Here’s a topic that comes up from time to time: block size in deduplication. (Note here I’m using the term ‘block’ interchangeably with ‘segment’ to keep things generic.) If you’re used to Data Domain deduplication, you know it uses variable size segments/blocks with an average size of around 8KB.
Other products though are as likely as not to use fixed block size, and often much larger. There’s some backup software with deduplication options out there for instance that regularly use or recommend block sizes between 128KB and 512KB, and in some cases even 4MB.
Does it matter though?
Well, yes. Quite a bit, in fact.

Let’s approach it from the perspective of something simple – say, a 128KB Microsoft Excel file. Now, in a worst case scenario on a first backup of a new file (particularly if nothing else has been backed up before), it’s reasonable to expect for most files we’ll still get, say, 2:1 compression: so that 128KB file would be stored in 64KB.
It’s what happens after that shows how much the deduplication block size impacts the storage efficiency. But let’s start with the first compression, first using the 128KB deduplication block size. Effectively, it’ll look like this:
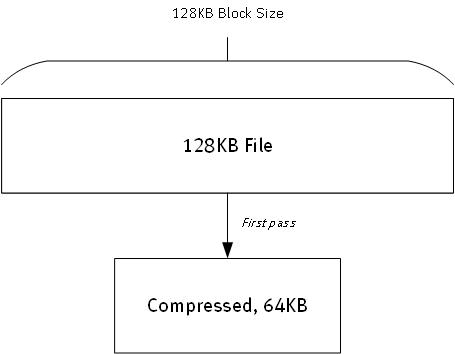
It’s pretty simple: the file is encountered, it doesn’t match anything seen, so it’s compressed and stored to disk. (We’re keeping with that 2:1 compression ratio I mentioned earlier.) So we received 128KB and wrote 64KB.
Now, if we’re using a deduplication algorithm that averages an 8KB block size evaluation (and for simplicity, I’m going to assume every block is evaluated at exactly 8KB), the initial process in terms of space saving is going to look very similar:
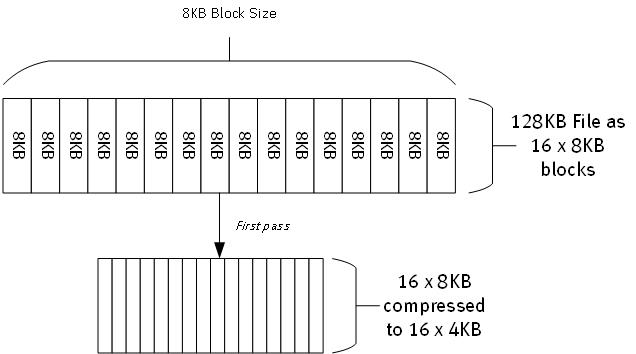
There’s a bit more processing, obviously, since we’re splitting that file up into the preferred block sizes that we’re dealing with. (Variable segmentation/block size obviously can result in different sized segments rather than all just 8KB.) However, assuming each of those 8KB segments/blocks are unique, we’re going to read 16 x 8KB blocks, and write 16 x 4KB blocks. A net storage requirement of 64KB.
So far the storage requirements are the same, right? Yes: but the secret with deduplication is that it’s never the first pass you care about. It’s what happens when you pass over the data the second and subsequent times that matters.
What happens then if someone goes into one of the cells in the Excel file and makes a change? Well, when we’re using 128KB deduplication block size, it looks like this:
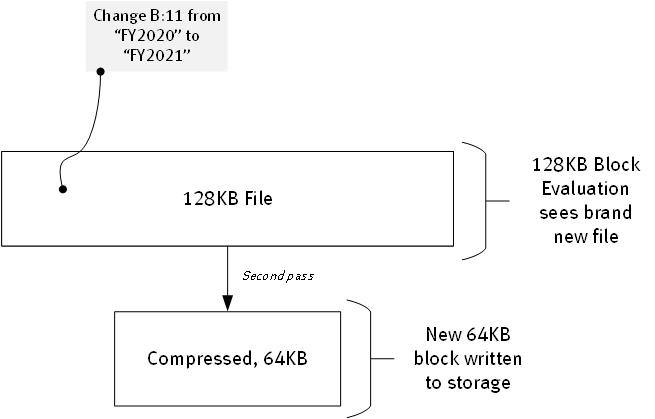
So the Excel file gets updated, and then re-evaluated later during a backup for deduplication. But the entire 128KB file is now seen as a new data source for the deduplication engine. Why? Because we’re only looking at 128KB blocks, so this 128KB block is going to get a different hash signature from the previous time the file was backed up by virtue of the new content being added.
So after 2 backups of a 128KB file using a 128KB deduplication block size, we’ve stored … 128KB.
What’s it look like though when we are dealing with deduplication blocking averaging around the 8KB mark? Well, let’s be kind to 128KB block sizes and assume a worst case scenario that our minor change to the file somehow spans an 8KB boundary:
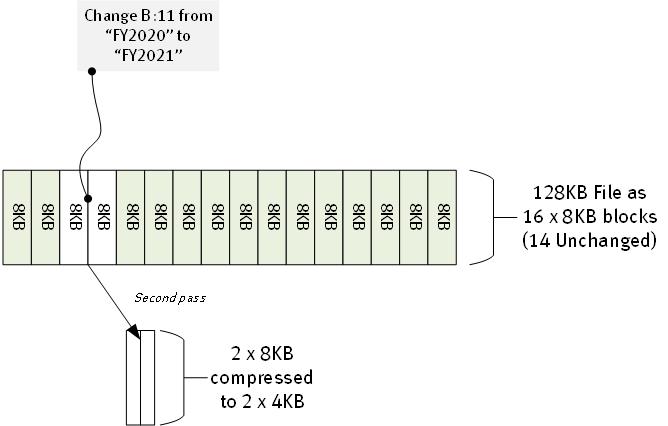
In this scenario, because we’re using 8KB block sizes (average), then in our example 14 of the 16 x 8KB blocks that the file splits up into have already been seen and don’t need to be stored. There’s only 2 x 8KB blocks (given we’ve allowed the change spanning a block boundary) that are seen as new data. The net result is that we just backup another 2 x 8KB blocks, compressed – so 8KB total.
So after doing 2 backups of a 128KB file using ~8KB deduplication block size, we’ve stored … 72KB. That’s close to double the storage efficiency.
Now imagine that same process happening over tens, hundreds of thousands of files or more, and within databases and other data within the backup environment on a daily basis. And this is all without considering deduplication between files, which will drive efficiencies more, particularly with the smaller block size. (And imagine the differences if we then account for the updated compression capability in the new PowerProtect DD series!)
The differences in deduplication block size are not minor: they can literally be the difference between whether you deploy 1PB of usable storage for your deduplication system, or 200TB. The ongoing effects in storage efficiency, backup performance, and run costs (power, cooling, rack space) all add up to show that when it comes to deduplication, architecture matters.
Well explained……dedupe for dummies! thank you