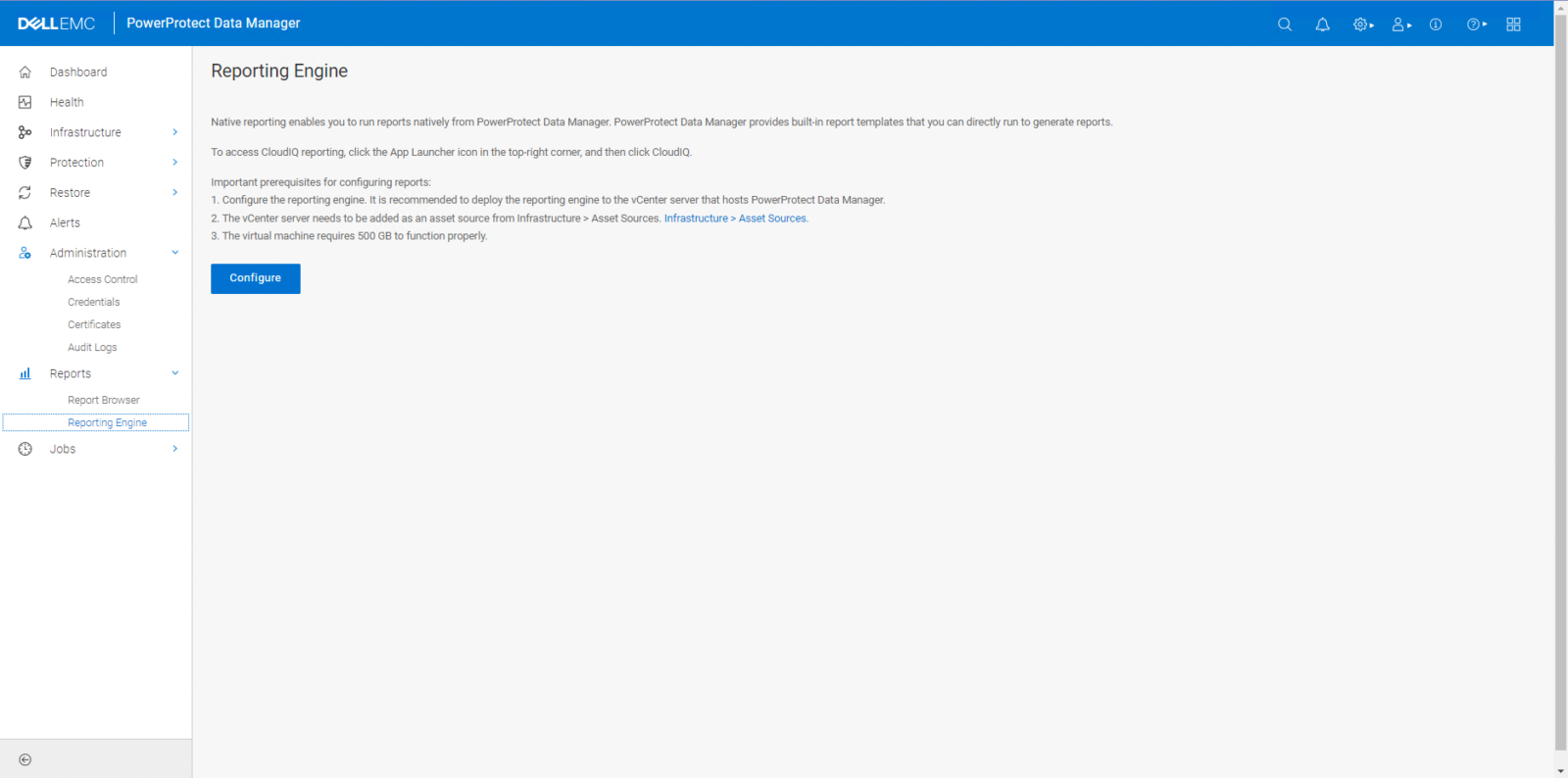
In PowerProtect Data Manager 19.10, a report engine was added. Data Protection Advisor could, and can still be used to…
In PowerProtect Data Manager 19.10, a report engine was added. Data Protection Advisor could, and can still be used to…
As I’ve mentioned in the past, there’s a few different licensing models for NetWorker, but capacity licensing (e.g., 100 TB…
In 2013 I undertook the endeavour to revisit some of the topics from my first book, “Enterprise Systems Backup and Recovery: A Corporate…
Something that’s come up a few times in the last year for me has been a situation where a NetWorker…
For those of us who have been using NetWorker for a very long time, we can remember back to when the NetWorker Management…
When IDATA was beta testing NetWorker 7.6 SP1, my colleagues in New Zealand were responsible for testing the DD/Boost functionality.…
One of the areas where administrators have been rightly able to criticise NetWorker has been the lack of reporting or…