On your marks
I’m not all that interested in sport. I grew up in a sports-mad family and spent a disproportionate amount of time exposed to sports as a kid, and at 44 I’d like to think I’m still balancing out by avoiding sport. But over the weekend, I watched the Formula 1 in Melbourne (on TV, not live at the track). The sad thing about Formula 1 of course is that they go so fast it’s seemingly over not long after it began.

Racing cars is fun, I guess. I’ve even sat on the edge of a Formula 1 car thanks to an EMC sponsored trip to Milan for the launch of VNX2 (that was before I worked for EMC/Dell EMC). (Getting in wasn’t an option, of course, F1 drivers are like jockeys – they need to be lithe, something I’d never be accused of!)
But racing backups is a lot more fun when you’re a data protection geek, so I wanted to kick the tyres again around regular backups, parallel savestreams (PSS) and block based backups (BBB) for dense filesystems again. You see, the last time I did performance tests along those lines, I wasn’t running DDVE in my home lab, so it was being backed up to regular AFTDs.
Get Set…
So what would I be testing with? I used NetWorker 9.2.1.1 as the backup server, running on a Linux virtual machine with 16GB vRAM and 2 x 2.2GHz vCPU. I used the same version of NetWorker for the client software, too.
For Data Domain, I used DDVE 3.1 (DDOS 6.1.0.21) – that’s also got 2 x 2.2GHz vCPU, and 6GB of vRAM. It sits snugly on a 960GB SSD presented up from VMware.
The Linux client I used for the testing was installed with CentOS 7.3 for compatibility with the BBB module. I installed that on a separate ESX server, sitting on RAID-5 storage presented from 4×7200 RPM 2TB SATA drives connected via Thunderbolt2. The Linux host was given 4GB vRAM and 2 x 3.5GHz vCPU. In addition to the regular filesystems on it, I created a 100GB logical volume, formatted ext4 with a 1KB block size, and an inode count of 40,000,000. The ESX server it was running on was connected via 1Gbit networking with the other ESX server hosting NetWorker/DDVE.
Next, I created 1000 x 1KB files from /dev/urandom, each 1KB in size. I then setup in the test area a directory structure of:
- 4 ‘base’ directories
- 90 subdirectories
- 100 subdirectories
- In each subdirectory, a copy of those 1000 files.
- 100 subdirectories
- 90 subdirectories
When that finished copying, there was still a chunk of inodes left, so I pushed a bit more, created a 5th base directory, and copied subdirectories 1..29 from one of the other base directories into the 5th one.
The net result was a highly dense filesystem of reasonable regular filesystem layout and while individual files were random content, there was as you would expect from a big dense filesystem, a reasonable amount of deduplicatibility across the entire content.
(After each test, I also erased the NetWorker saveset(s) generated, and ran a filesystem clean operation on the Data Domain, then rebooted the client, to ensure everything was reset to level again.)
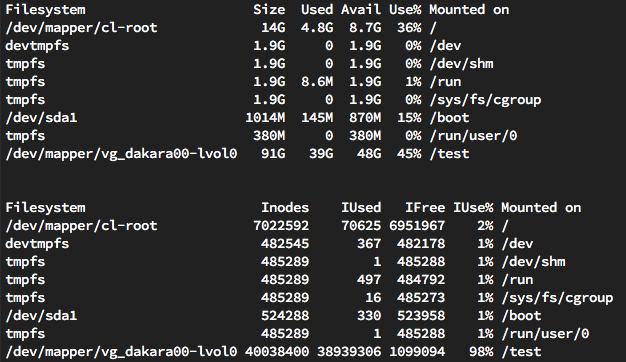
Above are two ‘df’ outputs for the client – the first, df -h shows the capacity consumed in the /test filesystem, and the second, df -i, shows the number of inodes consumed in the /test filesystem. Doing a find across the filesystem after everything was created showed:
- 39,296 directories
- 38,900,001 files (including the creation script itself)
Go!
So, we’ve got a dense filesystem – tens of millions of files in just under 40GB of storage. Is this a realistic filesystem? Do we see filesystems like this in the real world? You bet we do. Order processing systems that dump a 1-5KB PDF file for every order dealt with (hopefully!) arranged by year/month/day are not uncommon for instance – and there’s plenty of other systems that over time generate lots of little files, resulting in filesystems that take a long time to protect.
The reason those filesystems take a long time to protect is that they’re left to run as a normal backup when there are other, better ways to go about it.
The normal backup
The normal backup was a configuration where the regular NetWorker client software was used, with the client’s saveset defined as just ‘/test’. This resulted in a single-stream walk of the entire filesystem to back it up. Backup time was: 7 hours, 5 minutes, 23 seconds.
In terms of dealing with dense filesystems, that’s sort of not bad. That’s approximately 5,486,816 files per hour being processed and backed up, which isn’t something you’d sneeze at.
But we know we can do better, right? Otherwise I wouldn’t be writing this blog!
The parallel savestreams backup
The next test (after clearing off the backups from the Data Domain and rebooting the client) was the PSS backup. That’s where NetWorker deploys multiple walkers for the filesystem (I left it at a default of 4), relying on the fact that in cases of dense filesystems, the underlying disk structure isn’t the performance issue – it’s invariably the cost of walking the filesystem.
Enabling PSS is very straight-forward – just edit the client properties and you’ll find the option under “Globals (1 of 2)”:
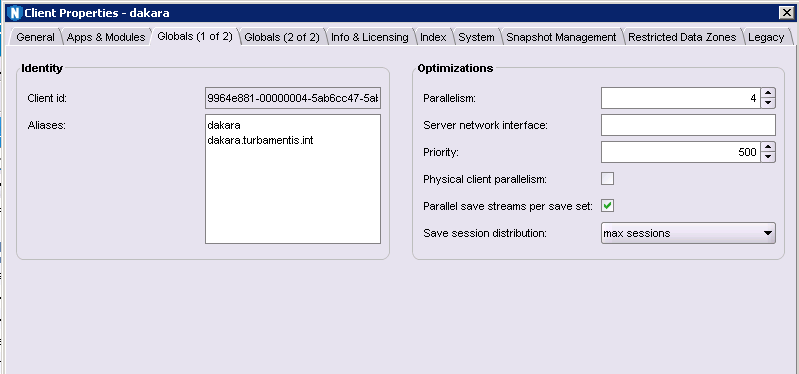
So, what was the backup performance with PSS enabled? 2 hours, 36 minutes, 43 seconds. That’s certainly a nice improvement – backup time reduced from over 7 hours to under 3 hours from our first attempt, clipping along at 14,893,120 files per hour. That’s pretty good.
Block based backup
Enabling block based backup meant ensuring the ‘lgtobbb’ package was installed. Block based backup is where we bypass the filesystem entirely, and access a snapshot of the filesystem at the block level. You make sure PSS is turned off, then turn on the Block Based Option, which is found on the ‘General’ configuration panel for the client:
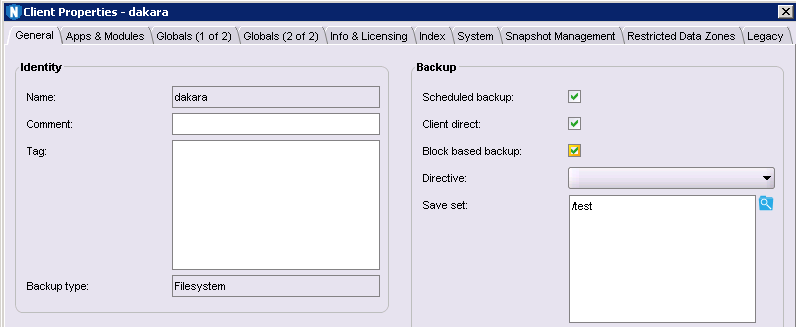
So, with the previous backups deleted, the Data Domain filesystem cleaned, and the client restarted, I was ready to start the final backup. How fast did that run? Well, if the first test was like me driving my car around a racetrack, then the second test was an F1 racing driver taking my car around the racetrack, and, well, the third test was like an F1 racing driver taking an F1 car around the track: 7 minutes and 54 seconds.
I know, you probably don’t believe me, so here’s the actual savegroup completion notification:
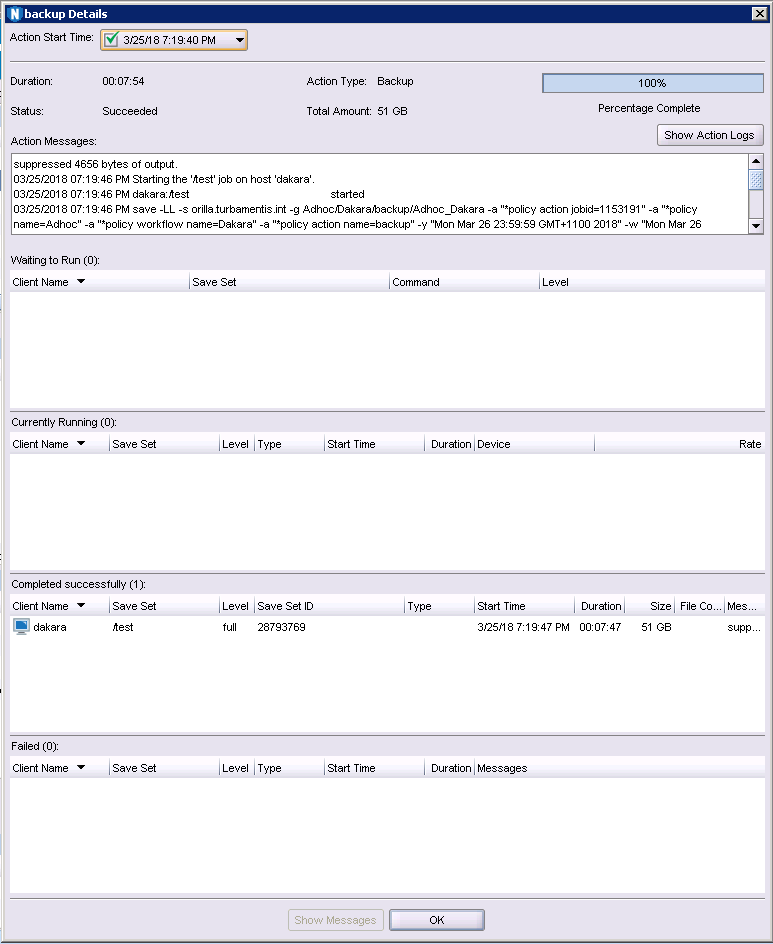
That brought our backup time down from over 7 hours to under 8 minutes. While we’re not backing up the files themselves in this instance – we’re backing up a block image – if you wanted to work out what that means in files/hour compared to the first two, well, it’s the equivalent of 295,443,046 files per hour.
We are literally talking about performance increases of orders of magnitude better – and I mean literally, not figuratively.
The Winner’s Podium
If there’s one thing I’ve noticed over the years, it’s a tendency to not architecturally re-visit backup environments except when there’s a major infrastructure refresh. I think this is self-limiting in the extreme. For instance, I’ve been told that occasionally NetWorker is “old tech”, compared to some startup vendor – when in actual fact NetWorker is capable of blowing the pants off the startup vendor in terms of performance, it’s just that it’s still configured for backup the same way it was on deployment 5 years ago. Times change, and so should your backup configuration.
Our environments aren’t static. If performance issues creep in over time, one of the most likely, or at least equally likely causes, is data growth. What seemed like a straight-forward filesystem backup 3 years ago when an environment was commissioned may have become a dense or super-dense filesystem as content continued to be built up on that filesystem. Not re-evaluating backup options to take into account enhancements to the underlying technology just invites SLA problems for you.
In the example above, both BBB and PSS represent a substantial performance increase compared to the original backup time. Which one you choose depends on your SLAs, your target storage, and your recovery granularity. But choosing to remain with a conventional, single-streamed backup when there are better options available? That’s definitely a mistake.
I’m now wondering how much of the extra backup time for a conventional backup is taken by the resources needed to write the metadata into the two databases.
Comparatively very little time. The issue is the filesystem density and performance, not the NetWorker databases. Remember that PSS generates fully browsable indices as well – in fact, it’s going to be hammering the client file indices harder than a conventional backup because it’s running multiple, parallel streams. If we can bring the backup down from over 7 hours to under 3 with PSS, we’re not looking at an issue in the NetWorker databases.
Excellent news, it’s a question that’s bound to be asked, File system density is, and always has been a problem, but this gives reproducible evidence that proves the point. And it’s not a Networker issue.
I need to implement a backup of a VNX based NAS. I’m hoping that some of these improvements can be taken advantage of to reduce job time.
Hi Carl,
Unfortunately the NDMP protocol doesn’t extend to allowing options like PSS (though there’s some funky stuff available with Isilon fast backup options). IIRC VNX does support a block option for faster backups, but recovery from block backups via NDMP has some limitations you’ll want to be sure of first.
You might also want to look at NetWorker NAS snapshot management to integrate a snap and backup schedule to suit data protection requirements.
Cheers,
Preston.