What do you do in the event of a disaster, either across your environment, or within your backup environment? What do you do when the NetWorker server itself stops working? Maybe you ran a physical server with DAS RAID which lost too many drives, or maybe an OS patching exercise resulted in crashing on reboot. The net result is the perennial challenge in backup and recovery – how do you recover the machine that normally does the recoveries?
NetWorker is flexible enough that there’s a plethora of options, either ‘home-grown’, or official. I’m going to run through examples of three different ways you can do it in a fully supported configuration.
Traditional Disaster Recovery
The traditional disaster recovery approach has evolved a little over the years, but remains effectively quite similar: recover the NetWorker server’s configuration, media database, and indices.
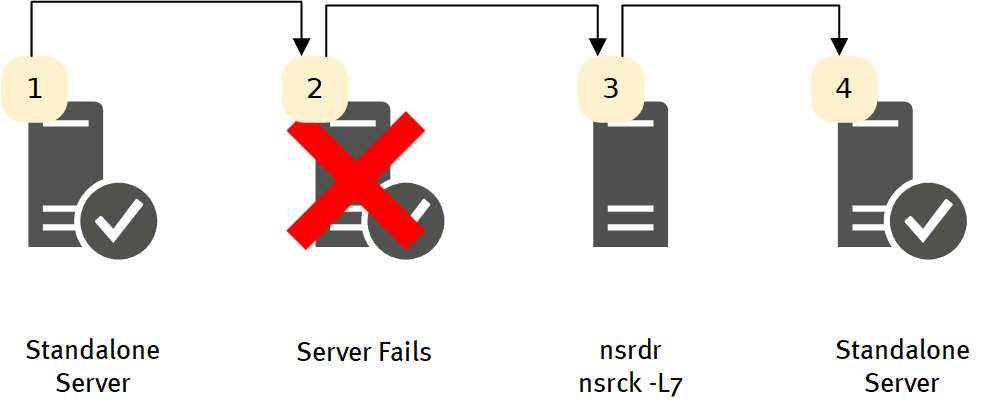
As things go, this is a pretty straight-forward process. I remember back in the days of NetWorker 5.x and earlier, it felt like a hairier process – but that might have also been because I was younger and less experienced – or maybe because it always involved tape. These days, even the ‘bootstrap recovery’ process is made simpler by using nsrdr.
The pros of this option is that it requires the least investment – you’re not maintaining a seperate DR server or anything like that (although, you can), so if you run a low-budget environment, it’s most likely the option you’ll choose to go with. Your server recovery time here though will likely be measured in the hours or more, depending on whether you need to source any hardware parts, rebuild operating systems, etc. If you’ve got large indices, that recovery time may also take a while, or you may choose to recover some indices to allow critical recoveries, and process the rest over a slightly longer window. Regardless, it’s a flexible option, though it may take a while.
It’s always a good idea to know how to run this option though. It’s just basic preparedness, after all.
Clustered NetWorker Server
Another option you can consider is to cluster your NetWorker server at the operating system level. This allows you to effectively have an active/passive (compatible) OS cluster running your NetWorker server environment, with shared NetWorker regions (config, media database, indices, etc.) between the cluster. The obvious advantage of clustering your NetWorker server is that you can get it back up and running in considerably less than an hour – often just minutes – if a node in the cluster fails, or you need to do maintenance work on a node.

As is always the case with clustering, you’re protected from some types of failures, but not all. If someone goes and accidentally deletes the shared filesystem that contains the index, metadata and configuration regions, you’ll have to fall back to the traditional NetWorker disaster recovery to get this information back. (Clustering for instance is no defence from Ransomware.) However, for the sorts of operations that you look towards clustering to protect you, you’ll more often than not find in the event of a failure that you’re restarting backups on the other node in the cluster in less than 15 minutes.
Rapid Recoverability via Continuous Data Protection (CDP)
If you need to provide really rapid recoverability of your NetWorker environment, another option that’s available to you is RecoverPoint. In this example, I’m going to focus on RecoverPoint for Virtual Machines (RP4VM), because there’s no reason why your NetWorker server shouldn’t be virtualised in most environments these days, but you could equally achieve the same type of high availability via storage array integrated RecoverPoint.
I’ll start with a view of what the configuration would loosely look like:
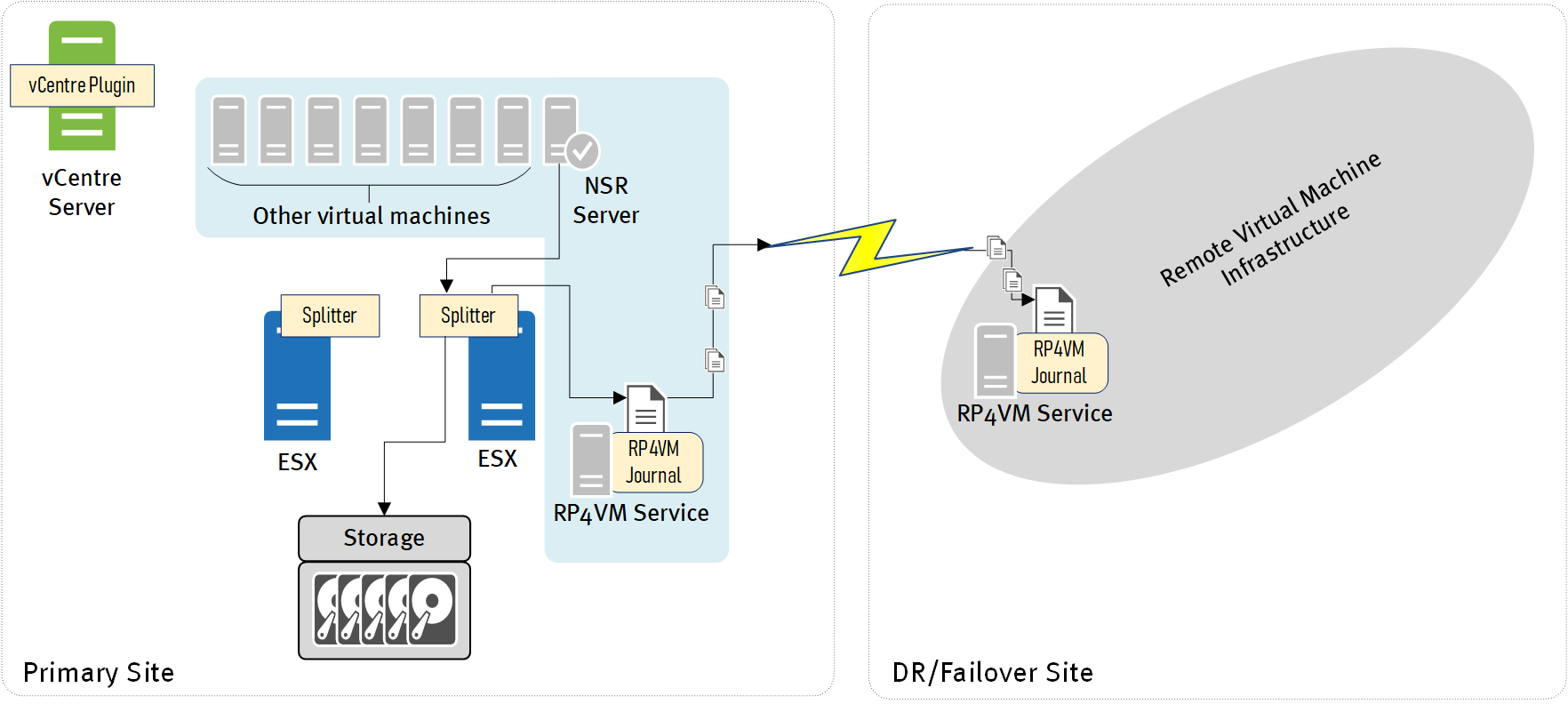
RP4VM works via a journalling system, which has several advantages:
- You can “rewind” – it’s literally referred to as providing Digital Video Recorder-like (DVR) capabilities.
- Write order consistency is guaranteed – so it doesn’t matter if a particular region of the virtual machine keeps getting updates (e.g., the media database), those changes will be replicated via the journal in sequence.
- It’s not just for a remote replica – you can instantiate a new virtual machine locally to a specific point in time, or rollback the actual virtual machine to a specific point in time, so it provides local as well as DR to an alternate site.
- You can test as well as actually perform DR operations. This means you can instantiate a test virtual machine of your backup server, isolated from the network, allowing quick recoverability testing (or maybe even quick upgrade testing), without impacting the primary service.
RP4VM is fully supported as a DR method for NetWorker as of NetWorker 9.2.1 (you can request evaluation for qualification of support through your local Dell EMC presales team for earlier versions of NetWorker, or just simply upgrade to a version that supports it) – you’ll even see details about it in the NetWorker Server Disaster Recovery Guide, it’s that supported. RP4VM hooks into the VAIO API (VMware API for IO filtering), meaning it has an officially supported splitter installed on each ESX server that’s going to host RP4VM protected virtual machines. As writes happen to the virtual machine, the splitter sends a copy to the journalling system as well, which can be (and usually is) replicated to an alternate location to provide remote DR capabilities.
When we take all this in mind, what we get is NetWorker server rollback and recovery that is extremely fast compared to even clustering – but also covering issues with indices, configuration, etc., too.
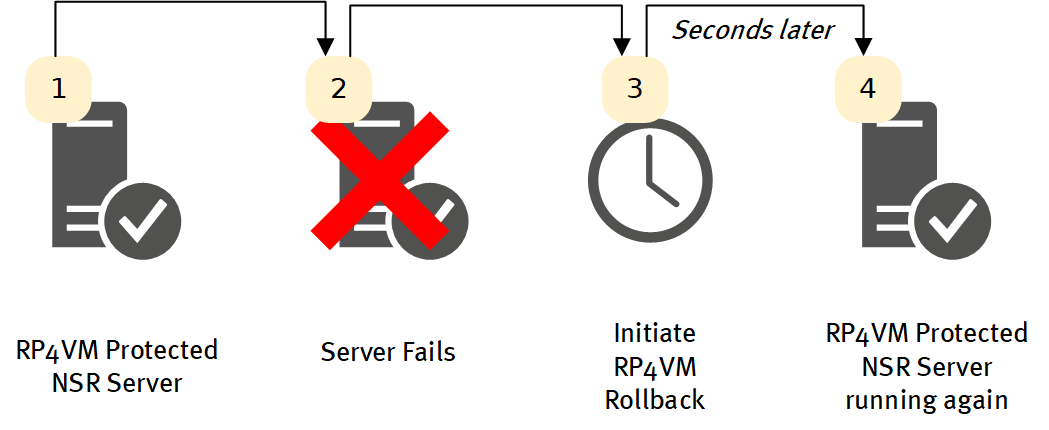
So whereas traditional NetWorker server DR may take hours or more, and clustering might take 15 minutes or more to get back up and running, with RP4VMs, your NetWorker server could be back up and running within seconds of a failure.
But why would you go to the effort of configuring RP4VM just for your NetWorker server? The answer is simple: you probably wouldn’t. RecoverPoint is there for rapid recoverability and rollback of any mission critical system. Like its physical equivalent, RP4VM also understands consistency groups, so that headache of a SharePoint farm that needs multi-host consistency in order to DR between sites? No problem – put all the virtual machines that make it up into a single RP4VM consistency group, and it will take care of the synchronisation and replication between sites without missing a beat. If you run a mostly virtualised environment, RP4VM is, in fact, the sort of system that you should be installing within your environment to take your data protection and systems availability to the next level. (In fact, it can provide a much more granular and flexible replacement to SRM, all while still being fully administered from within vCenter.)
Here’s the really cool thing about RP4VM these days – while you can buy licensing for it separately, it’s included in Data Protection Suite for Virtual Machines, the socket-based licensing model available from Dell EMC. If you’ve got a DPS for Virtual Machines socket-based license model, you already have the right to use RP4VMs.
In Summary
NetWorker is always about flexibility, and disaster recovery options are no different on that front – you can choose the basic traditional recovery model, you can work with clustering, or you can look at a extending data protection into a more holistic approach, providing CDP not only to your NetWorker server, but also to other mission critical (or even all) systems within your environment using RP4VM.
I was looking for it, Thanks Preston..
Great read Preston. Thanks for sharing.
My $0.02 on backup server virtualization — I wouldn’t recommend it without understanding the risks, however minimal. It sounds great in theory, since VMware environments are supposed to be highly redundant, but in my experience, this does not always translate in practice.
I’ve been involved in several situations where a VMware environment went down, and having a virtualized NetWorker Server under those circumstances is obviously not ideal. I suppose it’s fine if you have a standby physical server that you can use for an NSRDR under those circumstances, but as a backup admin, I suggest against leaving all your eggs in the VMware basket.
Thanks for your comments Rich. I don’t fully agree with them though – virtualisation has been around for long enough and we’re seeing a high enough saturation that quite frankly it should be “bread and butter” in the infrastructure stakes within an organisation. If the IT teams aren’t able to get virtualisation rock-solid/stable, then whether or not the backup server is virtualised is probably pretty low down on priorities, because the environment isn’t being run right. I’d say in this day and age, any environment that can’t keep VMware environment is probably facing down the end of the “Cloud first” barrel, or should be seriously looking at Hyperconverged to pull themselves out of an ongoing fire.
Great Post Preston, Just about to chat to my customer about performing Premortems in their environment to cover this off.