As environments scale, so too has NetWorker grown in its ability to scale. The latest version of NetWorker can scale to thousands of physical clients managed in a single datazone, or tens of thousands of virtual clients managed in a single datazone – or any combination thereof.
Something I get asked from time to time is: when we go client direct (e.g., with Data Domain), why do we recommend that storage nodes are deployed? I can answer with a simple “for local device management”, but I want to dig in more on that and explain in greater detail to convince you that even though they’ll be light-weight (since they don’t have to stream data), it’s still worthwhile deploying storage nodes, particularly in a multi-site environment.

I guess you can say the other short answer is teamwork: NetWorker can scale to large numbers of clients (physical and/or virtual) when its deployed in a way that makes optimum use of its architecture. As an example, I’m going to consider a 3-site configuration:
- Primary site
- Disaster recovery site
- Satellite Site
The primary site and disaster recovery site replicate backups between one another, and the satellite site replicates its backups into the primary site – a fairly standard sort of configuration, in reality. Now, we also need to do the following sorts of backups:
- Primary site:
- Dailies/weeklies
- Monthlies
- Dev/Test
- Disaster recovery site:
- Dailies/weeklies
- Monthlies
- Dev/Test
- Satellite site:
- Dailies/weeklies
- Monthlies
Since we’re replicating between sites, that implies we’ll not only have NetWorker backup devices, but also clone devices where applicable. NetWorker’s approach to throwing backups at Data Domain is straight forward: create some devices, and for each pool/collection of devices for that pool, NetWorker will typically round-robin between the devices as new savesets start until we hit the max target session for each device.
So, let’s say we go with a basic sized environment where we deploy devices as follows:
- Primary site:
- 2 x Daily Backup (BDaily1, BDaily2)
- 2 x Monthly (BMonthly1, BMonthly2)
- 1 x Daily Clone (CDaily)
- 1 x Monthly Clone (CMonthly)
- 1 x DevTest Backup (BDevTest)
- 1 x DevTest Clone (CDevTest)
- Failover site:
- 2 x Daily Backup (BDaily1, BDaily2)
- 2 x Monthly (BMonthly1, BMonthly2)
- 1 x Daily Clone (CDaily)
- 1 x Monthly Clone (CMonthly)
- 1 x DevTest Backup (BDevTest)
- 1 x DevTest Clone (CDevTest)
- Satellite site:
- 1 x Daily Backup (BDaily1)
- 1 x Monthly Backup (BMonthly1)
At minimum you’ll get 1 x nsrmmd per device at all times. If you know your NetWorker nomenclature, nsrmmd stands for the NetWorker media multiplexer daemon, and that coordinates getting data to write to a NetWorker device. If we’re in a “classic” storage node where backups stream through storage nodes (i.e., a traditional 3-tier architecture), then nsrmmd actually receives the incoming client data and coordinates getting it written to the device. In a Data Domain style environment, or more generally, anywhere that Client Direct is supported, the primary purpose of nsrmmd is to check and confirm a file path on the protection storage for an incoming client direct request, provide that file path to the backup client, then step back out of the way and let the client send its data through to the storage system. (Which will be deduplicated prior to transmission if sending to a Data Domain.)
So, what would our configuration look like without a storage node at each site?
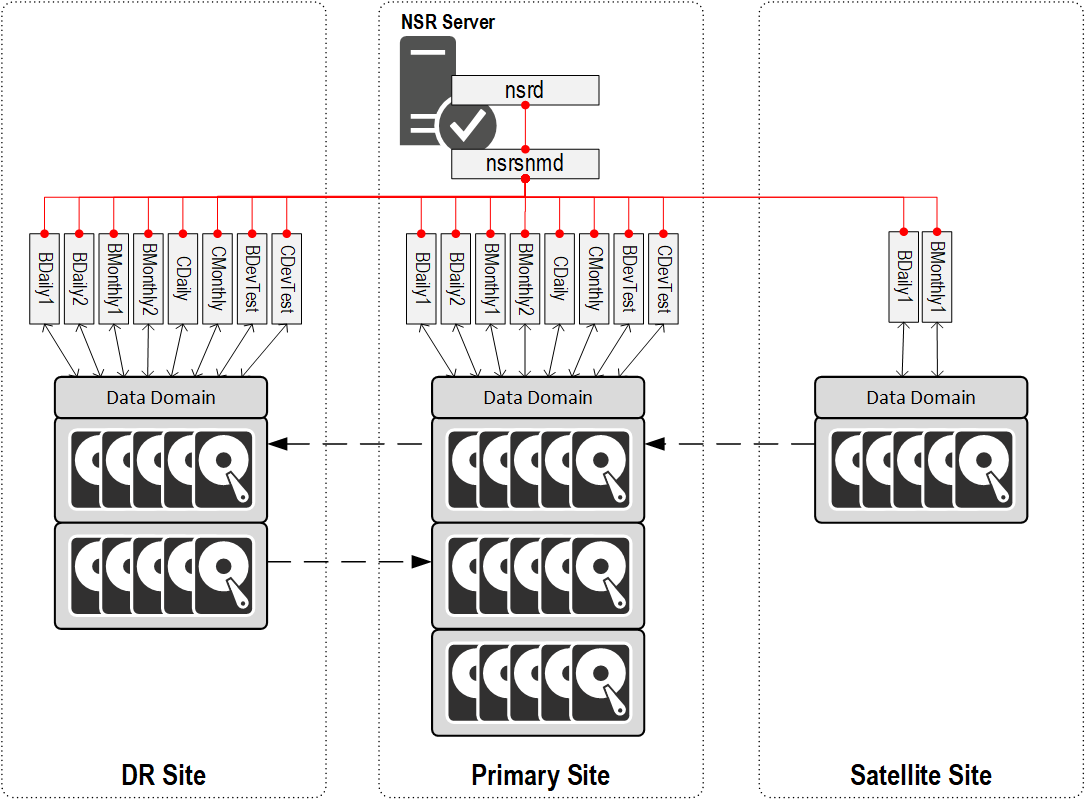
In the above, I’m assuming a 1:1 correlation between each device associated with a Data Domain folder and the number of nsrmmds – as I said before, this will actually scale up as we send more sessions to a device, so keep that in mind as you look at the example diagram. (Effectively, think of each device in the picture above as being both the device, and the first nsrmmd process.)
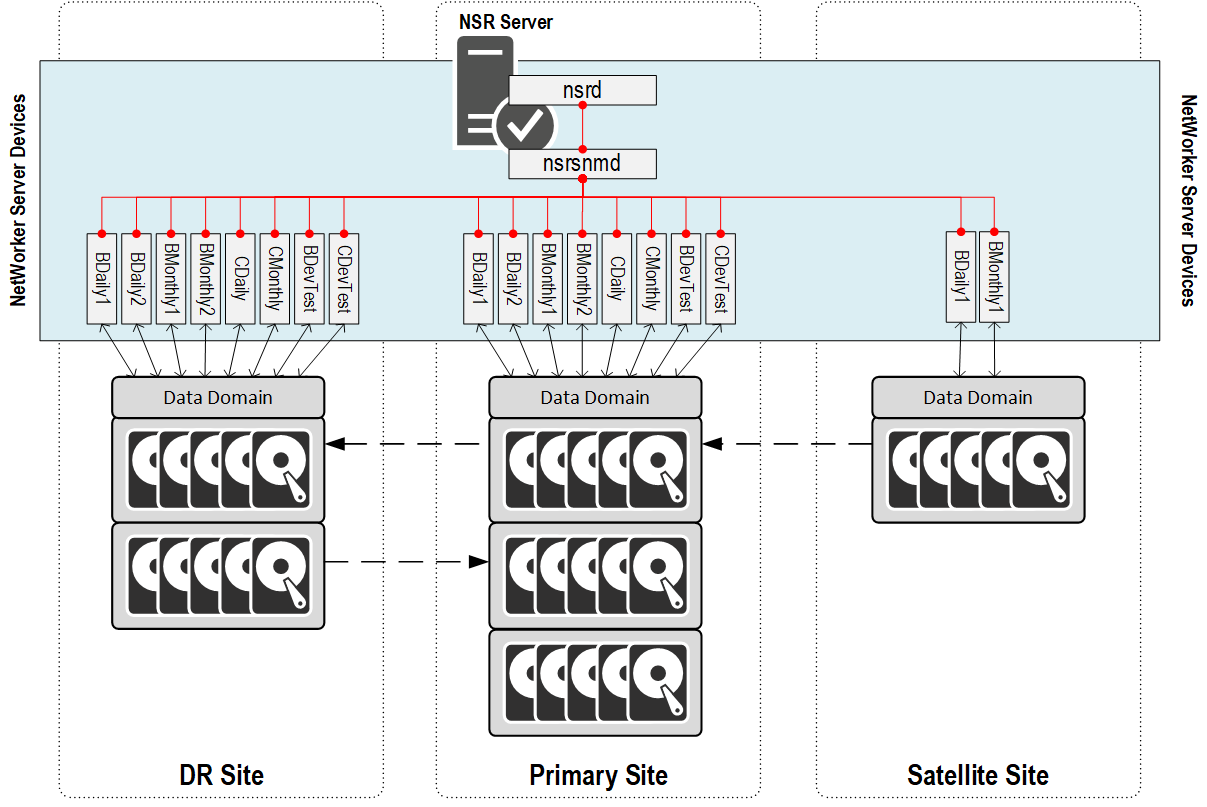
The NetWorker core process is nsrd, or nsrd.exe if you’re on Windows. (Astute observers will see a correlation between the core process and this website name.) Gone are the days when nsrd talked directly to nsrmmd processes; instead, now, there’s an nsrsnmd process for each storage node. So nsrd talks to nsrsnmd, which talks to the devices created on the storage node. When you don’t deploy a storage node, you still do: the NetWorker server is a NetWorker client and a NetWorker storage node in addition to its server functionality. So in this case, while those Data Domains may be at different sites, they’ll be treated as ‘local’ devices to the server in that there’s a locally spun on nsrsnmd talking to a bunch of locally spun up nsrmmds, each one facilitating connectivity between clients and a folder on the Data Domain Mtree. So, in reality, our diagram is probably better off described like this:
So ultimately, what this configuration does is ramp up the number of services running on the NetWorker server. Rather than spreading the load out, we’re concentrating the load, and making the server busy with things that architecturally it doesn’t need to be busy with. Let’s consider as well what happens when we then start seeing more sessions ramp up on individual devices – say, 2 x nsrmmd on each of the Daily devices at the primary site:
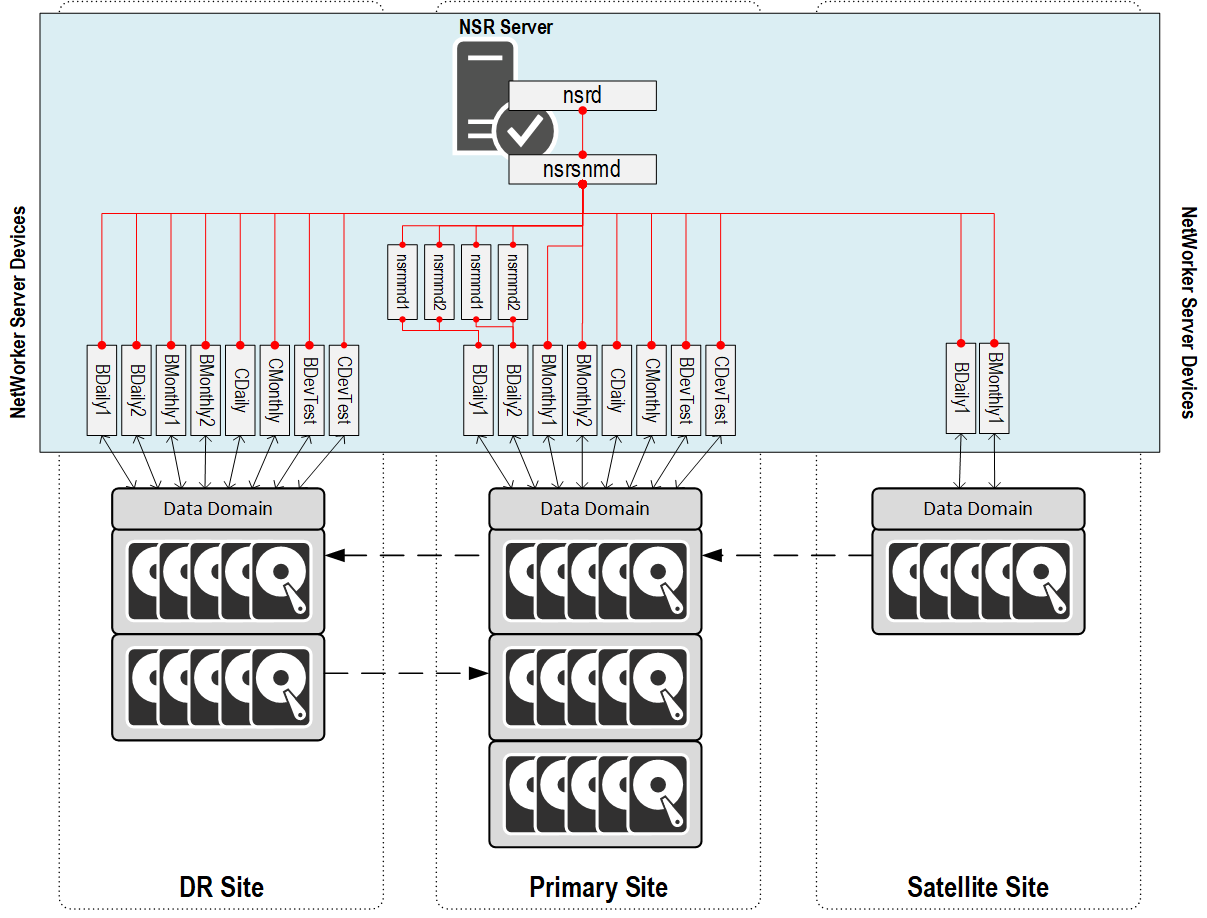
Don’t forget, there’s at least one nsrmmd running for each device being maintained, I’m just not showing it in order to keep the diagram simple. You should get the gist of it though – we’re increasing the workload on the server as we ramp up the number of sessions being run. Ideally, from an architecture point of view, we want to give the NetWorker server itself some separation from that so it can concentrate on client coordination, index management, etc.
So what happens when we insert a local storage node for handling that client/device/file path mapping with client direct? Well, suddenly our communications structure looks more like this:
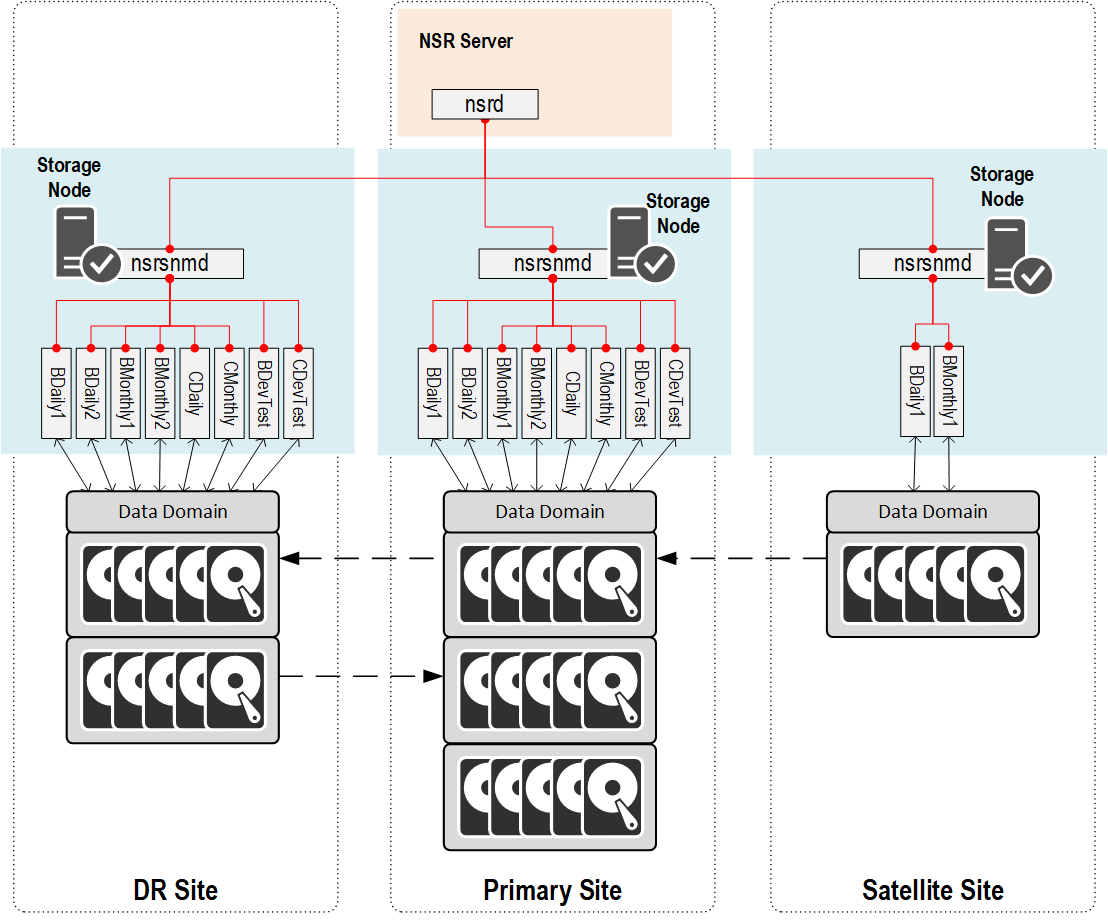
There’s still all the requisite number of nsrmmds running, but instead of a single nsrsnmd on the backup server having to coordinate access to every device we create in the datazone, the NetWorker server’s nsrd maintains contact with a single nsrsnmd on each storage node, and each storage node fires up the various required nsrmmd processes to talk to its local devices – i.e., the devices created on the Data Domain at the same site.
Remember when I said this was all about teamwork? This is exactly my point. As we scale out the number of current sessions we need to be writing, we don’t want to, and don’t need to ramp up the amount of work the backup server is doing. Its performance requirements and workload is significantly shielded from device management under this architecture.
Now, 9 times out of 10 we don’t need physical storage nodes, remember: we only need to fall back to a physical storage node in a few very specific situations, viz.:
- Tape out:
- Yes, VMware describe how you can present physical tape up into a virtual machine, but the knowledgebase articles should be prefaced in 96 point bold blinking text, “FOR THE LOVE OF EVERYTHING THAT IS BEAUTIFUL IN THE WORLD DO NOT DO THIS”. It’s nothing to do with NetWorker, it’s the simple fact that presenting a physical tape drive up into a virtual machine is fraught with caveats and challenges.
- Large NDMP Backups:
- Smaller NDMP backups can go through an appropriately sized virtual storage node, but if you’re pumping through hundreds of TBs, you’ll really want to make sure that the storage node is physical so it can be scoped to service the load without impacting the virtual environment. Remember, the NDMP protocol doesn’t understand disk as a backup target, so the only way it can go to a Data Domain Boost device is via a Storage Node providing NDMP masquerading.
- VLAN straddling where the Data Domain isn’t in the VLAN:
- In some situations you’ll have a configuration where, for some security reason, a Data Domain can’t be connected directly into a specific secure VLAN. In those instances, you’ll deploy a storage node in the VLAN with connectivity to the local clients and the Data Domain. If those clients have a lot of data, you will probably look at deploying a physical storage node.
So that’s the longer explanation of why you still deploy storage nodes even though they’re no longer part of the the data flow: but unlike third-tier servers in other products, the requirements around a storage node when it’s just there for Client Direct/file-path access coordination are extremely modest and could readily be met with the spare resources you see in the average VMware (or Hyper-V) environment.