Introduction
When you’re writing backups to tape, capacity reclamation is pretty straight forward (unless you’re using an archive product that pretends to be a backup product, of course). Tape based space reclamation comes down to a simple decision scenario: is everything on the tape outside its retention period? If you’re using a true enterprise backup product that has the decency to track backup dependencies, the question is supplemented of course with “…and there are backups in their retention period that rely on any backups on the tape”. If everything on the tape is safely deletable, you can overwrite the tape and get the ‘space’ backup.
When you’re working disk storage, dependency tracking really kicks in. You don’t want to wait for everything on a disk backup device to become recyclable (or safely outside their retention period) before you overwrite the disk storage system, so you’ll have a process where expired backups can be purged.
In that sense, it’ll apply to whether you’re doing backup to conventional disk storage (e.g., a NAS or SAN LUN), or whether you’re backing up to a deduplication appliance, it’ll be the the same sort of process. (If your disk is impersonating tape, see above.)
But, with deduplicating storage, as I’ve mentioned before, there’s not a 1:1 relationship between you deleting a file and the space coming back.
So, how does the space reclamation process work with deduplication? In this, I’m going to talk about deduplication as a generic process rather than any individual deduplication platform.
First, how is data written?
To understand the space reclamation process, we have to think back to how deduplication works. When a deduplication system is sent data (let’s think of it as a single file, that file may be a consolidation of a data stream comprising of many files), that data gets deduplicated and we write chunks of unique data. Different deduplication platforms work differently of course – those chunks might be singular, or they might be consolidated into more manageable segments of data. Of course, with source based deduplication systems, the data that’s sent across will already be deduplicated and ready for storage, whereas for a target based system, the deduplication appliance itself will be doing the heavy lifting.
But the deduplication system has to keep track of the data that’s been written. So whatever gets written to a deduplication system is not really stored as it was sent. The data structure itself will depend on the appliance and the algorithms used, but in one way or another, it’s going to be a series of pointers.
Conceptually, that’s something like this:
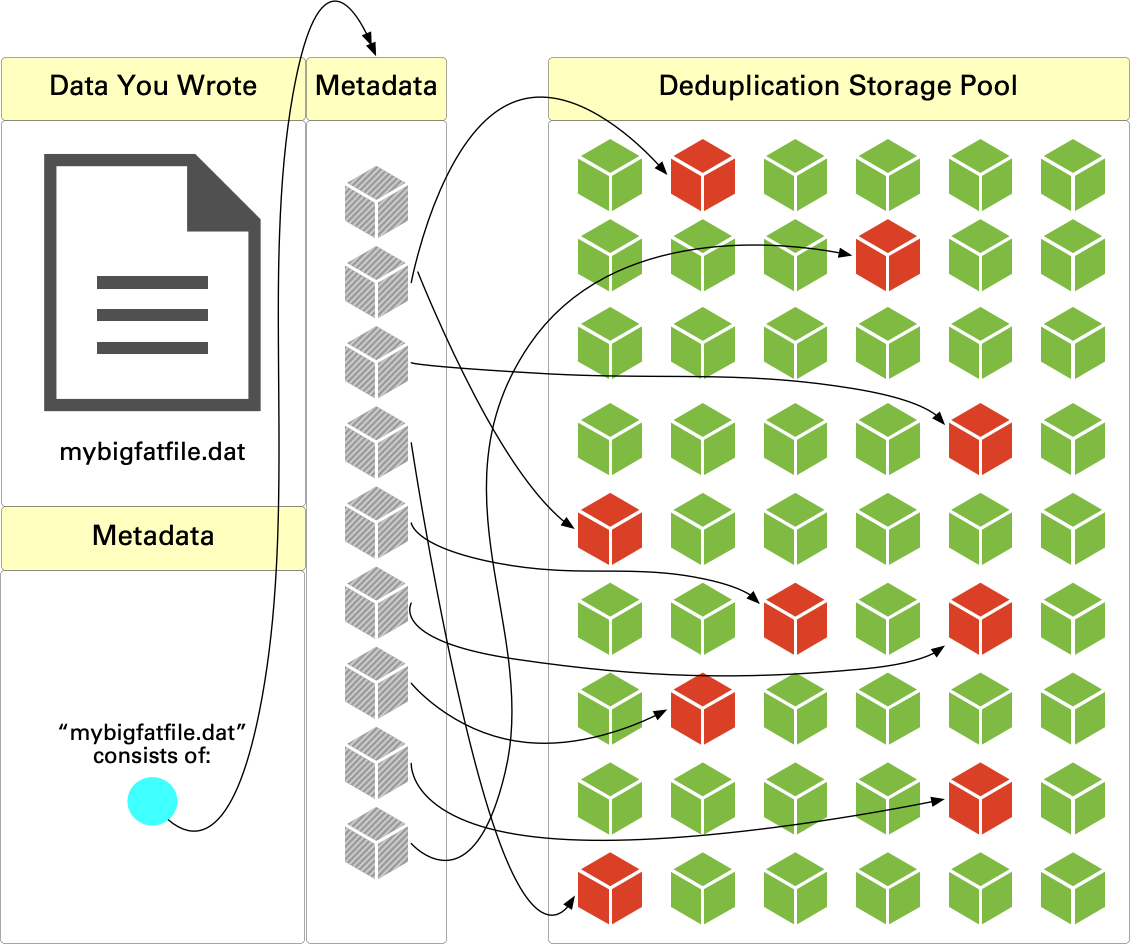
I’m not suggesting the data structure is a simple linked list, but it gets the idea across. In the above diagram, red blocks are deduplicated segments unique to the file that was written, and green blocks are deduplicated segments owned by other content.
So, when the backup software deletes the data, what really happens? Well, to explain that in a bit more detail, I need to achieve some deduplication in my diagram.
The above diagram only shows us a single file, but in a deduplication system, you’re going to get a myriad of links. Let’s say there’s another file that’s been written to our deduplication storage:
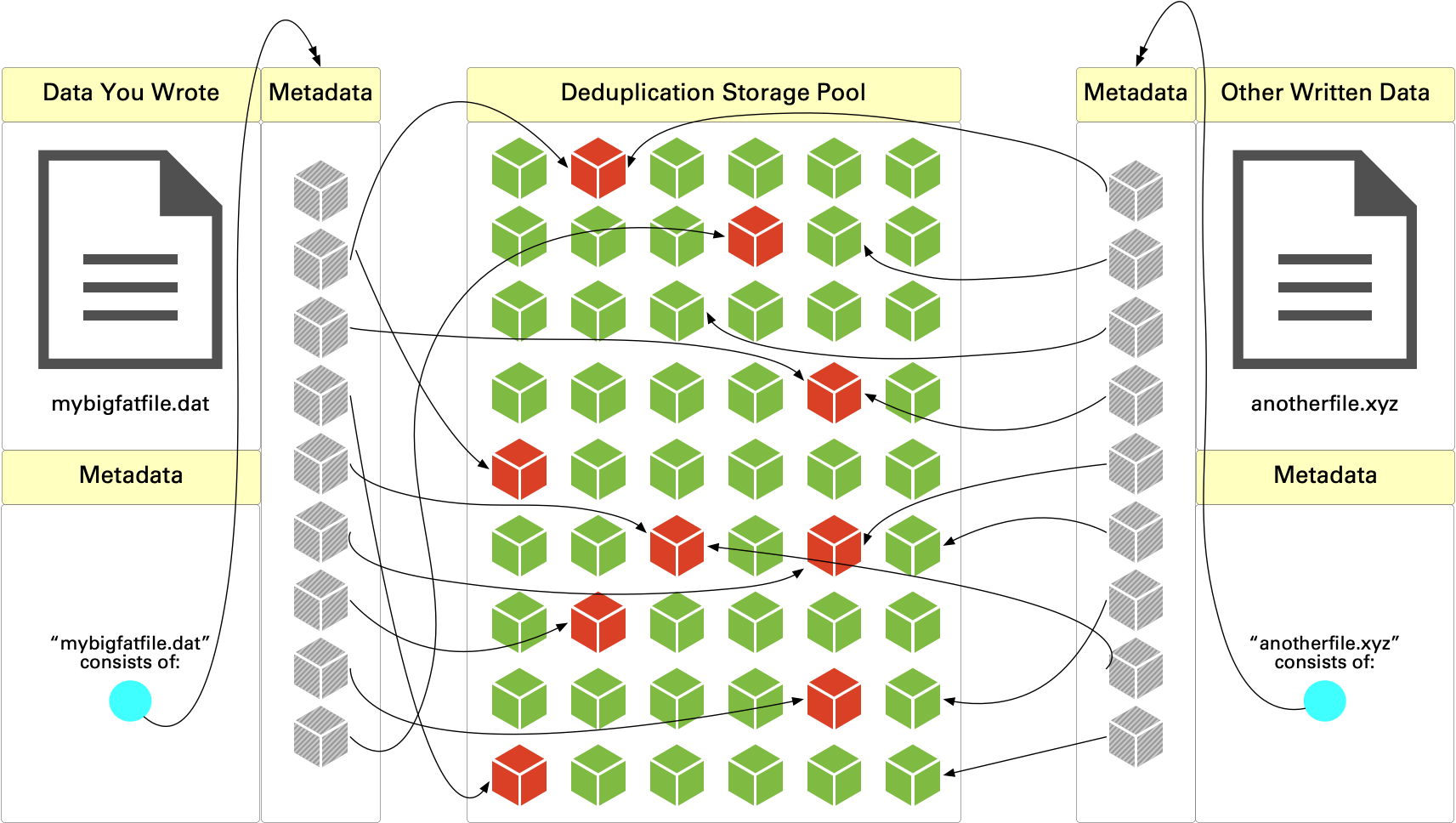
In this case, we’ve got two files that have been written, and some of the content of “anotherfile.xyz” references content that was written for the previously ‘unique’ data in ‘mybigfatfile.dat’. So what happens when we delete content? In this case, what happens when we delete ‘mybigfatfile.dat’ from the system?
Handling Deletes
As we know, deletion isn’t a singular activity with deduplication storage, since deletion doesn’t reclaim space immediately. So, what happens? Let’s say in our example above we delete “mybigfatfile.dat” from our deduplication storage. That leaves us with the following:
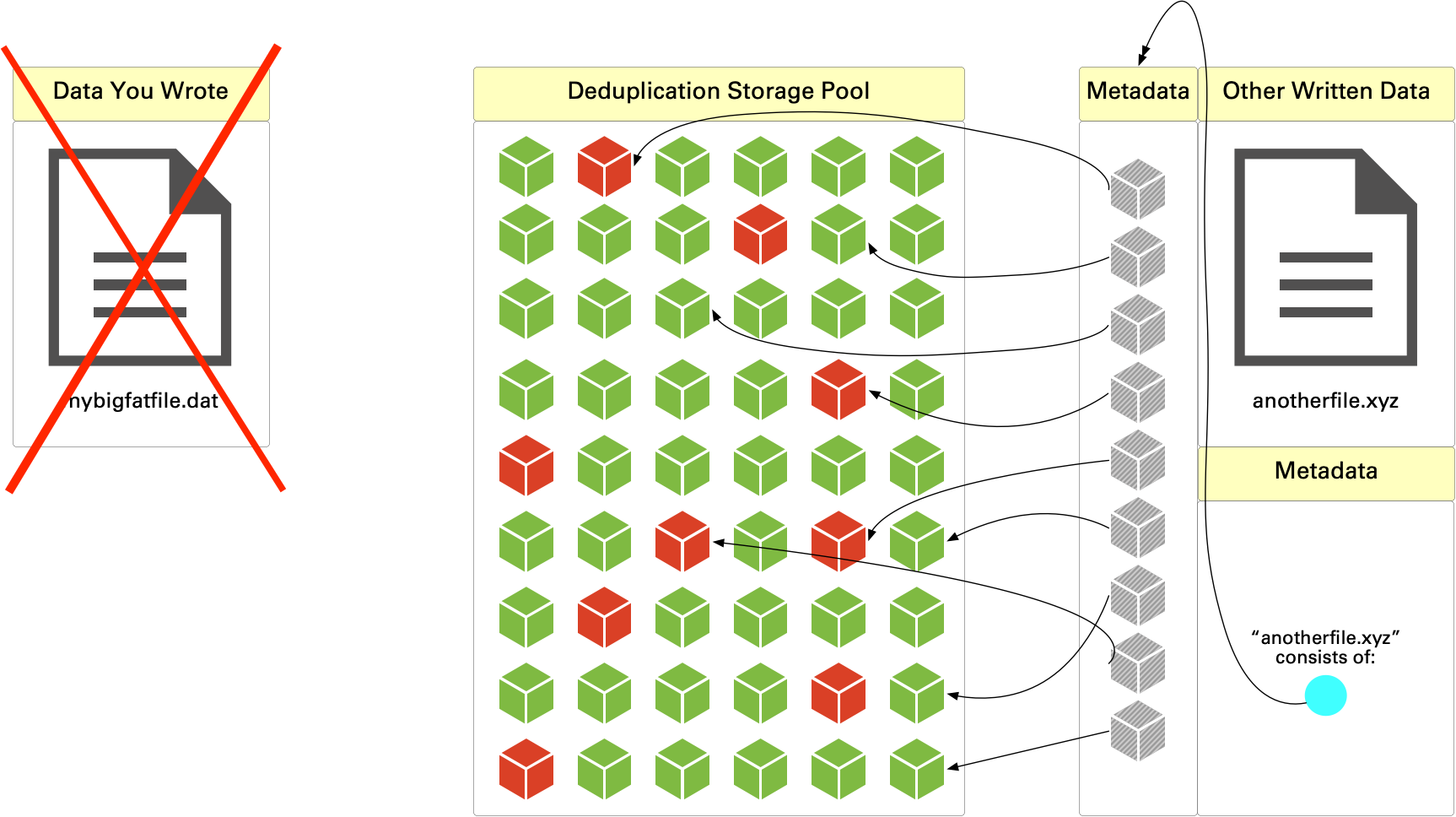
When you delete, the reference to the file gets removed, but within deduplication storage, the data doesn’t get removed from the storage pool. There’s a simple reason: efficiency – to be able to reclaim space, you need to basically scan the stored data on the system and see whether any blocks, segments (however you want to think of it) have nothing pointing to them. Now again, in the example above, all the green segments still have other content pointing to them, but we’ve got a few red deduplicated segments which have nothing pointing to them.
The system doesn’t know that yet – it works that during space reclamation, garbage collection, or filesystem cleaning, whatever the system refers to it as.
So, when that space reclamation process is run, the content on the system and the various segments of metadata will get analysed, and orphaned segments of data will eventually get removed:
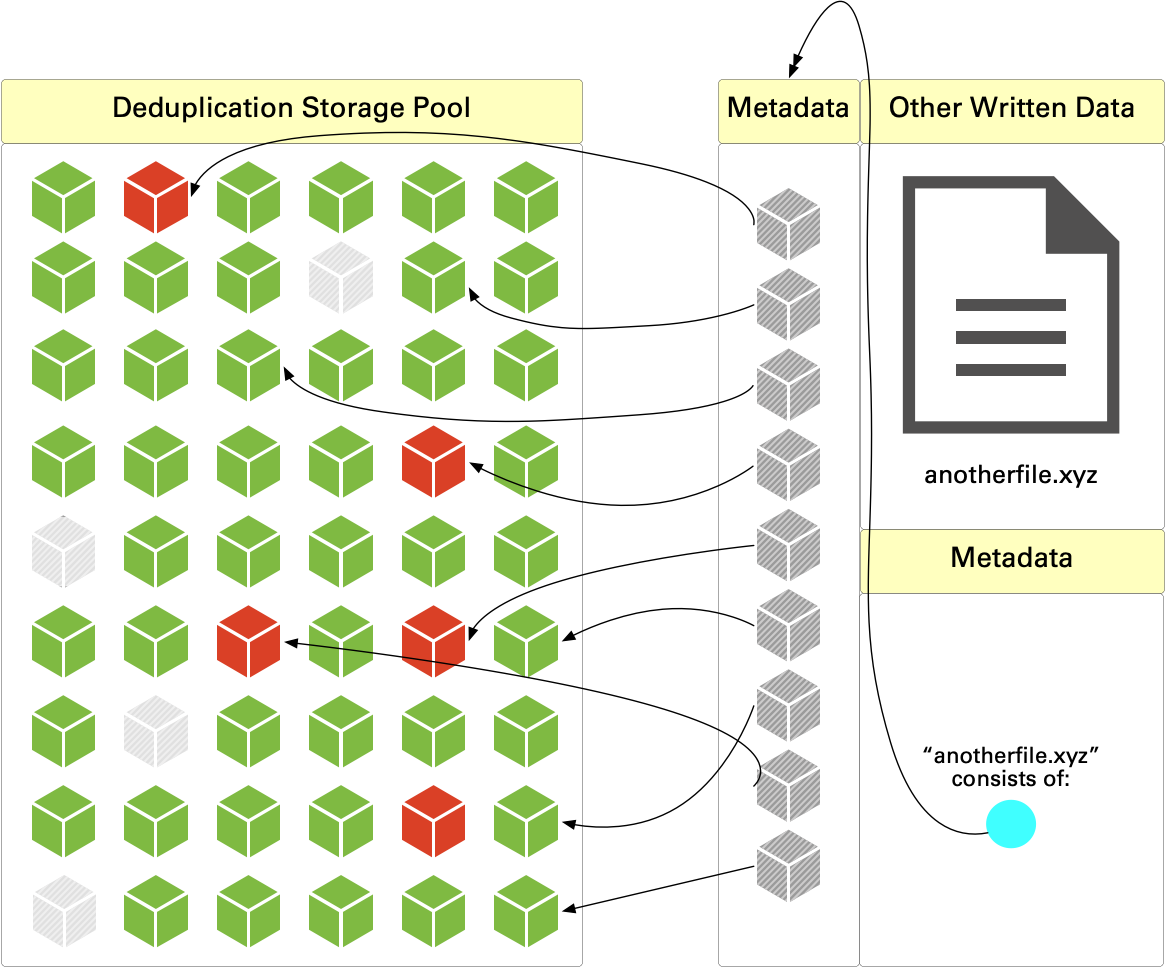
So after storage reclamation, those orphaned chunks of data are removed (shown by being greyed out above), and you’ve got your space back.
Summarising
I’ve presented a simplified view above – it’s not necessarily quite so straightforward. In lots of situations you’ll find deduplicated data written to containers, at which point we almost go back to our dependency issue: are all the segments in a container eligible for erasure? How containers are handled is outside of the scope of what I’ve covered above, but hopefully what I have covered above explains the space reclamation process.
There’s a simplicity to reclaiming space on non-deduplicating storage, but that simplicity comes at a cost of a 1:1 mapping between your FETB backup requirements, granularity of backup and retention times. That’s a pretty expensive bargain. So when you move into deduplication, the gap between when you delete and when you get the space back is a pretty small bargain compared to the sheer storage space savings you make. 20:1, 30:1, 40:1, 50:1 deduplication or more is worth having a little delay between when you delete, and when you see the space come back.