When you start looking into deduplication, one of the things that becomes immediately apparent is … size matters. In particular, the size of your deduplication pool matters.
In this respect, what I’m referring to is the analysis pool for comparison when performing deduplication. If we’re only talking target based deduplication, that’s simple – it’s the size of the bucket you’re writing your backup to. However, the problems with a purely target based deduplication approach to data protection are network congestion and time wasted – a full backup of a 1TB fileserver will still see 1TB of data transferred over the network to have most of its data dropped as being duplicate. That’s an awful lot of packets going to /dev/null, and an awful lot of bandwidth wasted.
For example, consider the following diagram being of a solution using target only deduplication (e.g., VTL only or no Boost API on the hosts):
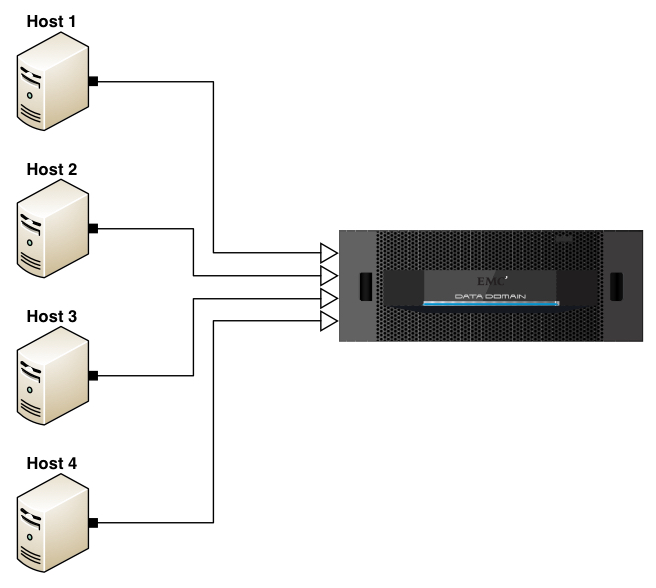
In this diagram, consider the outline arrow heads to indicate where deduplication is being evaluated. Thus, if each server had 1TB of storage to be backed up, then each server would send 1TB of storage over to the Data Domain to be backed up, with deduplication performed only at the target end. That’s not how deduplication has to work now, but it’s a reminder of where we were only a relatively short period of time ago.
That’s why source based deduplication (e.g., NetWorker Client Direct with a DDBoost enabled connection, or Data Domain Boost for Enterprise Applications) brings so many efficiencies to a data protection system. While there’ll be a touch more processing performed on the individual clients, that’ll be significantly outweighed by the ofttimes massive reduction in data sent onto the network for ingestion into the deduplication appliance.
So that might look more like:
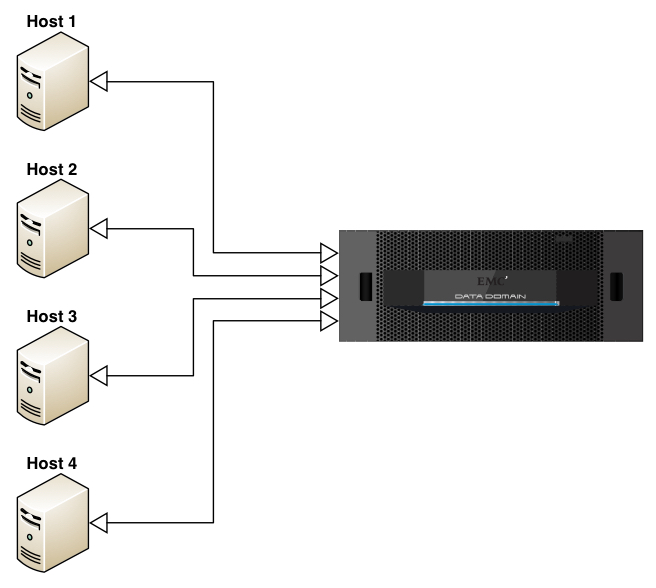
I.e., in this diagram with outline arrow heads indicating location of deduplication activities, we get an immediate change – each of those hosts will still have 1TB of backup to perform, but they’ll evaluate via hashing mechanisms whether or not that data actually needs to be sent to the target appliance.
There’s still efficiencies to be had even here though, which is where the original point about pool size becomes critical. To understand why, let’s look at the diagram a slightly different way:
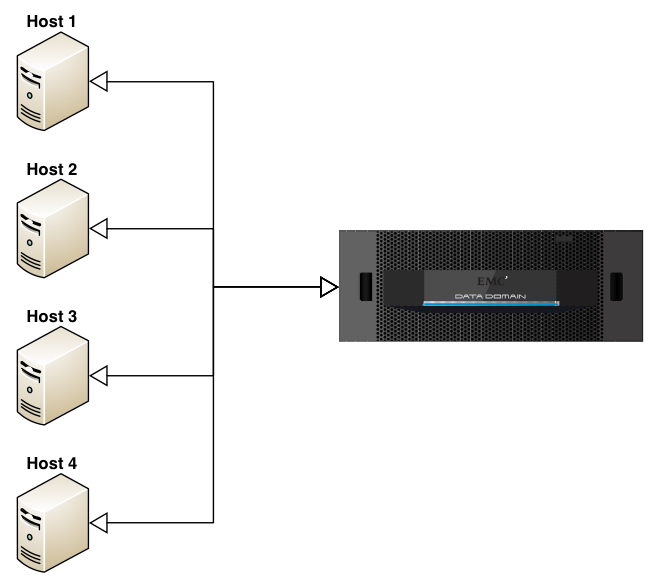
In this case, we’ve still got source deduplication, but the merged lines represent something far more important … we’ve got global, source deduplication.
Or to put it a slightly different way:
- Target deduplication:
- Client: “Hey, here’s all my data. Check to see what you want to store.”
- Source deduplication (limited):
- Client: “Hey, I want to backup <data>. Tell me what I need to send based on what I’ve sent you before.”
- Source deduplication (global):
- Client: “Hey, I want to backup <data>. Tell me what I need to send based on anything you’ve ever received before.”
That limited deduplication component may not be limited on a per host basis. Some products might deduplicate on a per host basis, while others might deduplicate based on particular pool sizes – e.g., xTB. But even so, there’s a huge difference between deduplicating against a small comparison set and deduplicating against a large comparison set.
Where that global deduplication pool size comes into play is the commonality of data that exists between hosts within an environment. Consider for instance the minimum recommended size for a Windows 2012 installation – 32GB. Now, assume you might get a 5:1 deduplication ratio on a Windows 2012 server (I literally picked a number out of the air as an example, not a fact) … that’ll mean a target occupied data size of 6.4GB to hold 32GB of data.
But we rarely consider a single server in isolation. Let’s expand this out to encompass 100 x Windows 2012 servers, each at 32GB in size. It’s here we see the importance of a large pool of data for deduplication analysis:
- If that deduplication analysis were being performed at the per-server level, then realistically we’d be getting 100 x 6.4GB of target data, or 640GB.
- If the deduplication analysis were being performed against all data previously deduplicated, then we’d assume that same 5:1 deduplication ratio for the first server backup, and then much higher deduplication ratios for each subsequent server backup, as they evaluate against previously stored data. So that might mean 1 x 5:1 + 99 x 20:1 … 164.8GB instead of 640GB or even (if we want to compare against tape) 3,200GB.
Throughout this article I’ve been using the term pool, but I’m not referring to NetWorker media pools – everything written to a Data Domain as an example, regardless of what media pool it’s associated with in NetWorker will be globally deduplicated against everything else on the Data Domain. But this does make a strong case for right-sizing your appliance, and in particular planning for more data to be stored on it than you would for a conventional disk ‘staging’ or ‘landing’ area. The old model – backup to disk, transfer to tape – was premised on having a disk landing zone big enough to accommodate your biggest backup, so long as you could subsequently transfer that to tape before your next backup. (Or some variant thereof.) A common mistake when evaluating deduplication is to think along similar lines. You don’t want storage that’s just big enough to hold a single big backup – you want it big enough to hold many backups so you can actually see the strategic and operational benefit of deduplication.
The net lesson is a simple one: size matters. The size of the deduplication pool, and what deduplication activities are compared against will make a significantly noticeable impact to how much space is occupied by your data protection activities, how long it takes to perform those activities, and what the impact of those activities are on your LAN or WAN.