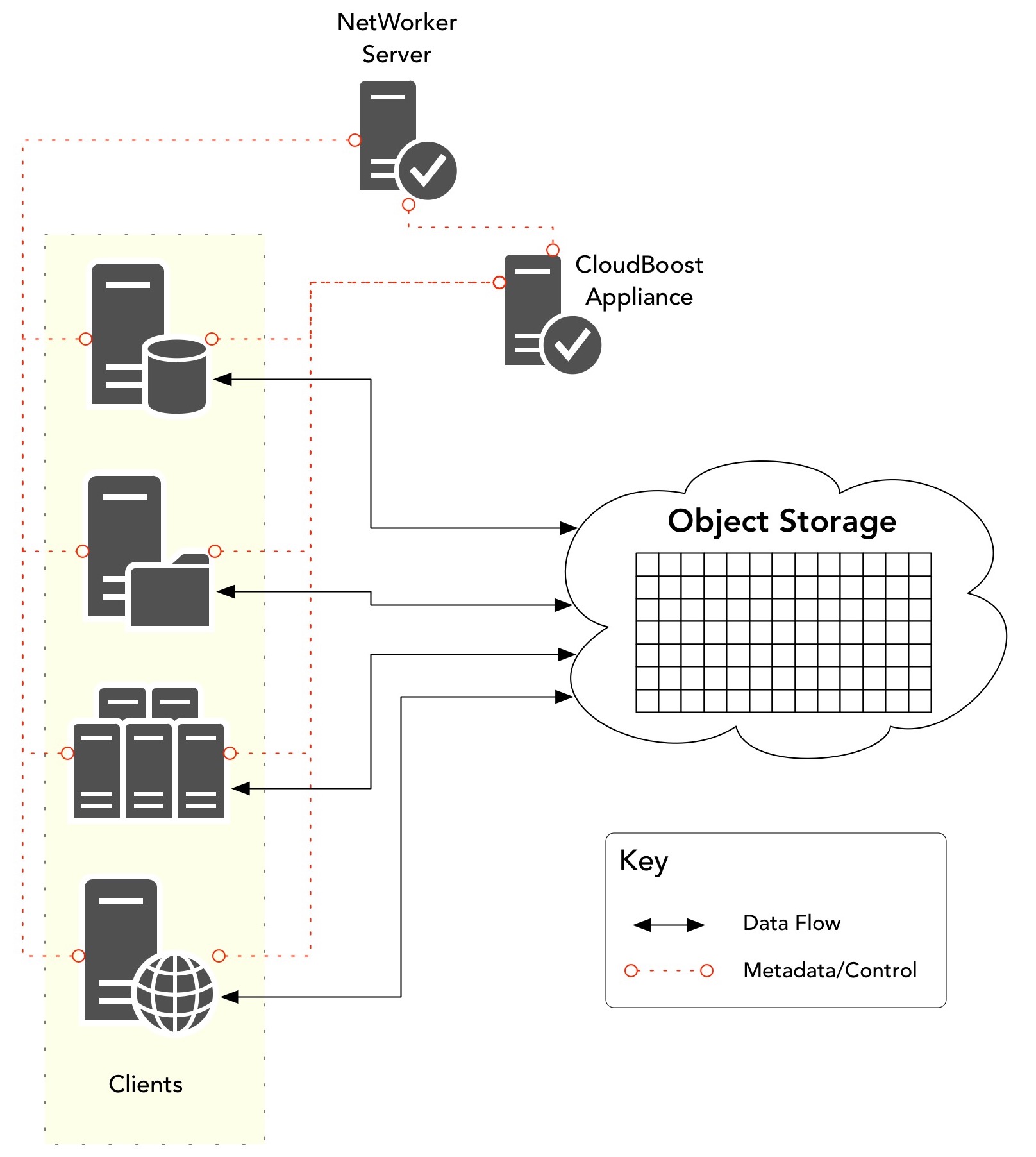
Cloud Boost exists to allow NetWorker (or NetBackup or Avamar) to write deduplicated data out to cloud object storage, regardless of whether that’s on-premises* in something like ECS, or writing out to a public cloud’s object storage system, like Virtustream Storage or Amazon S3. When Cloud Boost was first introduced back in 2014, the Cloud Boost appliance was also a storage node and data had to be cloned from another device to the Cloud Boost storage node, which would push data out to object. Fast forward a couple of years, and with Cloud Boost 2.1 introduced in the second half of 2016, we’re now at the point where there’s a Cloud Boost API sitting in NetWorker clients allowing full distributed data processing, with each client talking directly to the object storage – the Cloud Boost appliance now just facilitates the connection.
In the Cloud Boost model, regardless of whether we’re backing up in a local datacentre and pushing to object, or whether all the systems involved in the backup process are sitting in public cloud, the actual backup data never lands on conventional block storage – after it is deduplicated, compressed and encrypted it lands first and only in object storage.
Cloud Tier
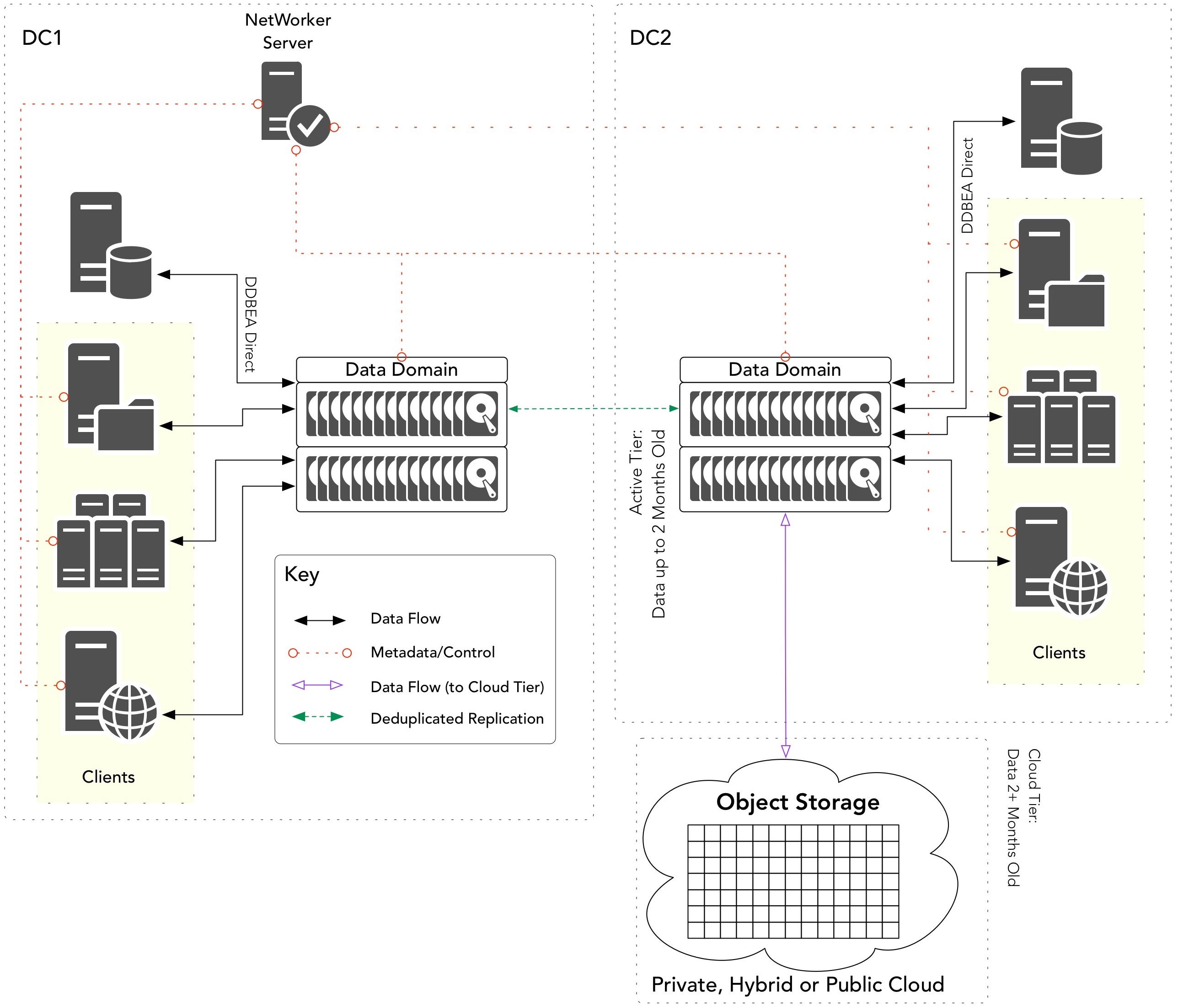
Cloud Tier is new functionality released in the Data Domain product range – it became available with Data Domain OS v6, released in the second half of 2016. The workflow for Cloud Tier looks like the following:
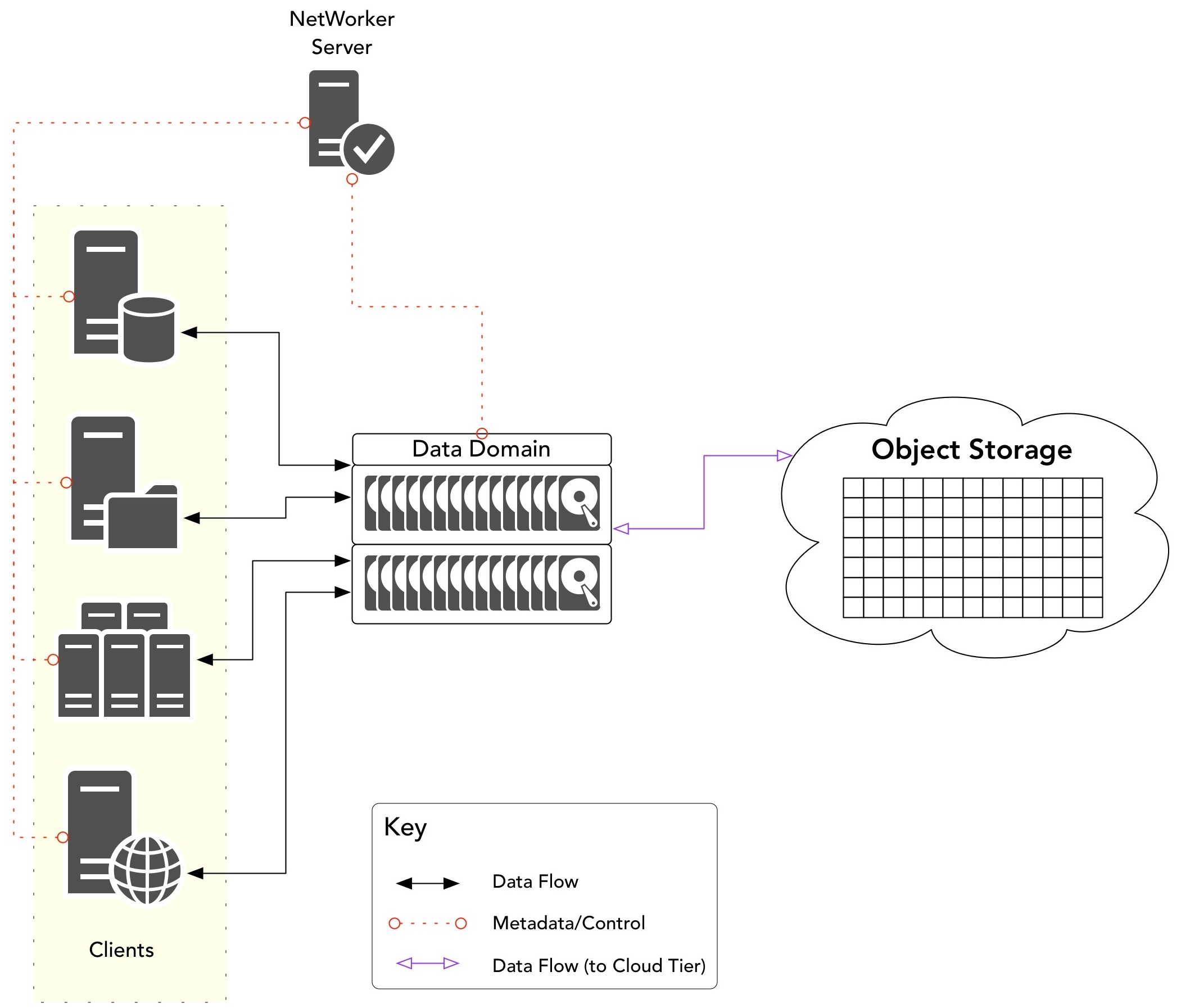
Data migration with Cloud Tier is handled as a function of the Data Domain operating system (or controlled by a fully integrated application such as NetWorker or Avamar); the general policy process is that once data has reached a certain age on the Active Tier of the Data Domain, it is migrated to the Cloud Tier without any need for administrator or user involvement.
The key for the differences – and the different use cases – between Cloud Boost and Cloud Tier is in the above sentence: “once data has reached a certain age on the Active Tier”. In this we’re reminded of the primary use case for Cloud Tier – supporting Long Term Retention (LTR) in a highly economical format and bypassing any need for tape within an environment. (Of course, the other easy differentiator is that Cloud Tier is a Data Domain feature – depending on your environment that may form part of the decision process.)
Example use cases
To get a feel for the differences in where you might deploy Cloud Boost or Cloud Tier, I’ve drawn up a few use cases below.
Cloning to Cloud
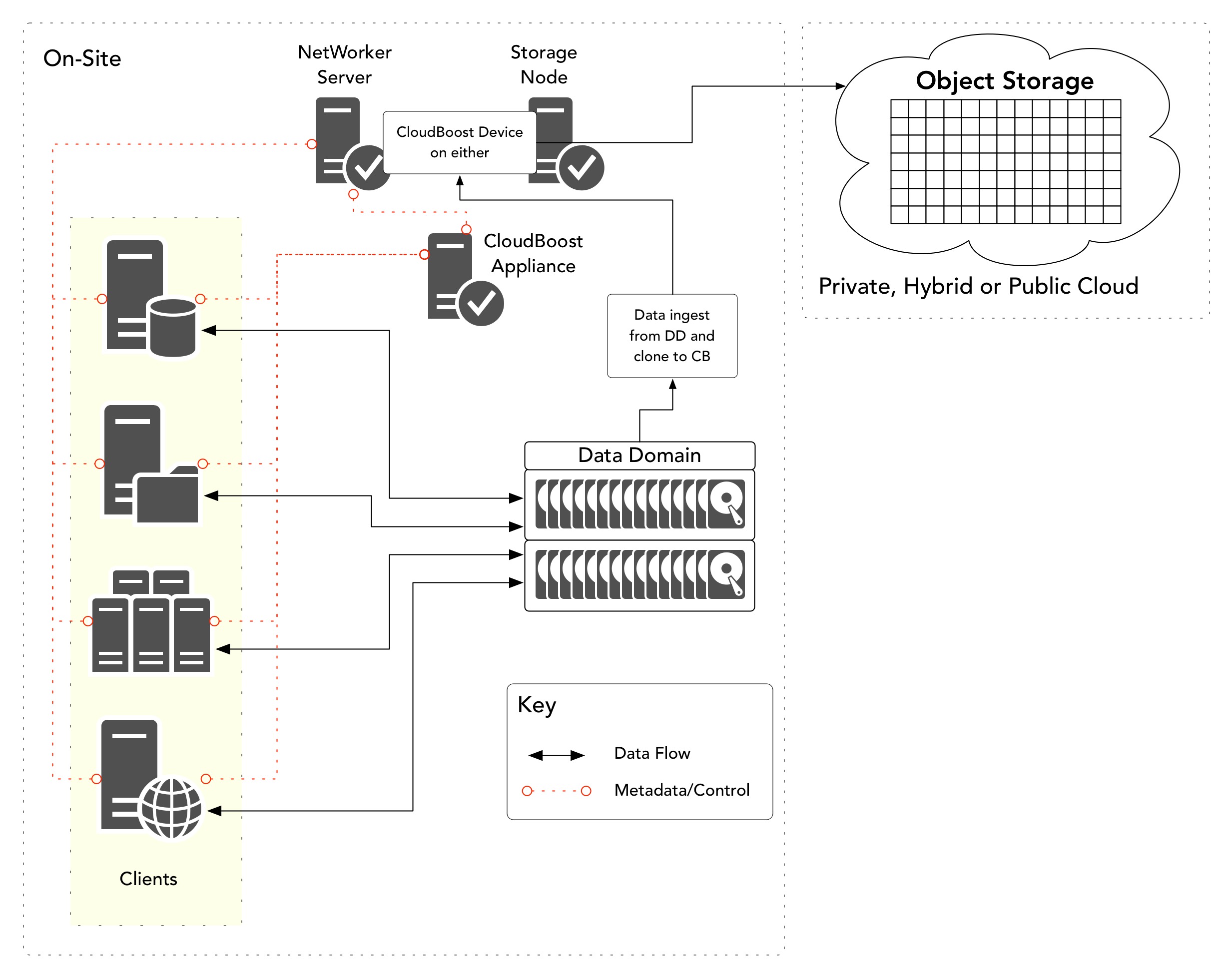
You currently backup to disk (Data Domain or AFTD) within your environment, and have been cloning to tape. You want to ensure you’ve got a second copy of your data, and you want to keep that data off-site. Instead of using tape, you want to use Cloud object storage.
In this scenario, you might look at replacing your tape library with a Cloud Boost system instead. You’d backup to your local protection storage, then when it’s time to generate your secondary copy, you’d clone to your Cloud Boost device which would push the data (compressed, deduplicated and encrypted) up into object storage. At a high level, that might result in a workflow such as the following:
Backing up to the Cloud
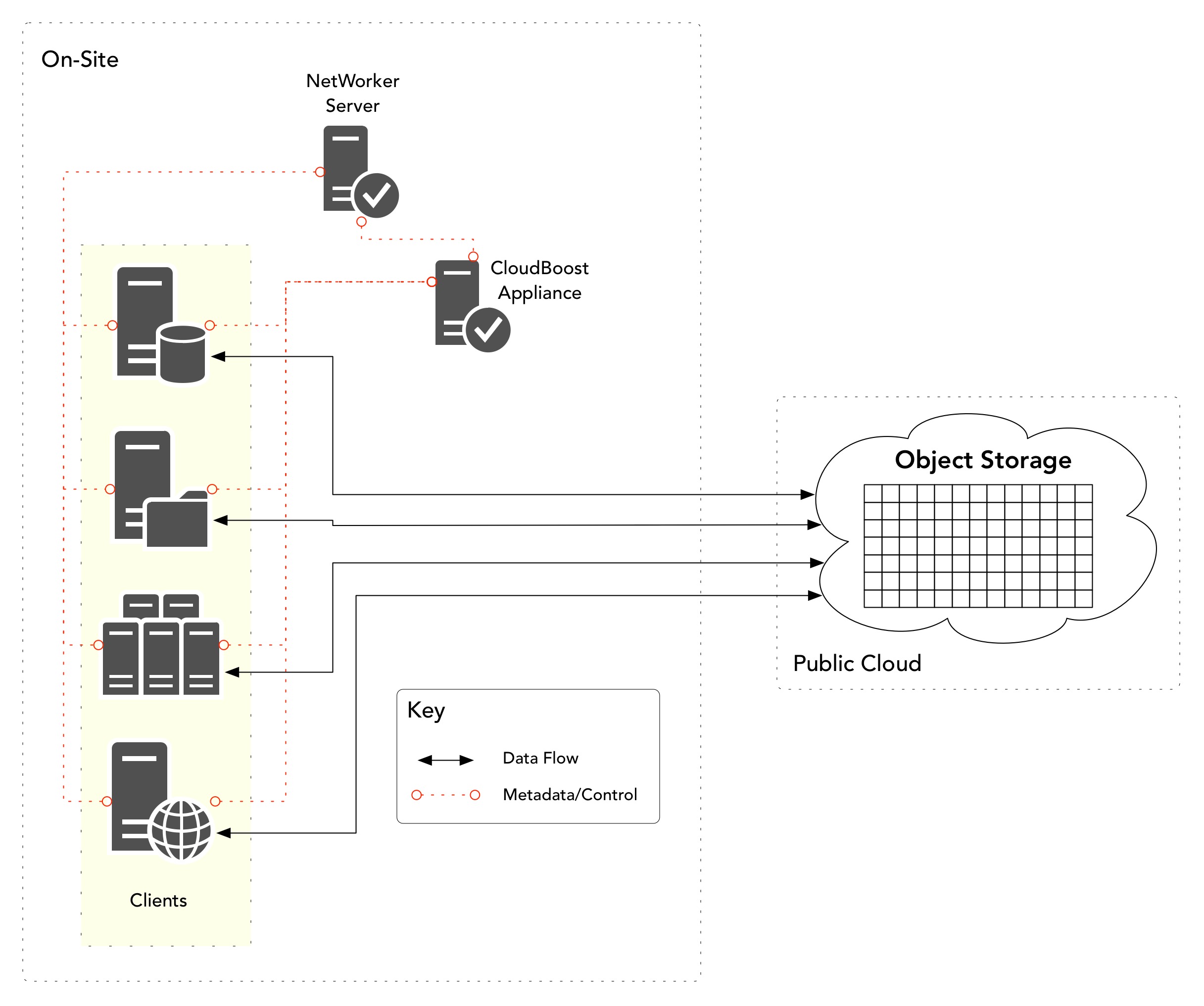
You’re currently backing up locally within your datacentre, but you want to remove all local backup targets. In this scenario, you might replace your local backup storage with a Cloud Boost appliance, connected to an object store, and backup via Cloud Boost (via client direct), landing data immediately off-premises and into object storage at a cloud provider (public or hosted).
At a high level, the workflow for this resembles the following:
Backing up in Cloud
You’ve got some IaaS systems sitting in the Cloud already. File, web and database servers sitting in say, Amazon, and you need to ensure you can protect the data they’re hosting. You want greater control than say, Amazon snapshots, and since you’re using a NetWorker Capacity license or a DPS capacity license, you know you can just spin up another NetWorker server without an issue – sitting in the cloud itself.
In that case, you’d spin up not only the NetWorker server but a Cloud Boost appliance as well – after all, Amazon love NetWorker + Cloud Boost:
“The availability of Dell EMC NetWorker with CloudBoost on AWS is a particularly exciting announcement for all of the customers who have come to depend on Dell EMC solutions for data protection in their on-premises environments,” said Bill Vass, Vice President, Technology, Amazon Web Services, Inc. “Now these customers can get the same data protection experience on AWS, providing seamless operational backup and recovery, and long-term retention across all of their environments.”
That’ll deliver the NetWorker functionality you’ve come to use on a daily basis, but in the Cloud and writing directly to object storage.
The high level view of the backup workflow here is effectively the same as the original diagram used to introduce Cloud Boost.
Replacing Tape for Long Term Retention
You’ve got a Data Domain in each datacentre; the backups at each site go to the local Data Domain then using Clone Controlled Replication are copied to the other Data Domain as soon as each saveset finishes. You’d like to replace tape for your long term retention, but since you’re protecting a lot of data, you want to push data you rarely need to recover from (say, older than 2 months) out to object storage. When you do need to recover that data, you want to absolutely minimise the amount of data that needs to be retrieved from the Cloud.
This is a definite Cloud Tier solution. Cloud Tier can be used to automatically extend the Data Domain storage, providing a storage tier for long term retention data that’s very cheap and highly reliable. Cloud Tier can be configured to automatically migrate data older than 2 months out to object storage, and the great thing is, it can do it automatically for anything written to the Data Domain. So if you’ve got some databases using DDBoost for Enterprise Apps writing directly, you can setup migration policies for them, too. Best of all, when you do need to recall data from Cloud Tier, Boost for Enterprise Apps and NetWorker can handle that recall process automatically for you, and the Data Domain only ever recalls the delta between deduplicated data already sitting on the active tier and what’s out in the Cloud.
The high level view of the workflow for this use case will resemble the following:
…Actually, you hear there’s an Isilon being purchased and the storage team are thinking about using Cloud Pools to tier really old data out to object storage. Your team and the storage team get to talking and decide that by pooling the protection and storage budget, you get Isilon, Cloud Tier and ECS, providing oodles of cheap object storage on-site at a fraction of the cost of a public cloud, and with none of the egress costs or cloud vendor lock-in.
Wrapping Up
Cloud Tier and Cloud Boost are both able to push data into object storage, but they don’t have exactly the same use cases. There’s good, clear reasons why you would work with one in particular, and hopefully the explanation and examples above has helped to set the scene on their use cases.
—
* Note, ‘on-premise’ would mean ‘on my argument’. The correct term is ‘on-premises’ 🙂
Any hint when CloudBoost appliance for Azure may be available? As right now I would need to create CloudBoost appliance on premises to support cloud workloads on object storage in cloud when using Azure.
Hi Hrvoje,
The CloudBoost appliance for Azure should be available on support.emc.com. The 2.1 CloudBoost integration guide (updated Jan 2017) includes details for deploying a CloudBoost ARM.
Cheers,
Preston.
Yup, I just read updated 2.1 guide… thnx!
One more question. Why Linux is able to write onto block storage directly while Windows clients can’t do that? What is exactly holding them back from doing it?
Hi Hrvoje,
I can’t speak to the exact why – but Windows should be able to go direct this year.
Cheers,
Preston.
Thnx!