I’m revisiting an old conversation here that I used to have quite a bit around tape, when companies had production and disaster recovery datacentres. The argument back then was that if production systems were 100% mirror replicated to the disaster recovery datacentre, there was no need to replicate backups.
It was a bad idea then, and it’s still a bad idea now.
Don’t get me wrong – in particular if you’re using Data Domain within your environment, you’ve got a rock solid protection storage system sitting underneath your backup environment. The Data Invulnerability Architecture (DIA) is second to none, and if any competitor on the marketplace says they can match it, I wouldn’t trust what they say as far as I could kick their unreliable equipment off a cliff.
But, DIA can’t save you from everything. If your primary datacentre catches fire and the fire suppression systems fail, DIA isn’t going to prevent your Data Domain from going up in a smoking heap when a 500ºC wall of flame smashes into its rack. Yet, even in 2018, people are still saying that if they replicate their production systems from their primary to their failover datacentre, they don’t need to replicate their backups.
Phooey. Let’s see what I’m talking about:
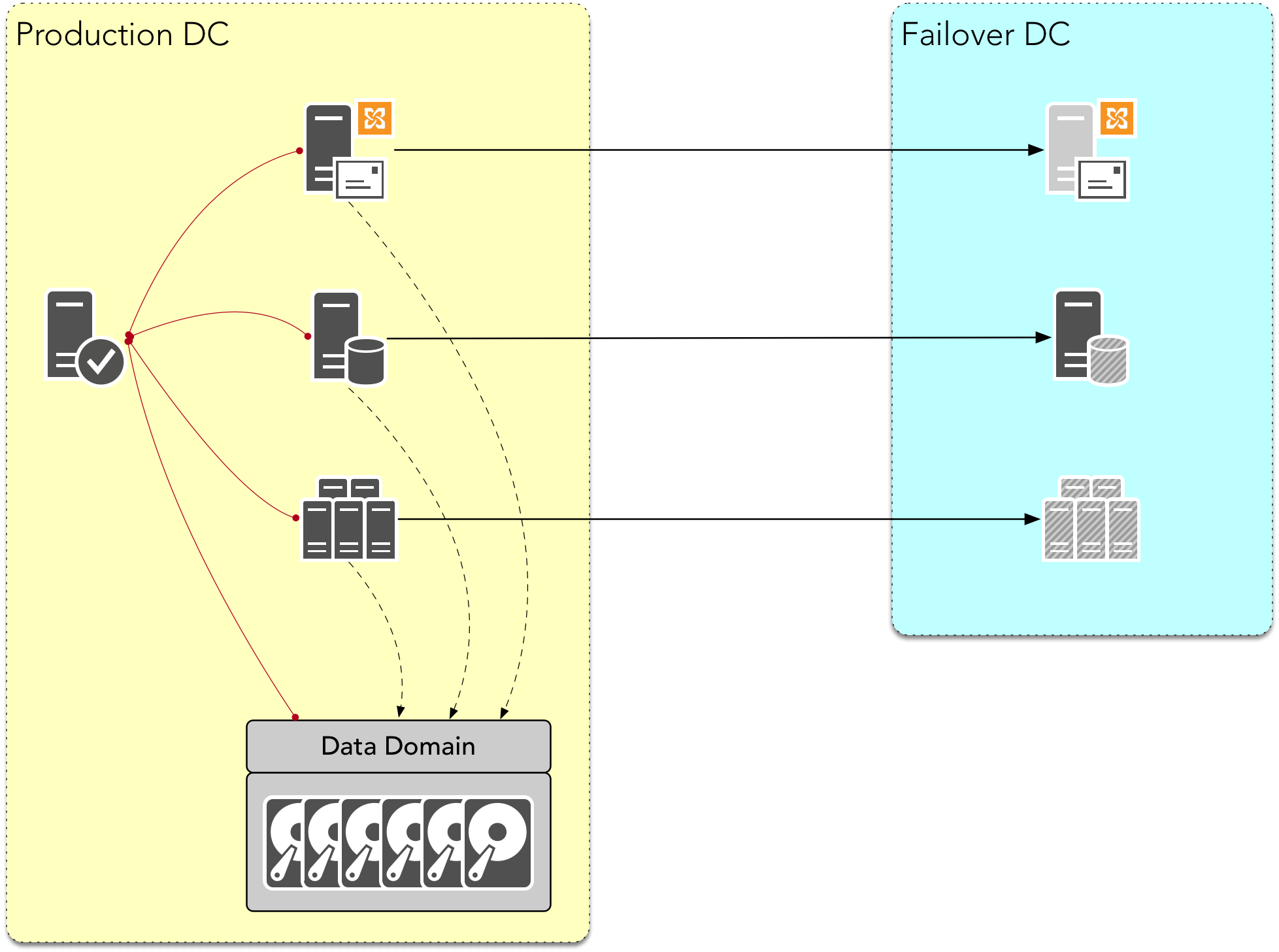
That’s the scenario where you’ll hear someone from time to time still say they don’t need to replicate their backups. After all, if those servers are all replicated (let’s assume, for the benefit of the doubt, the servers are replicated synchronously), then you don’t need replicate the backups, too. Right? Wrong.
I’d put it to you there are still reasons why, in the above configuration, you’ll want to replicate your backups. In fact, there’s two key reasons:
- Operational continuity.
- Historical recoverability.
Let’s consider them both.
First, there’s operational continuity: sure, in this situation if your primary datacentre burns down, you can transfer operations from production to the failover datacentre. That’s your day 1 response. What happens with day 2? How do you then go ahead and backup your environment when you’re running in the failover datacentre?
To start with, the picture above needs to be fleshed out. Presumably, in the “whole datacentre has burnt down” situation, our actual failover DC would look at least like the following:
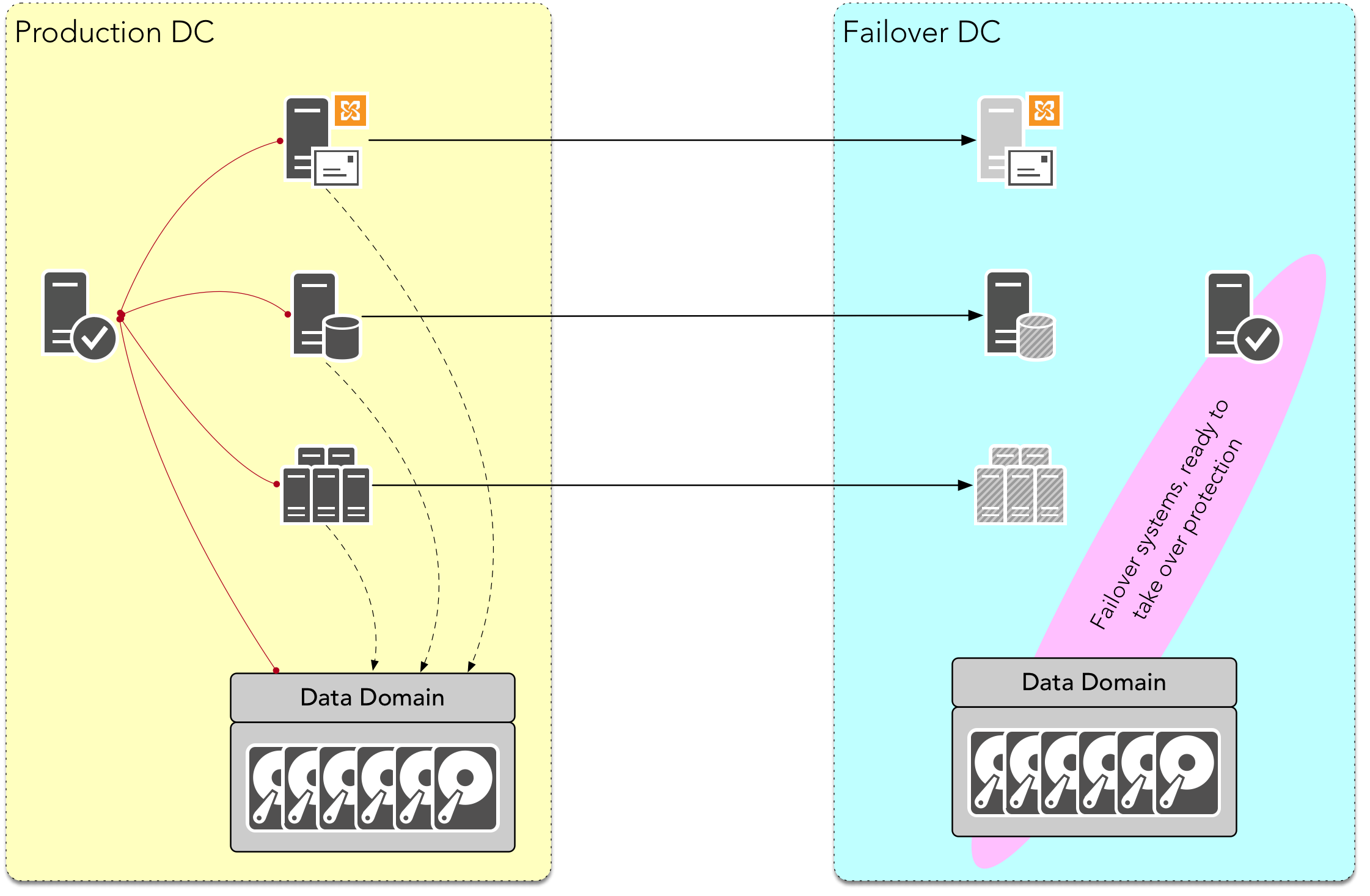
So in this situation, in the event that we’ve switched operations from the production datacentre to the failover datacentre, we’ve got a standby backup server and a standby Data Domain ready to start receiving backups. That solves the operational issue I’m referring to, right? No, it doesn’t.
There’s still some problems with this view from an operational perspective, and I can list them pretty quickly:
- If we’ve not been replicating the backup configuration from the production backup server to the failover backup server, we might have a lot of initial configuration after the day-1 failover just to get systems configured for backup.
- Even if we have been replicating the backup configuration, with there being no replica copy on the Data Domain, then the backup server’s index and media database are going to be inconsistent with what media is available. That’s a nasty problem.
- Let’s say it’s a “from scratch” configuration. So, you’ve just failed over between datacentres, there’s undoubtedly critical attention being paid by the business to the infrastructure, and the near-to-first communications are going to be:
- “Dear Users: It may take us a few days to get backups configured again. Please be careful.”
- “Dear Business: When we do get backups configured, everything is going to be a new, first full backup, and that may take longer to complete.”
Operationally, this process is a mess. That alone should be a good enough reason to ensure that the backups at the production site are replicated to the failover site. If it’s not, I’ll give you the other good reason, too: history.
Unless you have a very odd backup configuration, your backups sitting on the production Data Domain system are not just going to be today’s backups, or last night’s backups. Logically, it’s more going to resemble something such as the following:
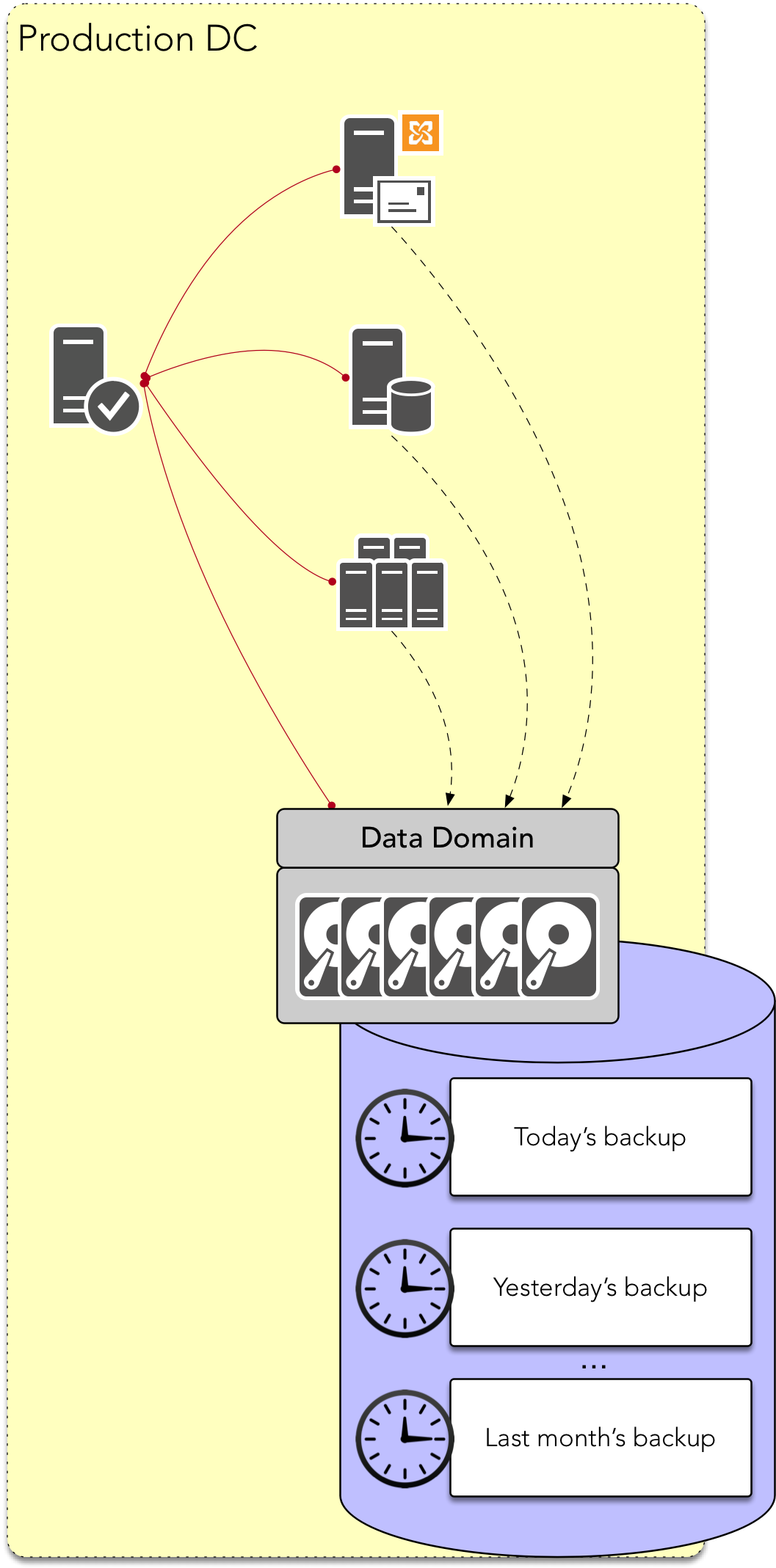
This is the nature of backups, particularly online backups. If a fire sweeps through your datacentre and destroys protection storage, it’s not just going to destroy the most recent backup that was sitting on protection storage, but all the backups that were sitting on the protection storage.
When you’re replicating systems from the production site to the failover site, there’s a good chance you’re replicating deletes and overwrites as well as appends and inserts. You may have a little bit of snapshot space retained to provide a level of historical access, but the chances are that’s going to be substantially smaller than what your backup retention will be – even for short-term, operational recoveries. Sure, your currently active data will be sitting over at the failover site, ready to start being used, and ready to start being backed up, but yesterday’s backup, the previous week’s backup, and that copy generated 3 weeks ago won’t be available – and if the business ever needs to recover from anything other than the most recent backup, you’ll be up the proverbial creek without a paddle.
And that’s why you always make sure you replicate your backups, even if you’re replicating the production data as well.
This is the sort of content I cover in my book, Data Protection: Ensuring Data Availability. For more information about how to design a rock solid data protection environment for your business, be sure to check it out.