(Part 1).
Particularly when we think of IaaS style workloads in the Cloud, there’s two key approaches that can be used for data protection.
The first is snapshots. Snapshots fulfil part of a data protection strategy, but we do always need to remember with snapshots that:
- They’re an inefficient storage and retrieval model for long-term retention
- Cloud or not, they’re still essentially on-platform
As we know, and something I cover in my book quite a bit – a real data protection strategy will be multi-layered. Snapshots undoubtedly can provide options around meeting fast RTOs and minimal RPOs, but traditional backup systems will deliver a sufficient recovery granularity for protection copies stretching back weeks, months or years.
Stepping back from data protection itself – public cloud is a very different operating model to traditional in-datacentre infrastructure spending. The classic in-datacentre infrastructure procurement process is an up-front investment designed around 3- or 5-year depreciation schedules. For some businesses that may mean a literal up-front purchase to cover the entire time-frame (particularly so when infrastructure budget is only released for the initial deployment project), and for others with more fluid budget options, there’ll be an investment into infrastructure that can be expanded over the 3- or 5-year solution lifetime to meet systems growth.
Cloud – public Cloud – isn’t costed or sold that way. It’s a much smaller billing window and costing model; use a GB or RAM, pay for a GB of RAM. Use a GHz or CPU, pay for a GHz of CPU. Use a GB of storage, pay for a GB of storage. Public cloud costing models often remind me of Master of the House from Les Miserables, particularly this verse:
Charge ’em for the lice, extra for the mice
Two percent for looking in the mirror twice
Here a little slice, there a little cut
Three percent for sleeping with the window shut
When it comes to fixing prices
There are a lot of tricks I knows
How it all increases, all them bits and pieces
Jesus! It’s amazing how it grows!Master of the House, Les Miserables.
That’s the Cloud operating model in a nutshell. Minimal (or no) up-front investment, but you pay for every scintilla of resource you use – every day or month.
If you say, deploy a $30,000 server into your datacentre, you then get to use that as much or as little as you want, without any further costs beyond power and cooling*. With Cloud, you won’t be paying that $30,000 initial fee, but you will pay for every MHz, KB of RAM and byte of storage consumed within every billing period.
If you want Cloud to be cost-effective, you have to be able to optimise – you have to effectively game the system, so to speak. Your in-Cloud services have to be maximally streamlined. We’ve become inured to resource wastage in the datacentre because resources have been cheap for a long time. RAM size/speed grows, CPU speed grows, as does the number of cores, and storage – well, storage seems to have an infinite expansion capability. Who cares if what you’re doing generates 5 TB of logs per day? Information is money, after all.
To me, this is just the next step in the somewhat lost art of programmatic optimisation. I grew up in the days of 8-bit computing**, and we knew back then that CPU, RAM and storage weren’t infinite. This didn’t end with 8-bit computing, though. When I started in IT as a Unix system administrator, swap file sizing, layout and performance was something that formed a critical aspect of your overall configuration, because if – Jupiter forbid – your system started swapping, you needed a fighting chance that the swapping wasn’t going to kill your performance. Swap file optimisation was, to use a Bianca Del Rio line, all about the goal: “Not today, Satan.”
That’s Cloud, now. But we’re not so much talking about swap files as we are resource consumption. Optimisation is critical. A failure to optimise means you’ll pay more. The only time you want to pay more is when what you’re paying for delivers a tangible, cost-recoverable benefit to the business. (I.e., it’s something you get to charge someone else for, either immediately, or later.)

If we think about backup, it’s about getting data from location A to location B. In order to optimise it, you want to do two distinct thinks:
- Minimise the number of ‘hops’ that data has to make in order to get from A to B
- Minimise the amount of data that you need to send from A to B.
If you don’t optimise that, you end up in a ‘classic’ backup architecture that we used to rely so much on in the 90s and early 00s, such as:
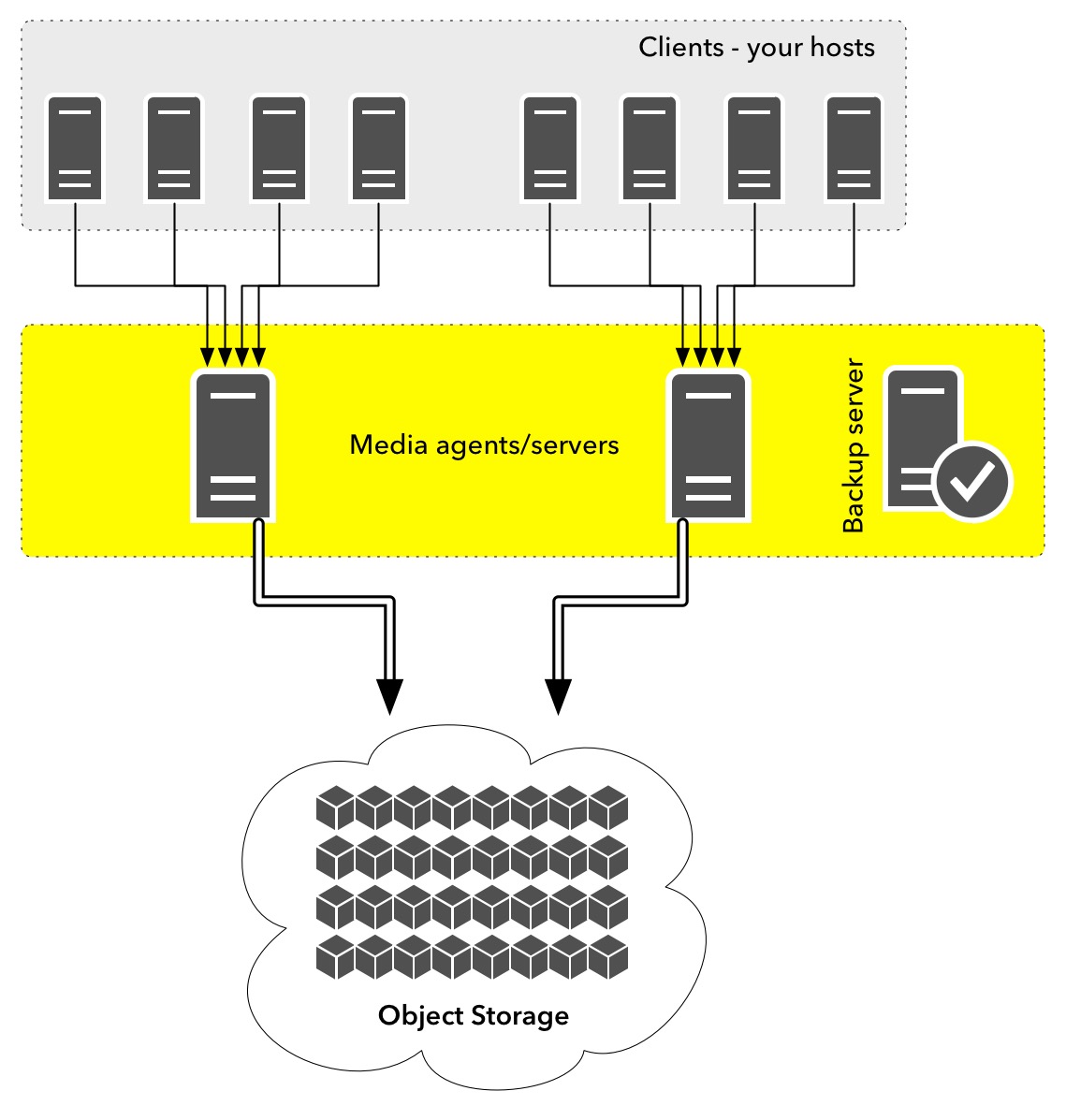
(In this case I’m looking just at backup services that land data into object storage. There are situations where you might want higher performance than what object offers, but let’s stick just with object storage for the time being.)
I don’t think this diagram is actually good at giving the full picture. There’s another way I like to draw the diagram, and it looks like this:
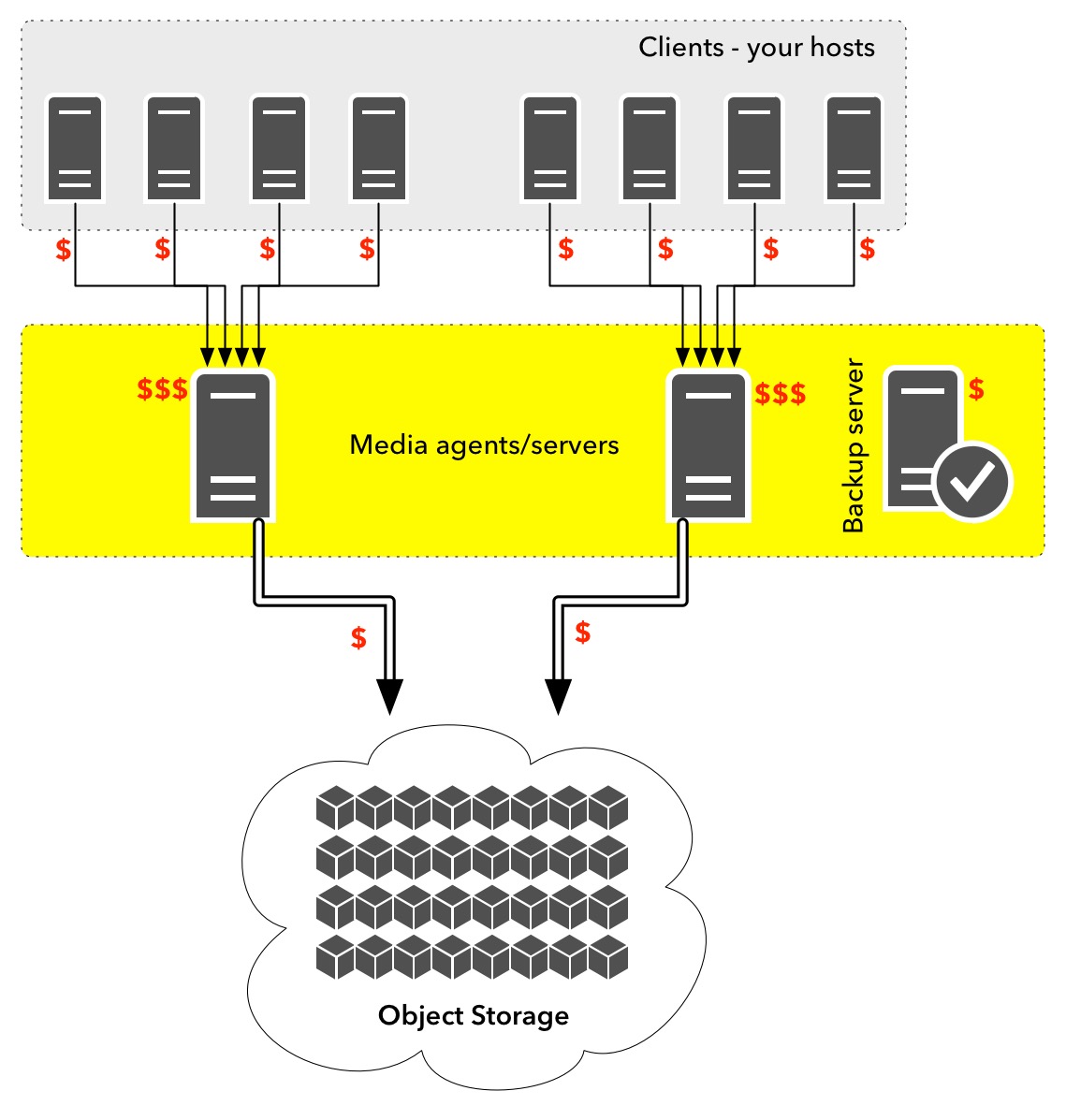
In the Cloud, you’re going to pay for the systems you’re running for business purposes no matter what. That’s a cost you have to accept, and the goal is to ensure that whatever services or products you’re on-selling to your customers using those services will pay for the running costs in the Cloud***.
You want to ensure you can protect data in the Cloud, but sticking to architectures designed at the time of on-premises infrastructure – and physical infrastructure at that – is significantly sub-optimal.
Think of how traditional media servers (or in NetWorker parlance, storage nodes) needed to work. A media server is designed to be a high performance system that funnels data coming from client to protection storage. If a backup architecture still heavily relies on media servers, then the cost in the Cloud is going to be higher than you need it – or want it – to be. That gets worse if a media server needs to be some sort of highly specced system encapsulating non-optimised deduplication. For instance, one of NetWorker’s competitors provides details on their website of hardware requirements for deduplication media servers, so I’ve taken these specifications directly from their website. To work with just 200 TB of storage allocated for deduplication, a media server for that product needs:
- 16 CPU Cores
- 128 GB of RAM
- 400 GB SSD for OS and applications
- 2 TB of SSD for deduplication databases
- 2 TB of 800 IOPs+ disk (SSD recommended in some instances) for index cache
For every 200 TB. Think on that for a moment. If you’re deploying systems in the Cloud that generate a lot of data, you could very easily find yourself having to deploy multiple systems such as the above to protect those workloads, in addition to the backup server itself and the protection storage that underpins the deduplication system.
Or, on the other hand, you could work with an efficient architecture designed to minimise the number of data hops, and minimise the amount of data transferred:
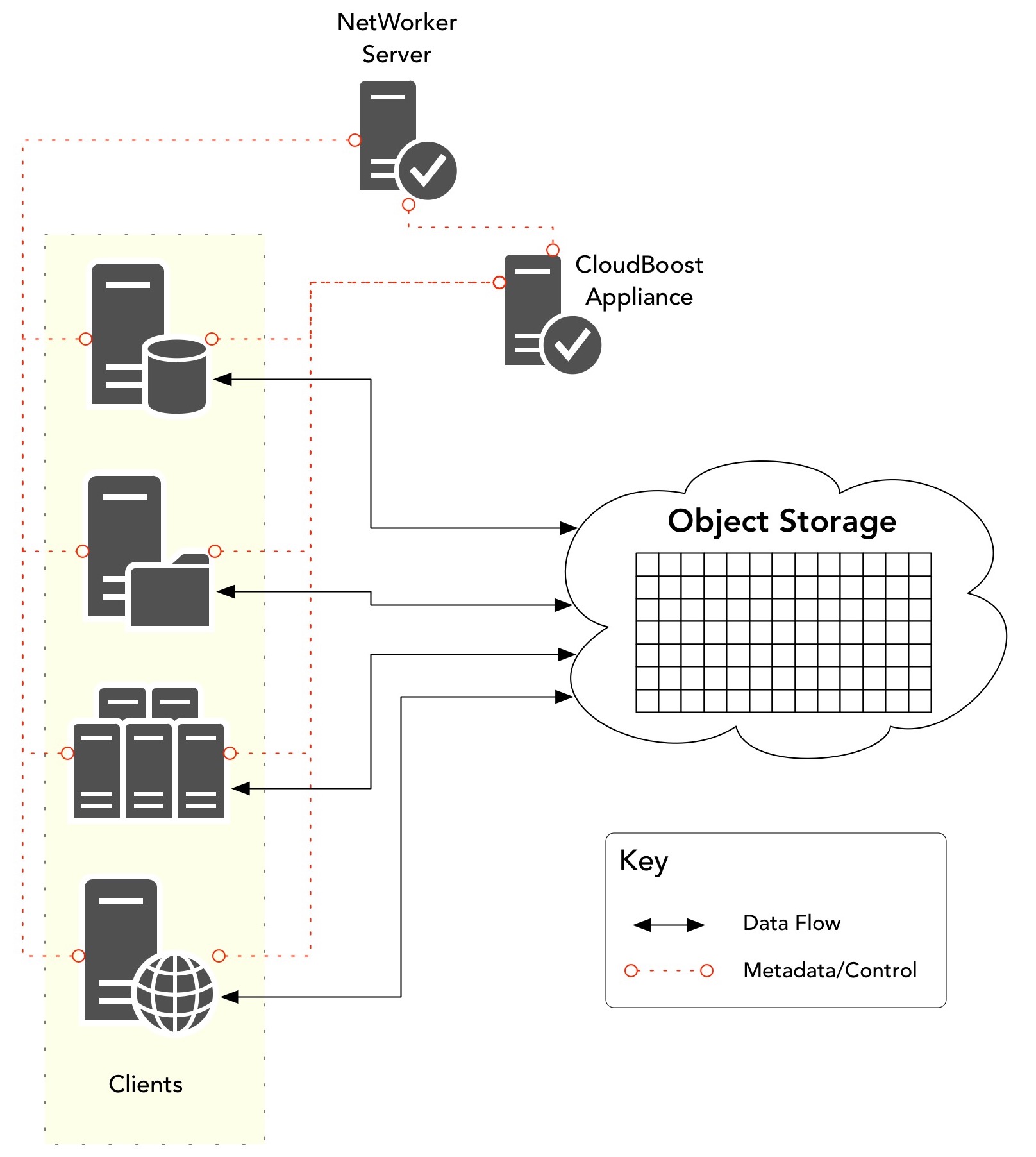
That’s NetWorker with CloudBoost. Unlike that competitor, a single CloudBoost appliance doesn’t just allow you to address 200TB of deduplication storage, but 6 PB of logical object storage. 6 PB, not 200 TB. All that using 4 – 8 CPUs and 16 – 32GB of RAM, and with a metadata sizing ratio of 1:2000 (i.e., every 100 GB of metadata storage allows you to address 200 TB of logical capacity). Yes, there’ll be SSD optimally for the metadata, but noticeably less than the competitor’s media server – and with a significantly greater addressable range.
NetWorker and CloudBoost can do that because the deduplication workflow has been optimised. In much the same way that NetWorker and Data Domain work together, within a CloudBoost environment, NetWorker clients will participate in the segmentation, deduplication, compression (and encryption!) of the data. That’s the first architectural advantage: rather than needing a big server to handle all the deduplication of the protection environment, a little bit of load is leveraged in each client being protected. The second architectural advantage is that the CloudBoost appliance does not pass the data through. Clients send their deduplicated, compressed and encrypted data directly to the object storage, minimising the data hops involved****.
To be sure, there are still going to be costs associated with running a NetWorker+CloudBoost configuration in public cloud – but that will be true of any data protection service. That’s the nature of public cloud – you use it, you pay for it. What you do get with NetWorker+CloudBoost though is one of the most streamlined and optimised public cloud backup options available. In an infrastructure model where you pay for every resource consumed, it’s imperative that the backup architecture be as resource-optimised as possible.
IaaS workloads will only continue to grow in public cloud. If your business uses NetWorker, you can take comfort in being able to still protect those workloads while they’re in public cloud, and doing it efficiently, optimised for maximum storage potential with minimised resource cost. Remember always: architecture matters, no matter where your infrastructure is.
Hey, if you found this useful, don’t forget to check out Data Protection: Ensuring Data Availability.
—
* Yes, I am aware there’ll be other costs beyond power and cooling when calculating a true system management price, but I’m not going to go into those for the purposes of this blog.
** Some readers of my blog may very well recall earlier computing models. But I started with a Vic-20, then the Commodore-64, and both taught me valuable lessons about what you can – and can’t – fit in memory.
*** Many a company has been burnt by failing to cost that simple factor, but in the style of Michael Ende, that is another story, for another time.
**** Linux 64-bit clients do this now. Windows 64-bit clients are supported in NetWorker 9.2, coming soon. (In the interim Windows clients work via a storage node.)