
If you’ve been around in IT for a while, you’ll have undoubtedly heard of Data Gravity. To me it’s a strong theory that resonates with how I’ve seen data accumulate in a lot of organisations.
But here’s the rub: data gravity applies equally to financially useful data and junk data. I.e., we often think of data gravity in the context of useful or valuable data that a business has accumulated, but the same principles that govern the accumulation of data work for data with no value, too.
I’ve been thinking about data hoarding for a while. You see, in the last days of December 2022, my father died. Dad was many things, but he was also a compulsive hoarder. There was nothing healthy about the way he hoarded things. In the year before he died, he managed to let go of his LP collection of more than 40,000 33s, 45s and 78s, but that was a rare victory for the family. He maintained a belief (that we had repeatedly, at times gently and at times bluntly tried to disabuse him of) that once he died, my brother and I would take 6-12 months away from our jobs to sort through everything he had accumulated and auction it all for ‘maximum’ value. Instead, after he died, my relatives mounted a Herculean effort and organised the removal of several tonnes of junk.
Real-life hoarding is a sickness and it does not help either the hoarder, or the people around the hoarder.
I’m of the opinion that data hoarding within a business is no different. In particular, hoarding of junk data is no different than real-life hoarding. At best, it’s a sign of an unhealthy organisation; at its worst, it can act as a drag on the finances and velocity of the business.
Data hoarding occurs when a business doesn’t properly follow a data lifecycle. This should look something like the figure below – with the key two steps emphasised.
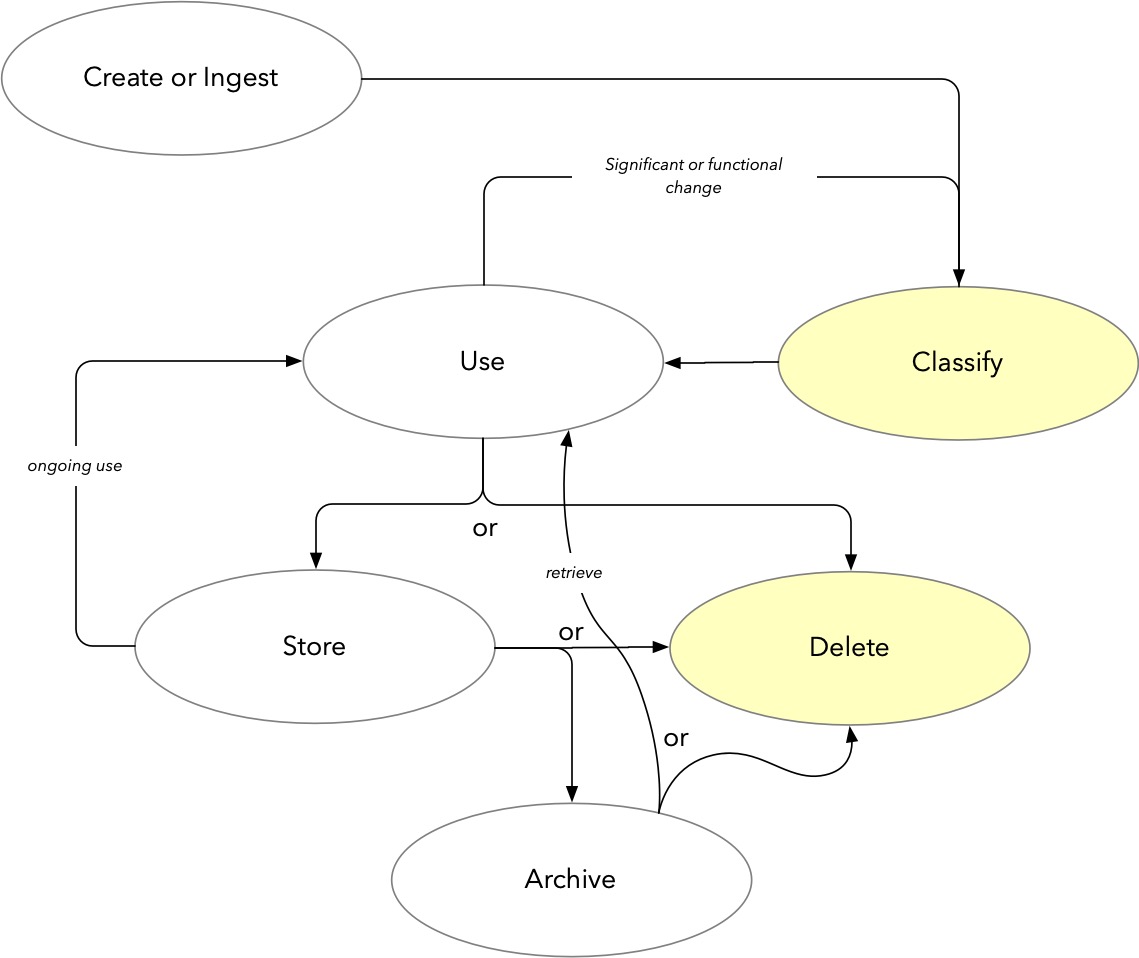
To avoid data hoarding, it’s essential you:
- Classify incoming data (or data that has significantly changed), so you know whether it’s real data or junk data, and
- Delete the data when it’s no longer needed.
You still have to pay attention to the rest of the data lifecycle – using, storing and archiving – but if you’re not prepared to classify data (i.e., work out what it is, and what value it represents to the business), or delete it when it’s no longer needed, you’re engaging in hoarding.
Hoarding doesn’t go without consequences. My parent’s house is quite spacious, and has multiple storage buildings on the block – but when dad was alive, you literally couldn’t move more than one or two paces without being overwhelmed with junk and detritus in your way. I visited in March after the cleanup and it was like stepping into a new house that someone had just moved into – there was so much free space it was breathtaking.
The same goes for data hoarding. Let’s say you hoard 1 TB of data on primary storage – data that, had it been properly classified and deemed junk, could have been deleted. Instead, you’re worried that it might be valuable later and so you keep storing it. But it’s sitting on a storage platform that gets regular snapshots and is replicated to another site – so let’s say the primary storage consumption is at least 2 TB (assuming there are no changes to the data, so the snapshots are minimal). So 1 TB has become 2 TB before we even step off primary storage platforms.
Then you’ve got your protection copies – you might keep 4 weekly copies, with replication – that’s another 8 TB (4 TB of local backups, 4 TB of replicated backups). (If there are no changes we can assume the daily incremental backups are inconsequential.) And because you’re hoarding – because you don’t know whether it’s data that may be good later – you’re doing monthly backups and keeping those for 7 years, and replicating those backups. (So that’s 84 TB of monthly backups and 84 TB of replicated monthly backups.)
That 1 TB of unclassified data you’re hoarding? Between primary and secondary copies, you’re maintaining 178 TB of data over a 7-year period.
Sure, deduplication will do wonders at shrinking that occupied capacity down. Maybe the occupied storage will end up being quite a low amount, in fact. But the logical copy size remains what I’ve outlined above. Regardless of the physical occupancy, that storage size isn’t the end of the story – you’ve also got:
- Acquisition costs (for on-prem systems)
- Support/maintenance costs
- Runtime costs (For on-prem: power, cooling, etc. For cloud: monthly billing costs)
- Management costs (staff operations, training and process documentation – or managed services)
- Potential legal costs (what if there’s a court case and the data is wrapped up in a data discovery process?)
That 1 TB of unclassified, hoarded data isn’t just a cost to the business though. It’s a distraction. You either have staff or managed services teams having to spend some fraction of their time managing that data and all the copies associated with it, and that cost and management time might have been better spent on some identified, tangible need of the business.
Worse, this is where data gravity comes in – but instead of being driven by applications and processes building up around the data, you get apathetic data gravity when it’s junk data: the data looks messy, it’s just a big pile, and so you end up accumulating other junk and pseudo-junk data alongside it because there’s a handy storage bucket that isn’t measured.
You might think that data archival can be a solution to hoarding – but it’s not. Or rather, it can be very effective at kicking the can down the road – but that’s not a solution, it’s just putting off the inevitable (or passing it onto someone else). In fact, archiving hoarded junk data is just a cost deflection; there’ll still be costs (direct and indirect) for using and managing the archival platform. As opposed to zero costs once the data is deleted.
The only true solution to data hoarding is data deletion. And your business will feel healthier for it.
2 thoughts on “Data Hoarding is Probably Holding your Business Back”