Backup, archive and HSM are funny old concepts in technology and business. We’ve been doing backup for literally decades, and if you go back to paper based document/records retention systems, we’ve been doing archive for a lot longer than that. HSM started in mainframe days, so it’s been around for quite a while, too.
Yet it’s interesting how often you’ll see backup and archive used interchangeably, or for that matter, archive and HSM (Hierarchical Storage Management) used interchangeably. One of the most common places I see ‘archive’ misused for backup is actually in RFPs (Requests for Proposals). It’s honestly quite amazing how many companies issue RFPs asking for a backup and recovery platform, but they refer to it as an archive platform throughout the entire document. It sometimes leaves me thinking: what would they do if everyone interpreted it at face value and gave them a proposal for an archive instead of a backup platform?
So, let’s stop for a moment and consider the differences between the three.
There’s one key differentiation we can establish between them immediately, one that sets backup apart from the other two, so we’ll start with backup – a topic, as you might know, is pretty near and dear to my heart. Here’s the definition of a backup:
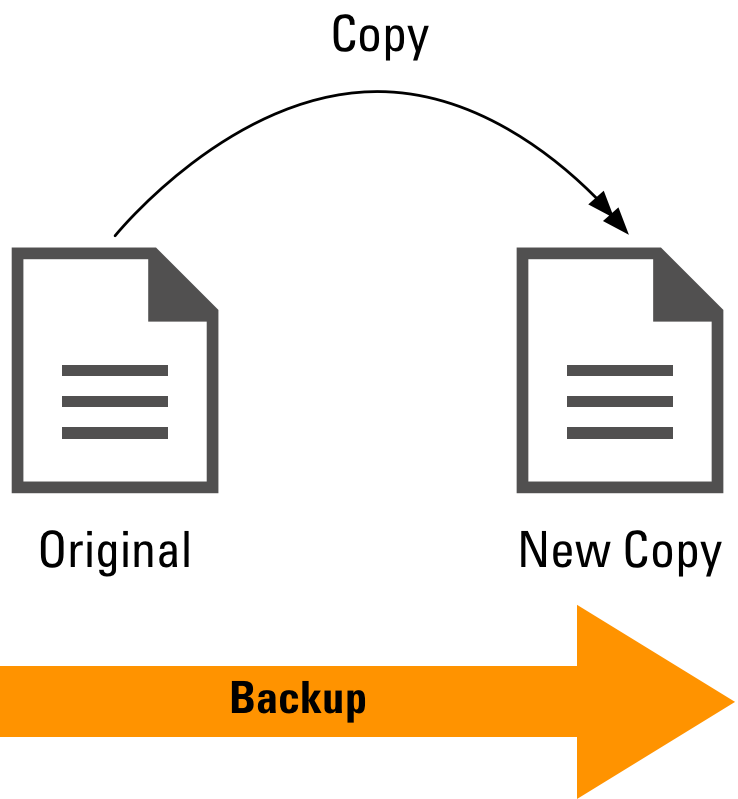
The simplest possible explanation of a backup is that it is a copy operation – it reads the source content, and creates a new copy, which can be used, in the event of the source content being lost, to recreate the source.
Now, an archive is not a backup (regardless of what some RFP writers may think). This, effectively, is an archive:
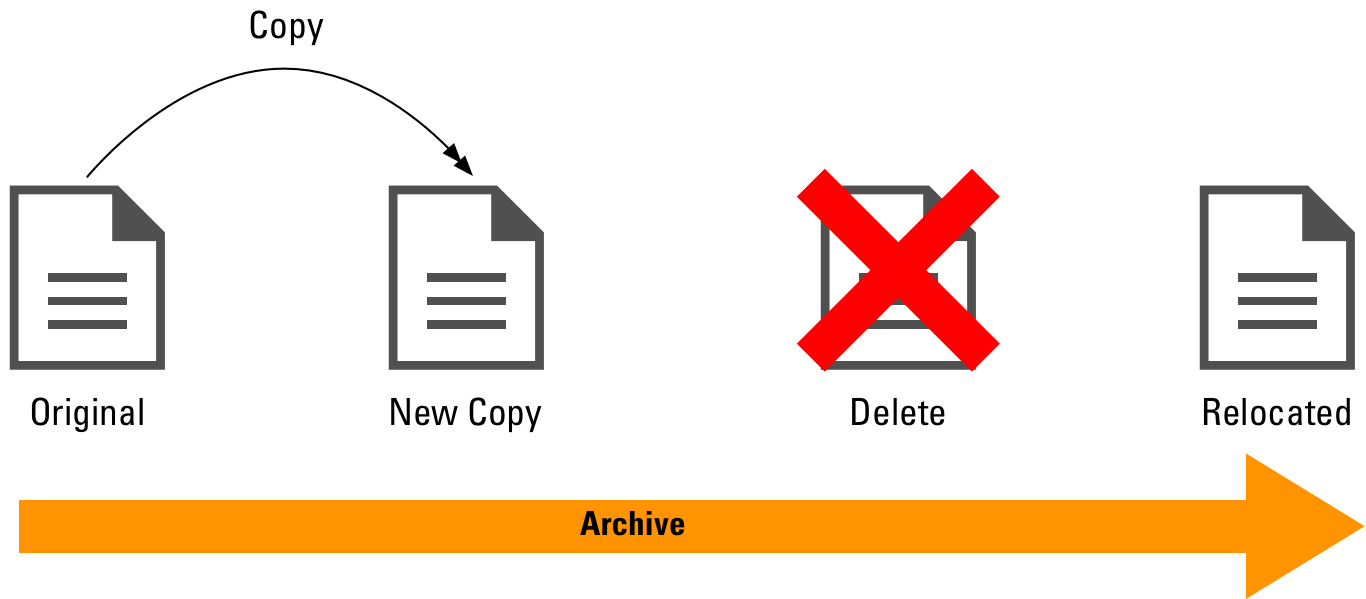
So, I’m being slightly cheeky in suggesting the delete immediately follows the copy operation. It does for some interpretations of archive, and it doesn’t for others. It’s perhaps a logically cleaner operation when it does, but there can be reasons to not do it immediately. Basically, the archive operation is: “Take a copy of the content. At some point in the future we will delete the original content, knowing there is an archive copy available.” Now, a decade or more ago when primary storage ran at a premium, the archive usually would mean immediately deleting the source once the destination copy had been verified. Now though, it might not – consider, for instance:
- Email archive: Usually the data is captured and ‘archived’ as soon as it enters the system, then a simple delete policy can be applied later (e.g., delete from email after 90 days).
- High volume long term retention: Medical imaging data is a good example here – you might write two copies of the data immediately as it’s received; one copy gets written to a traditional filesystem, and the other gets written to object storage. You retain the filesystem copy for say, a month, so that if someone wants to access it (say, to send a copy to a doctor, or a specialist), it can be done quickly. However, after a month, the copy on filesystem storage is deleted, knowing there’s the copy in object storage.
In both cases, you can see that the dependency for ‘seamless’ access belongs to the user-facing application. The email archive will generally result in a plugin in the email application to retrieve archived email content – and likewise for the the medical imaging software. In both cases, it’s highly specific. Without that actual application or plugin, the archived data won’t be returned. In simpler systems, it’s entirely up to the end user to find that data. This will be particularly so in things like engineering and design companies: projects get archived when they’re complete (or a certain time after they’ve completed), and users will know to go looking on the ‘archive server’, etc., if they want to access content from that prior project.
Now, HSM is kind of like archive, but more generic in terms of access profile. It looks more like the following:
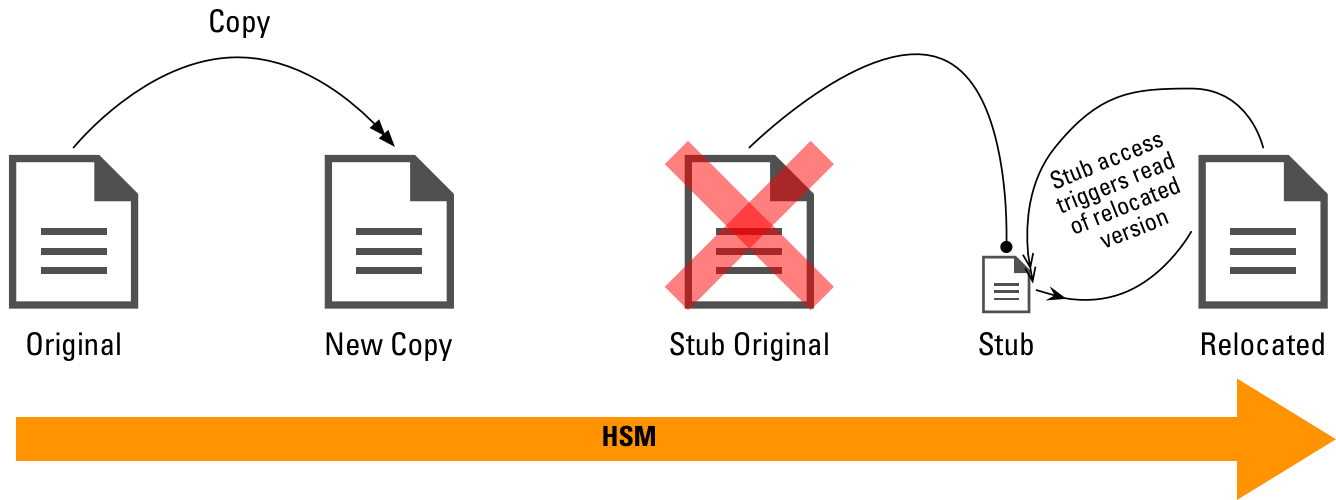
In this scenario, once that copy has been made, a stubbing operation is performed. The stub replaces the original content, and if a user accesses the stub (e.g., double-clicks on the stub for a Word document), the archived document is automatically returned, and either read into memory and assembled as a new document, or replaces the stub. Either way, if the stub is subsequently overwritten, the entire HSM process is effectively restarted.
Compared to archive, this is a broader tiering operation. In an archive operation, the retrieval is very specific to the application that received the data; HSM on the other hand is more related to extending traditional filesystem storage (though it can potentially be used on block storage as well) to push out less frequently used or even unused data to a cheaper and denser storage tier, regardless of what application accesses the stub. In fact, HSM will even usually have very specific hooks to recognise backup applications, so that when a backup application tries to read the stub, the HSM solution will send the stub, rather than retrieve the original content – otherwise you’d be forever recalling content every time you backup.
So that’s the simple overview: backup, archive and HSM – they all take a copy of the data, but it’s what they do with that copy, and how it affects the original, that contributes to their core function within your organisation.
Don’t forget, if you want a really comprehensive understanding of data protection as a holistic subject, check out my book, Data Protection: Ensuring Data Availability.