Why do I need eCDM? Your first question to me might be what is eCDM? Well, that’s a fair point – it’s a relatively new term, and it’s also an eTLA – an extended Three Letter Acronym. eCDM refers to enterprise copy data management. Now this isn’t necessarily a backup topic, but backup is one of the components that fit into copy data, so it’s a sideline topic and one which will get increasing attention in the coming years.
You see, data growth continues to increase, but the primary data set, the original dataset is typically growing at a fairly straight-forward rate. It’s definitely growing, but not to the same degree as the occupancy by copies of the data. The numbers as such (timescale or size) don’t really matter, but for a lot of businesses, the disparity between original dataset and copies of the dataset if mapped will look something along the lines of the following:
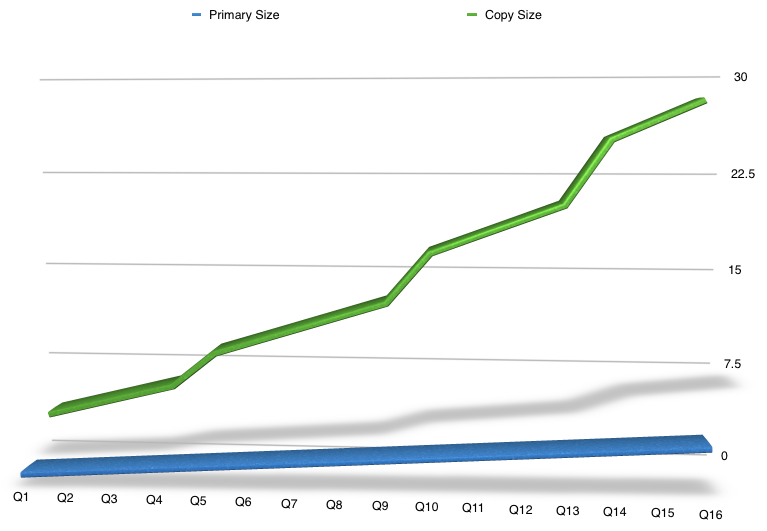
Your mileage depending on what your original data is, its RPOs and RTOs, and what you use it for will vary of course, and that’ll have an impact on the number of copies you keep. But that sort of comparison will look similar to a lot of people when they sit down to think about it. In fact, when the topic of eCDM first started coming up in (at the time) EMC, a colleague and I got to talking about our experiences with it. I related a few of my experiences from my prior life as a Unix system administrator, and my colleague mentioned in a previous job they’d actually done a thought experiment to calculate the average number of copies being retained for databases in their environment. The number? 26. And his first thought when he said that number was “…it was probably too low”.
If you’re not sure about this, let’s run our own experiment, and start with a 1TB database.
We all know though, right, that 1TB isn’t 1TB isn’t 1TB when it comes to enterprise storage? For a start, that’s not going to occupy 1TB of disk storage – there’s going to be RAID involved. (I’m not going to bother with RAID here, that’s an overhead no matter what.)
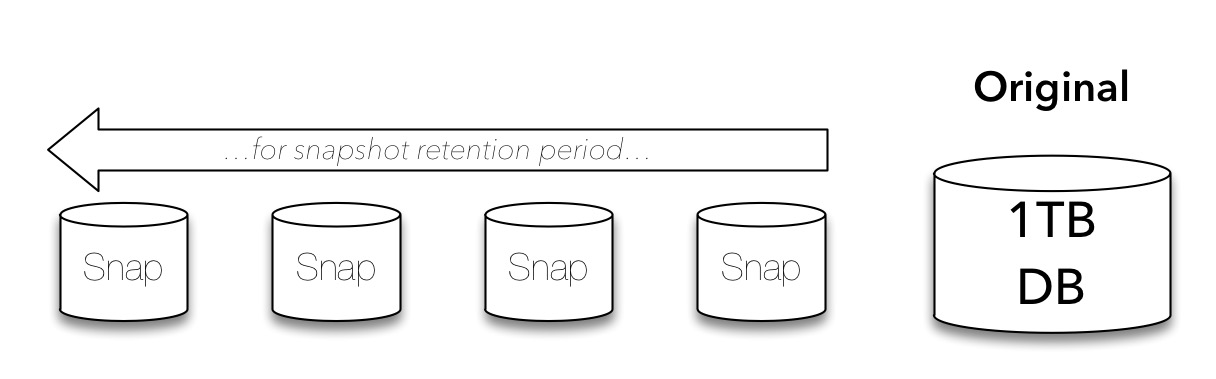
For important systems within our environments requiring fast recovery times with minimised data loss, we’ll be looking at maintaining snapshots. Now, these days snapshots are usually logical copies rather than complete 1:1 copies, but there’s still a data overhead as changes occur, and there’s still a management cost (even if only at a human level) for the snapshots. So our 1TB database becomes something along the following lines:
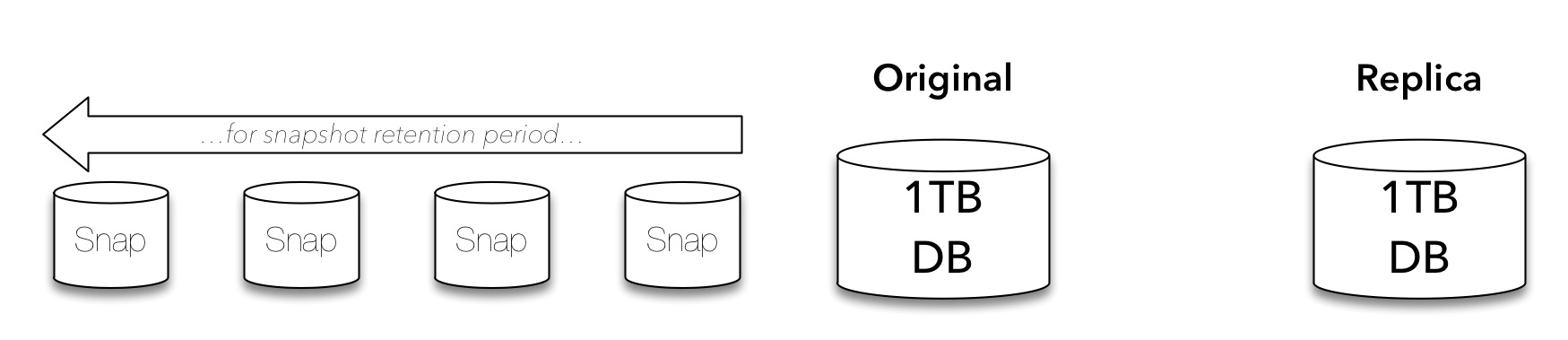
But we don’t just keep a local instance of important data – it gets replicated:
And of course, when we’re replicating, we typically need to keep snapshots in the replica storage as well to ensure a replication of corruption doesn’t destroy our recoverability in a disaster:

Of course, so far we’ve just been looking at primary copies, so we also need to think about having a backup copy:
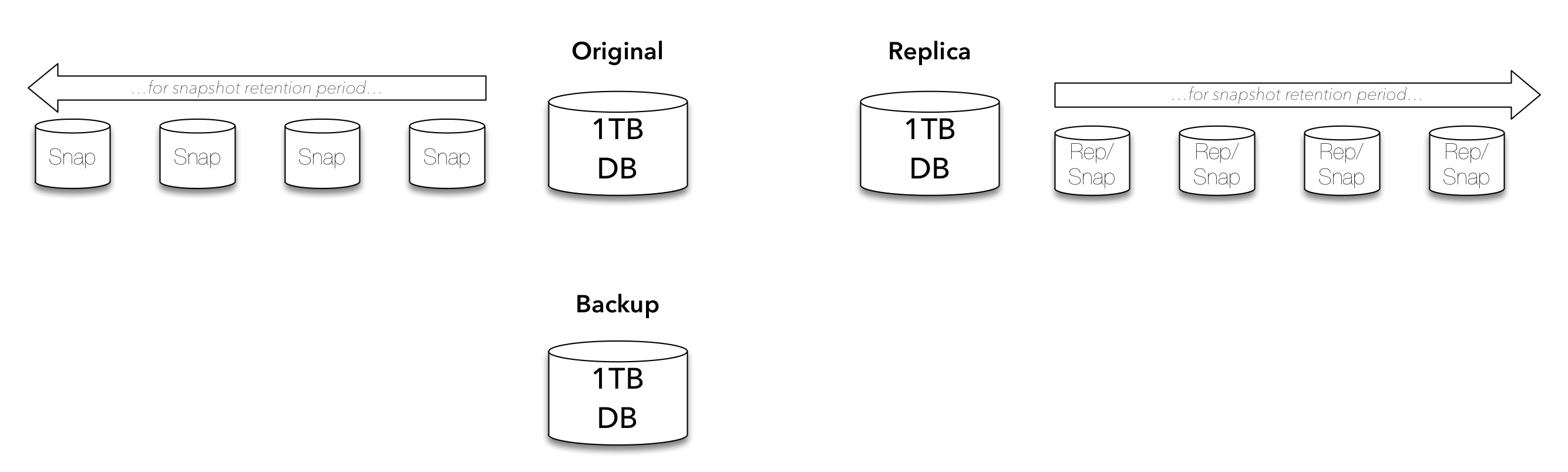
But we know a single backup isn’t much of a backup, so we’re going to be keeping multiple backups:
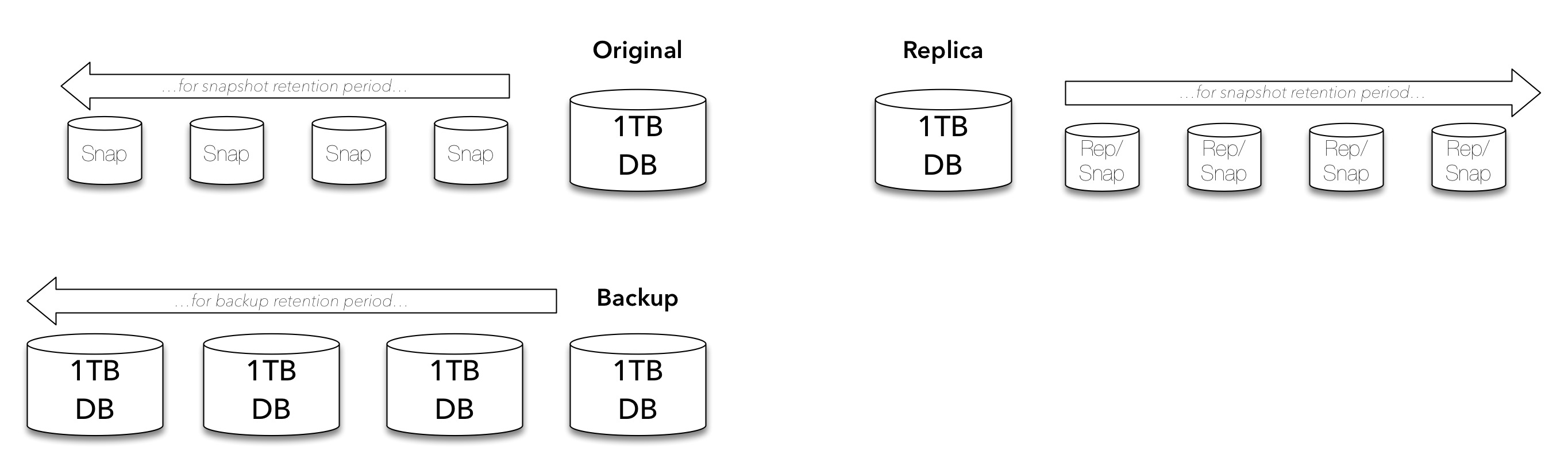
And of course, a backup should never be a single point of failure within an environment, so that’s more likely going to look like the following:
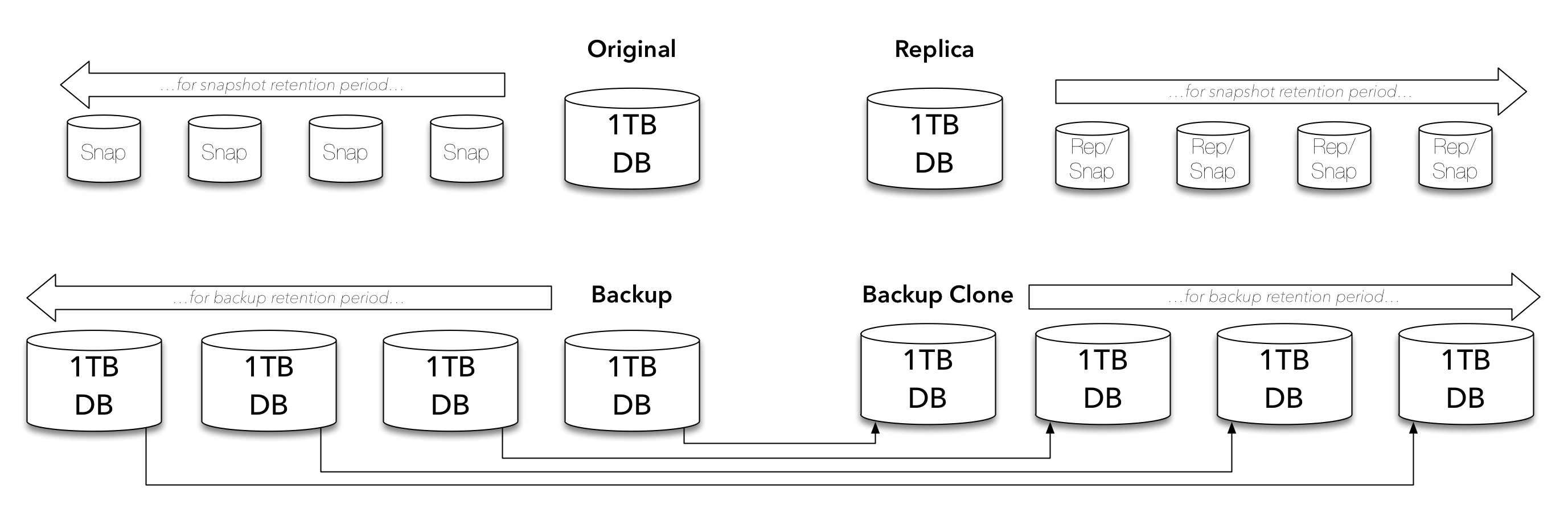
They’re just our regular retention backups though. Most companies, whether we’d encourage them otherwise or not, will use the backup environment to maintain long term retention (LTR) copies for compliance purposes, so we need to consider those copies as well:
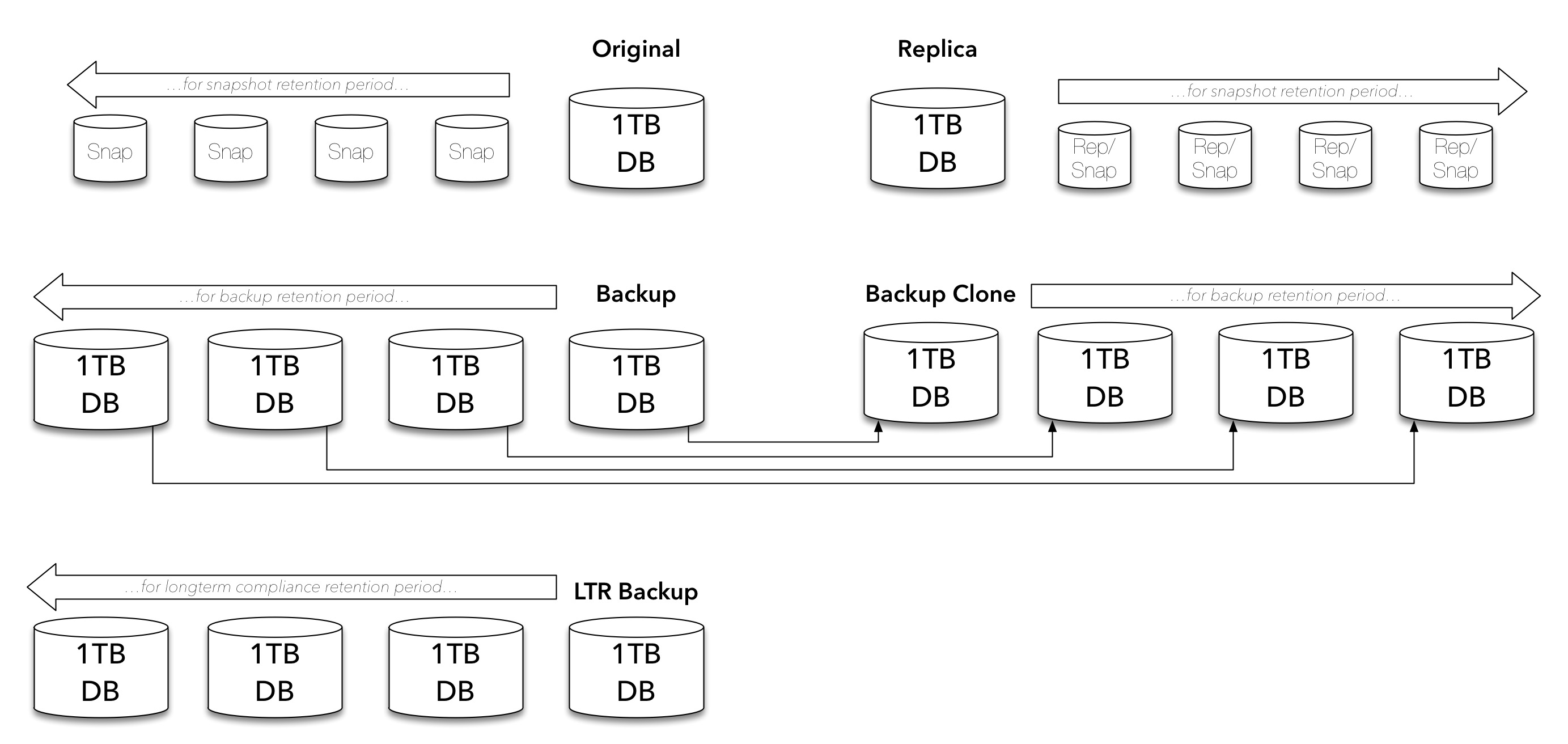
And again, LTR backups shouldn’t be a single source of failure either, so:
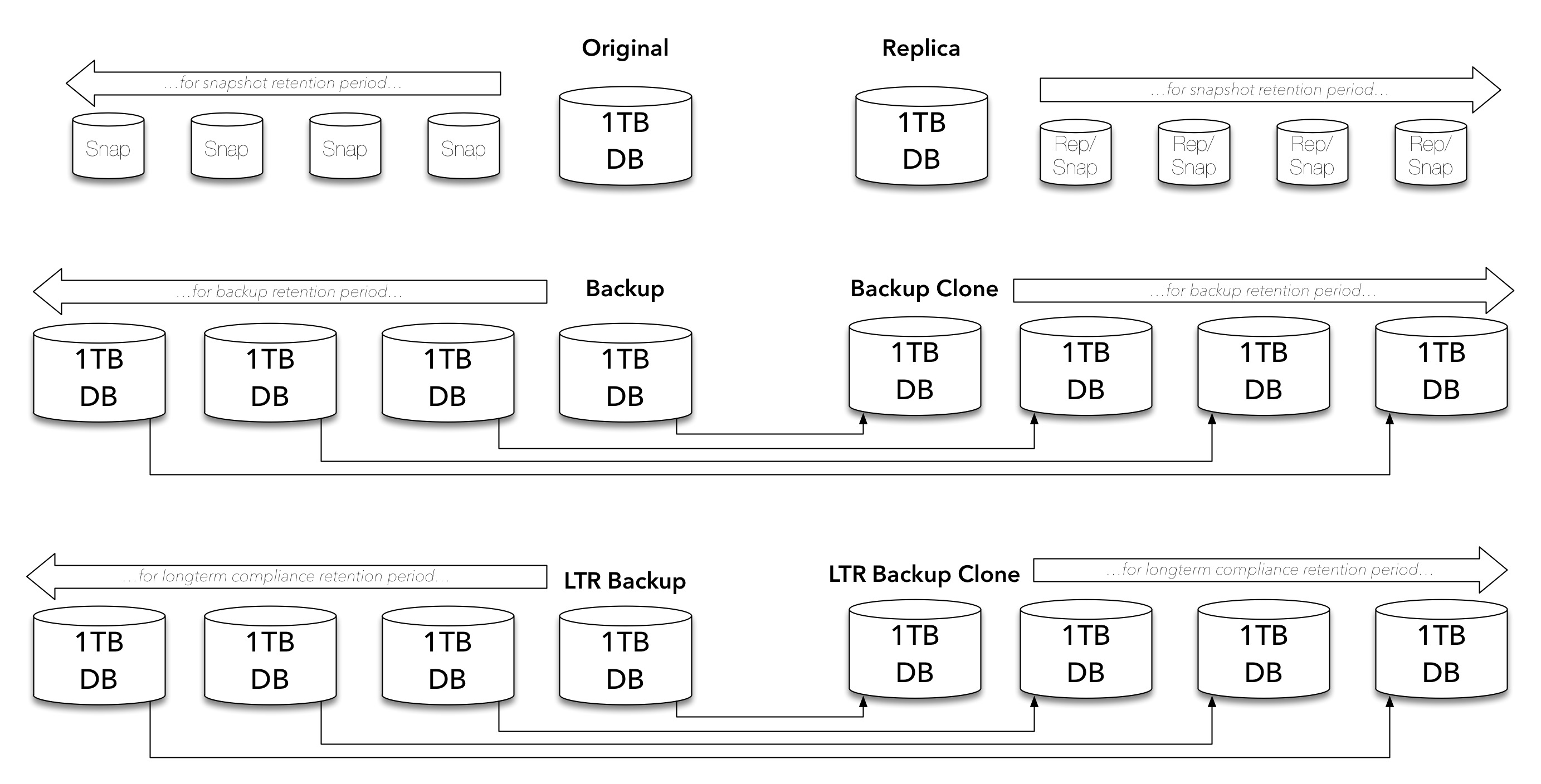
Phew! Regardless of whether you’re deduplicating, regardless of whether your snapshots are copy-on-first-write or some other space saving technique, that’s a lot of copies being built up, and as changes occur, that’s still a growing increase in the amount of primary and protection storage required for just 1 TB of original data.
Yet we’re not done. For businesses facing new threats, there’ll potentially be copies of the database sitting in an isolated recovery site, too:
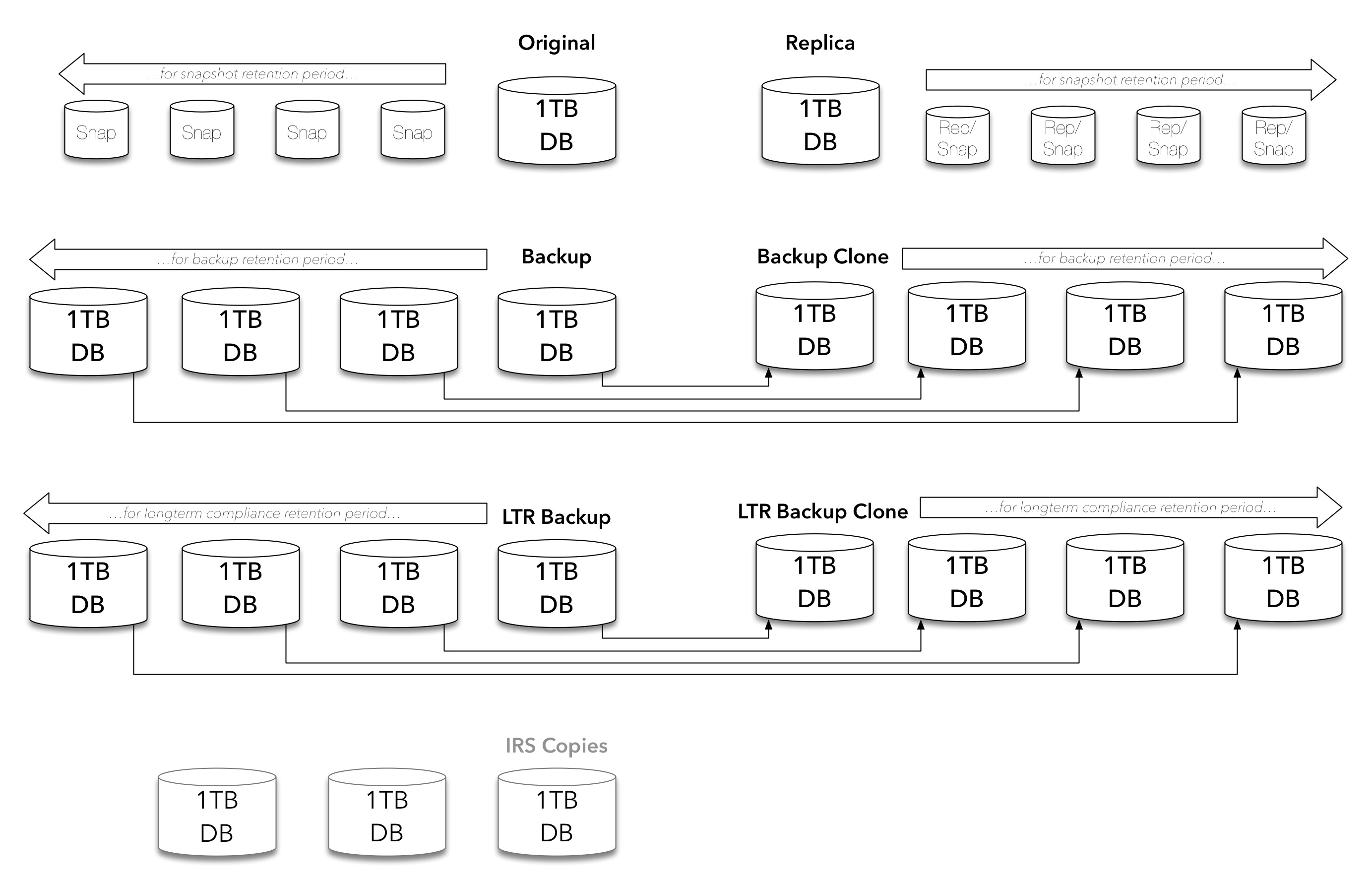
Even more copies. Admittedly your IRS copies shouldn’t be manageable via conventional means, but they’re there, and if you’ve got to manage them on top of all the other copies, you’re compounding your work again.
Yet we’re still not done. So far I’ve covered an indicative set of copies for the original use case of the original data. That’s not the end of it!
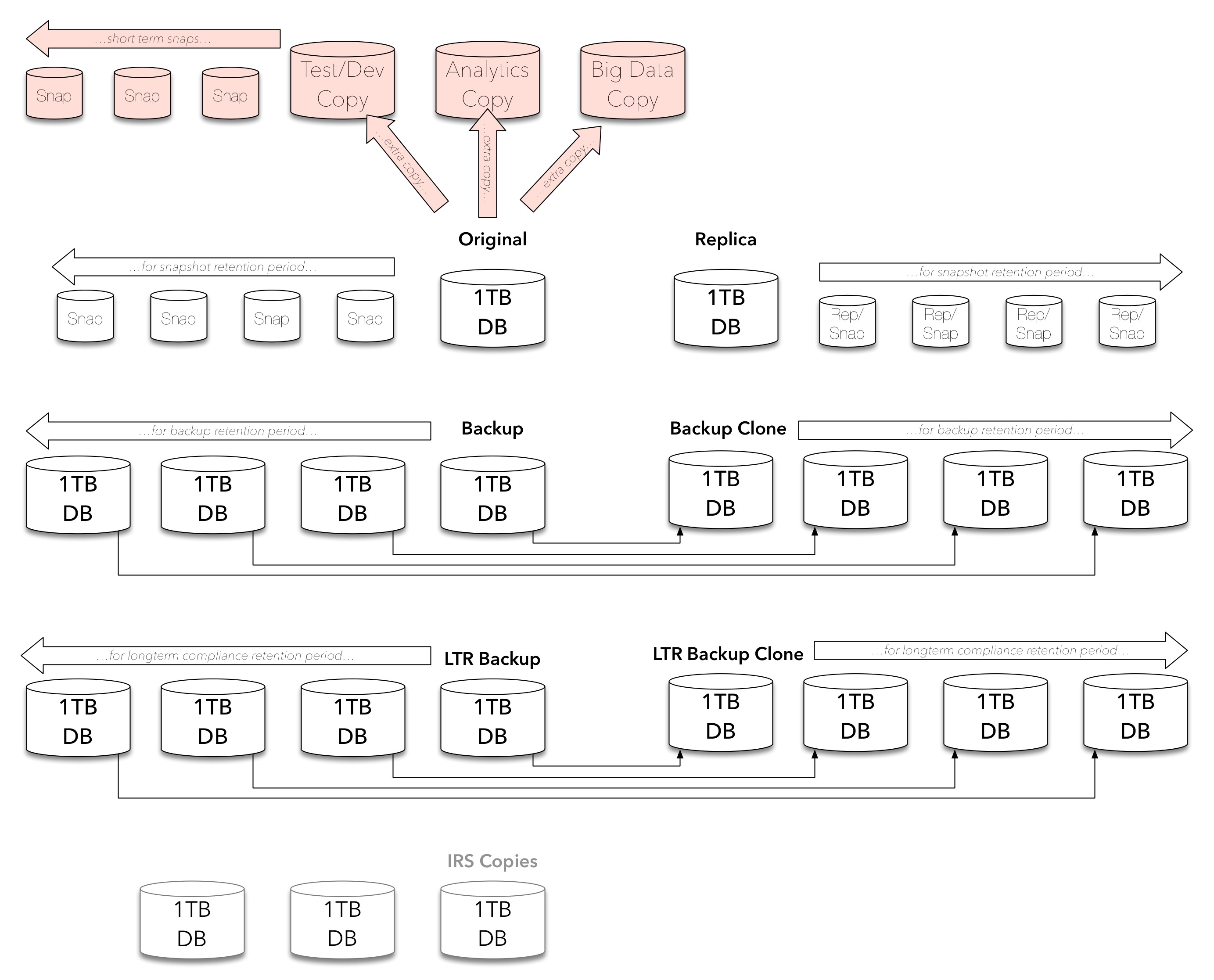
So let’s return to the original question: why do I need eCDM? By now that should be answered: why don’t you need eCDM!? You’ve got copies … and copies and copies and copies … sitting in your environment, occupying primary storage, replication storage, protection storage, and in time even possibly in cloud storage too.
This is where eCDM comes in – having a system that can give you focus on the copies of data being generated in your environment. In version 1 of eCDM, we’ve focused on giving power over ProtectPoint related copies, but that’s a starting point. There’s more to follow over time, of course.
To quote the eCDM product page, eCDM:
- Discovers copies non-disruptively across the enterprise for global oversight
- Automates SLO compliance and efficient copy creation
- Optimizes IT operations based on actionable insight
eCDM is a new tier of data management to help organisations deal with copy data, and if you sit down and think about the number of copies you might have (particularly of critical data sets in your organisation), you’ll probably find yourself wondering why you don’t have it installed already.