When Data Domain OS 6.2 was released, one of the new features enabled for virtual edition (DDVE) was support for the Google Compute Platform (GCP) aka Google Cloud. That support for GCP has been extended now to offer the same capacity as Azure and AWS – 96TB usable, via object storage. To wit:
It’s the object storage that’s the secret sauce for DDVE in public cloud. If you had to provision 96TB of block storage in public cloud, even though you’re going to get the best possible deduplication against it, your bills are going to be higher than you might otherwise like. However, DDVE in public cloud isn’t just some sort of “lift and shift” recompile of an on-premises DDVE; instead, it’s been architected from the ground up to operate efficiently and at minimised cost in the public cloud – hence, it actually looks like the following:
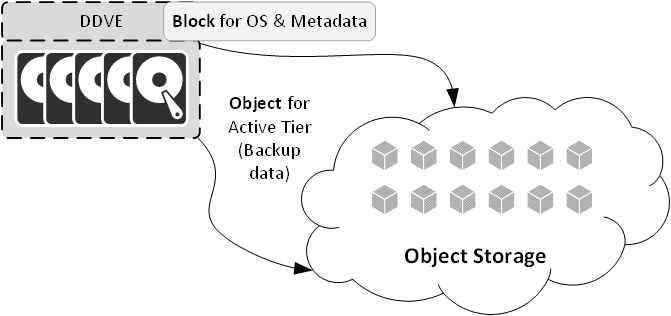
It’s a simple yet important pivot for DDVE in public cloud. The active tier becomes an S3 bucket (or whatever the local nomenclature is, since DDVE supports many clouds), and the metadata associated with deduplicated data resides on block. The metadata allows for high performance use of the object storage by letting DDVE work out exactly what it needs to read and pump out those read requests at high speed, and parallelised as much as possible (you might say it’s a similar approach to how using SSD in a physical Data Domain on-premises speeds up access to conventional drive storage, allowing up to 40,000 IOPS on systems such as the Data Domain 9800).
DDVE in public cloud then gives you an efficient storage mechanism: not just for conventional backups – e.g., via an Avamar or NetWorker server, or even loosely decoupled architecture backups, such as Boost for Databases (e.g., Oracle/SQL/SAP HANA), but also for next generation workloads – such as databases so new even the developers haven’t come up with a formal backup API, and so you have to protect those via dumping – so you want to use BoostFS to dump them to deduplicated storage.
But it’s not just in the cloud of origin that DDVE shows its efficiency – it’s the further enablement it gives you in a multi-cloud strategy as well that’s important here. In the simplest form, you might simply be thinking multi-region within the same cloud provider, giving you the option to readily failover workloads from Melbourne to Singapore, but it could also be true multi-cloud as well: providing you a complete off-platform copy of data from AWS into GCP, or helping you migrate a workload from one public cloud provider to the next. The help, of course, is data efficiency: since DDVE does deduplicated replication just like physical Data Domain systems do, you get to copy data from one location to the other as efficiently as possible. Your workload might be 50TB, but at 10:1 deduplication that’s come down to 5TB, or 20:1 deduplication it’s come down to 2.5TB – and when you have to pay for data egress costs as you copy data from one region or cloud to another, it’s worth making sure that you can copy the least possible data. So DDVE isn’t just the right fit for a backup solution in public cloud, it’s the right fit for giving you an extra tool for data and workload portability, something that’s an essential aspect of next generation cloud adoption:
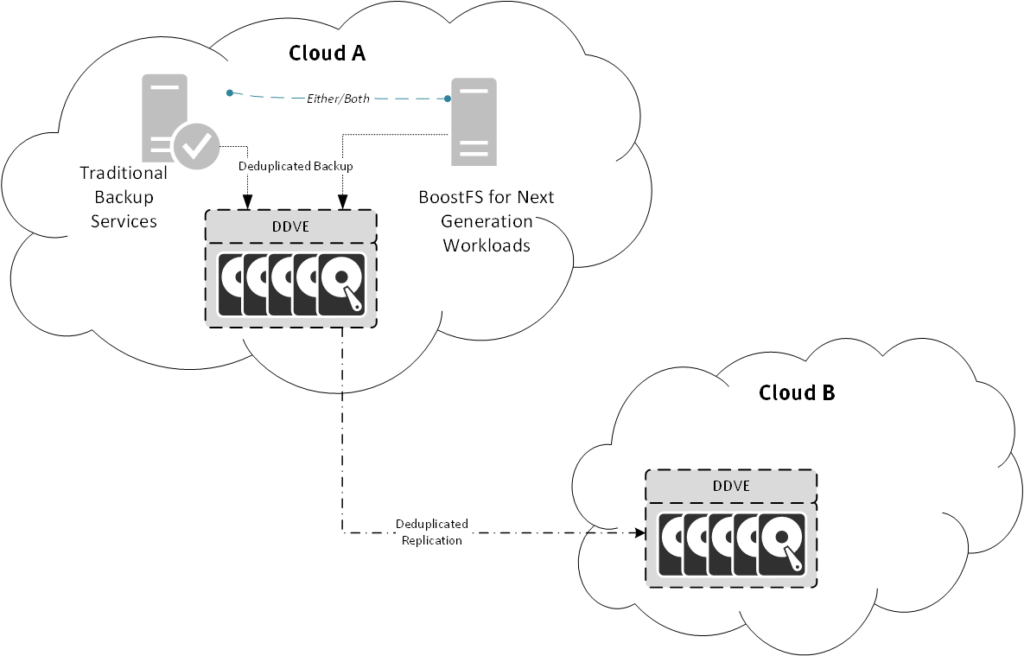
Leveraging DDVE for workload portability has been there for you right since DDVE first made its way into the cloud: first, as block based DDVE (limited to 16TB), then as object based DDVE but focused on AWS and Azure. Now though, with object based DDVE covering AWS, Azure and GCP, DDVE has really stepped it up to the next level, just in time for the next architectural conversation shift: away from “cloud first”, or “cloud fit”, to “multi cloud”.
1 thought on “Data Domain Virtual Edition Extends Multi-Cloud Support”