Client direct is a (relatively) new feature, introduced in the 8.x series, (8.0 to be exact) which allows for a client to communicate directly with the backup device rather than going through a storage node.
This obviously requires the client to have access to the backup device, and only happens when you’re backing up to Data Domain Boost or an Advanced File Type Device (AFTD). (Direct access to tape drives – physical or virtual – comes in library or dynamic drive sharing.)
The real power of this feature happens when you’re using Data Domain within your environment though. When Data Domain Boost compatibility was first introduced in NetWorker, it was on the basis of a very traditional storage node model, i.e.:
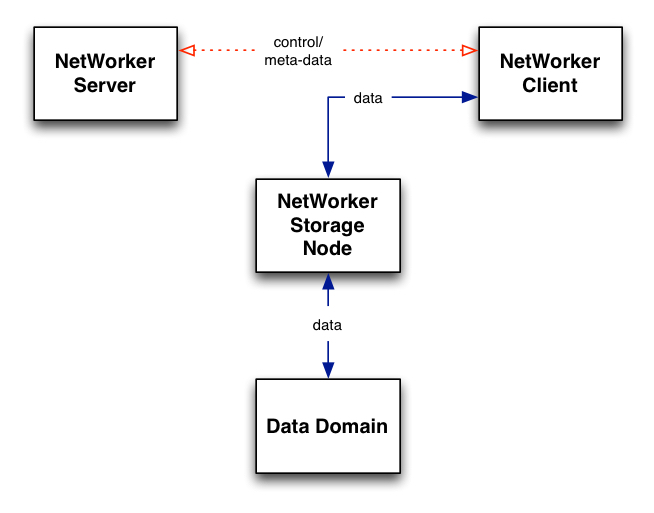
As a starting point with Data Domain Boost, the NetWorker storage node software was updated to support deduplication offloading, referred to as “distributed segment processing”. That’s where the storage node communicated with the Data Domain and determined what client data it was receiving actually needed to be sent across to the Data Domain. (This came in for NetWorker 7.6 SP1, where support for Data Domain Boost devices was added.)
It was, in effect, a pseudo source-based deduplication process … it wasn’t quite source-based, but it wasn’t technically target based, either. The storage node would act as a deduplication agent for the Data Domain. This had two advantages:
- By distributing the deduplication processing, higher ingest rates could be achieved. (Though it should be noted that Data Domain is no slouch when it comes to ingest speed. But next to recoverability, speed is always important in a backup and recovery environment.)
- Less data would be sent across the network; while the client data would sent to the storage node, the storage node would not have to send as much data across to the Data Domain. (Which, of course, also helps backup speeds.)
However, the Boost distributed segment processing functionality introduced into NetWorker Storage Nodes was just the beginning. When NetWorker 8.0 introduced the “Client Direct” feature, this was combined with pushing the Boost functionality for distributed segment processing out from the storage nodes to the clients. The net result was a substantial change:
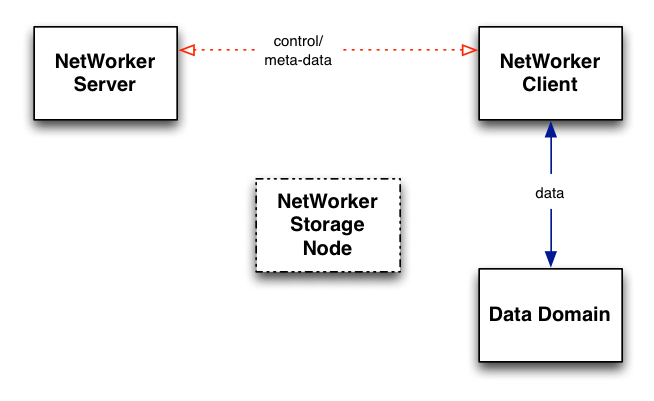
Consider the implications of this: each client performs the Data Domain equivalent of source-level deduplication. It interacts with the Data Domain to perform segment analysis/processing of its own data, substantially minimising the amount of data that needs to be sent across the network. Only the unique segments need to be sent. As we know from products like Avamar, this makes a significant reduction to network traffic, and as a result, to the time taken to perform a backup.
This is the real magic of Client Direct and Data Domain Boost within NetWorker – ‘flattening’ the backup requirements by achieving a far more efficient distributed processing than can be achieved by a traditional server + storage node + client layout.
In fact, there’s two key benefits:
- Drastic reduction in the amount of data that has to be sent across the network for a backup.
- Substantial reduction in the requirements for and specifications of storage nodes.
Consider: in a traditional NetWorker model, storage nodes are typically hefty physical boxes. For a larger environment, they need multiple multi-core processors, significant IP and/or FC connectivity, and may also need large amounts of RAM.
Client Direct + Boost kicks all of thsoe requirements out of the window.
To be certain, those requirements aren’t fully eliminated – processing is shifted to the clients, but at a considerable saving in network traffic, which by and large has usually been a big bottleneck in the backup process.
The biggest selling point of Data Domain of course is the deduplication achieved. If you compare raw Data Domain storage against raw storage in a conventional backup target, the numbers may not favour Data Domain on a TB-by-TB comparison. But as we know, a TB-by-TB comparison isn’t effective; after deduplication and compression, a Data Domain will store considerably more than 1TB within 1TB of space … in that sense deduplication exhibits TARDIS-like qualities.
Beyond the target deduplication levels (and therefore increased storage at a lowered physical footprint) there are the other benefits outlined above, thanks to Client Direct: faster backups, fewer storage nodes, and less processing specification required for those storage nodes. With the vast majority of clients able to communicate directly with the Data Domain, storage nodes step down to being required only for niche activities – acting as a central point for firewall reasons, or supporting clients/modules that can’t work with Boost+Client Direct. (Over time, the second reason will continue to diminish.)
And that’s what you really need to understand about Client Direct.
Is there a rough guide as to the overhead of client direct on the client as far as resourcing goes?
The Data Domain integration guide recommends Client Direct (to Boost devices) should be done on clients that have at least 4GB of RAM. Additionally, the performance tuning and optimisation guide states that additional CPU usage of between 2% and 40% is required during Boost Backups – but given the backup is shorter this is usually less of an impact. (The guide also states that client direct to Boost devices is typically 20-60% faster than a traditional backup.)