Introduction
There’s always been a few different methods for database backups. Adding to the mix of course, businesses can have different levels of maturity when it comes to database backups, and this can even extend down to individual teams of database administrators establishing their own requirements on how their backup takes place, In the end, it’s all about getting recoverable copies of the database. It’s how we do it that can make a difference.
It’s no wonder then that there’s no agreed standard (much as I might wish otherwise), so in this post I want to run through 4 key approaches. If you have databases in your backup environment, there’s a good chance you’ll recognise one or more of the models I’ll be outlining below. This isn’t to say these are the only database backup types (you’ll note for instance that I ignore cold database backups – as most people do).
To help explain these different models, I’m going to frame them in terms of travel in addition to outlining how they work.
Dump and Sweep
Dump and sweep is one of the oldest backup models you’ll see still in use today. Despite protestations to the contrary by some, dump and sweep is costly, both in time to execute the backup, and in use of primary storage systems.
The ‘dump and sweep’ description reflects the two distinct and separated tasks involved in this form of database protection. Database administrators will trigger (either manually, or through their own automation tools), a database dump to local storage. This generates a copy of the database, usually as a single large flat file (though it may vary) in a way that a DBA can execute a recovery against at a later point in time.
At some point in time, a standard file-based backup agent installed on the same host will ‘sweep’ through the filesystem and write the database dump to the backup server’s protection storage, regardless of whether that’s tape, conventional disk storage, VTL, deduplication storage, or anything else.
In terms of transport, dump and sweep is like sending a package daily via a courier.

There’s a good reason why you’d compare dump and sweep to using a courier service: the backup is split into two distinct processes: the dump is packaging up something to be sent, and the sweep is waiting for the courier to arrive to pickup the package and take it to where it needs to go.
Ironically, the same challenges can happen with dump and sweep as can happen with courier pickups:
- You might not have got everything packaged up by the time the courier arrives, in which case he or she leaves without taking the package:
- In dump and sweep arrangements, a common problem is the dump side of the backup not being completed at the time the filesystem backup sweeps through the filesystem. The dump file might be skipped entirely because it’s still open/being written to, or a partial file might be backed up, which is entirely useless for recovery purposes.
- The courier might arrive many hours after the package is prepared, increasing the risk of something unexpected happening:
- The database dump starts at 6pm and finishes at 7pm. The sweep operation doesn’t start until 11pm, or 1am. This can leave a long window where the most recent database copy is residing on the same system as the database – if something happens to that system, both the original and the backup may be compromised.
- The courier service might let reception know whether or not the package was delivered, but you could be left in the dark.
- A very common problem in dump and sweep scenarios is a lack of visibility all around. Since the dump, and the sweep, are two entirely disparate processes managed by different teams, those teams have to come up with their own way of making sure each is aware of whether the other’s activity completed successfully.
The other challenge as I mentioned before with dump and sweep is the consumption of primary storage. In all of the other techniques I’m going to explain, our backup lands on the protection storage platform used within the environment: tape, conventional disk backup, VTL, deduplicated storage, etc. One of the most common observations I’ve made about dump and sweep over 20+ years of working in backup is that it’s never just one database copy in the dump area on the database server. Usually, in fact, it’s a minimum of 3, and often up to 7. The rationale is faster recovery: DBAs don’t need to raise a ticket against the backup team to get a copy of the database from 1, 2 or x days ago, they can just source directly from the local storage. However, since writing the dump compressed would be an onerous imposition on the database server’s CPU cycles, that dump will be full size: 1TB database = 1TB dump. 5 days of dumps means 6TB (including the original database) consumed. If that’s tier 1 or tier 0 primary storage, that gets costly: very costly.
The solution of course is enabling the database backup process to integrate into the database native tools, in order to allow DBAs to do a self-service recovery!
Traditional Agent Backup
By “traditional agent backup”, I’m referring to the situation where there’s an enterprise backup system within the environment, and the database server(s) have the registered plugin for that backup system installed. In this method, I’m going to work on the basis of the backup system executing the backup for the database at the appropriate scheduled time. (The alternate scenario, where the DBAs still schedule backups of the database themselves, will be covered in the next section.)
This is a more reliable approach than dump and sweep, and features key advantages:
- Achieving backup consistency is an automatic part of backup and recovery (this usually introduces the concept of restore and recover: restore from backup media, recover by applying consistency – e.g., redo logs).
- The schedule is much more guaranteed: if the configuration is set to start the backup up 9pm, usually that means the backup will get started at 9pm (i.e., excluding resource issues) and that backup will start as an off-platform backup, rather than the split approach.
- It’s usually easier to provide insight to the database administrators that they have a recoverable, off-platform copy of their database.
- It’s usually easier for backup administrators to know that the database backup has integrity.
What’s this model look like from a transport point of view?

That’s right, the traditional agent based approach to database backups is like a coach trip. Everyone gets on at the same time, everyone goes in the same direction, and everyone gets off at the same time. There may not be a lot of flexibility, but there’s usually a fairly rigorous timetable, and someone has oversight and visibility in terms of whether the trip is on-time, and all the passengers are accounted for.
A great additional benefit of this of course is that we’re not consuming expensive primary storage for that initial backup into a ‘dump’ region on the database server. Instant cost saving.
As backup techniques go, you could do worse. (I’m looking at you, dump and sweep.)
Database Direct Backup
I’m a big fan of database direct backups. This is the start of modern, modular architectural approaches to database backups. In this model, there’s still some form of database agent, but the database administrators retain control over the scheduling of the backup. That agent might be a traditional enterprise backup agent (e.g., NetWorker), or it might be a fully decoupled agent, such as Boost for Microsoft/Boost for Databases – no centralised backup server.
This gives the core functionality of the previous approach: making sure the database backup is a one-step process, and getting the protection copy off-platform as quickly as possible, but it also leaves the DBAs in control of the process. That’s critical for two reasons:
- When they don’t like to give up control: OK, some database teams don’t like giving up control over the backup process. This is a discussion I’ve been having for the past two decades. But, guess what? I’ve stopped having the discussion because I believe they’re right.
- When realistically we accept as the experts they should be in control: The database administrators are closer to the purpose of the data (i.e., the workload) than the backup administrators. So, in reality, we want the people who are experts in the workload and understand the purpose of the workload to the business to be in control of the process. However, that control can be accompanied with governance and control: i.e., reporting, monitoring and capacity analysis.
Continuing our transport theme, database direct backup is more like:

When we go for a database direct backup method, it really is like catching a taxi. Unlike the coach approach for traditional agent based configurations, this is about providing greater control over the direction and start time of the journey. Database administrators could in theory schedule every database individually, or they could car-pool, so to speak, and execute the backup for all databases on a single server at the same time, for when fine scheduling granularity isn’t required.
This method gives you your off-platform protection quickly while leaving the database administrators in control of scheduling. It’s one of those ‘best of both worlds’ situations.
Storage Integrated Data Protection
Storage Integrated Data Protection (SIDP) is like database direct, on steroids. It’s not necessarily something you’ll use for every database in your environment, but it is something you can keep in mind for those outlier cases: a 100TB database that you’ve got to backup every day, for instance. Something where it’s just so genuinely big and SLA-tight that a conventional read-the-database-up-through-a-plugin-and-transmit approach simply won’t achieve what you want. That’s not even necessarily saying the protection storage isn’t fast enough: it’s the protection transport process that needs to be improved.
And as transport processes go, that looks like this:

SIDP (e.g., Dell EMC ProtectPoint) is like something out of Star Trek or Stargate – it’s about teleporting your data.
In this approach, you’ve got a more tightly coupled primary/backup storage architecture, but that’s to ensure you can get those huge, mission critical databases backed up as quickly as possible. Using a VMAX3/PowerMax with Oracle example, the process here works as follows:
- The database administrators run an RMAN script for a database backup
- At the storage back-end, the LUN(s) hosting the database are snapshot while the database backup is considered active
- The database exits backup mode – the backup is done, from the perspective of Oracle
- At the back-end, the storage array, with Data Domain Boost integrated, ships off the blocks that have changed since the last backup (i.e., the incremental changes). (Well, those blocks that need to be sent across, since we’re deduplicating as well.)
- On the protection storage side, Data Domain uses the awesome power of virtual synthetic fulls to construct a new full backup, stored as a vDisk, of each LUN that has been snapshot.
[Edit: Correction, I’d used ‘hot backup mode’ without reflecting on how RMAN handles backups. Thanks Porus for pointing out my error.]
You’ll note that unlike other database backup methods, the database server is not in the data path.
SIDP isn’t about for when your backup absolutely positively has to be there overnight, it’s for when your backup has to be there now, or as close to now as possible. Which is why SIDP really is like beam me up, Scotty.
Dump and Sweep, Redux
Huh!? What’s this? Dump and sweep gets mentioned twice? Well, there’s a reason I’m looping back to this. While dump and sweep is a bad approach for any database we have the ability to interact with more intelligently, we don’t always have that luxury.
There’s more databases out there than you can poke a stick at (to use the Australian vernacular). What’s more, some of those databases have a somewhat laissez-faire approach to backups. One might even suggest at times, apathetic. Maybe even: pathetic. If you think I’m being mean spirited here, let me present to you the Apache Cassandra FAQ entry (here) for backups, as of 4 March 2019:
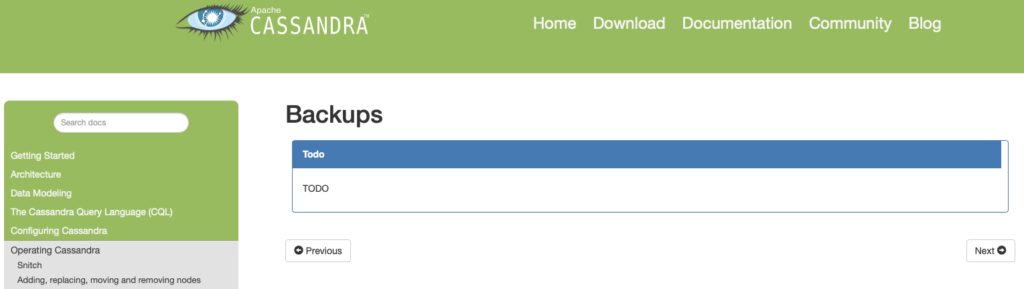
Apache Cassandra, we are told by Wikipedia, was initially released in July 2008. (That is, one might note, a rather long time for a database to exist where the developers haven’t been bothered to write anything up about how to perform backups of it. At least, in the official FAQs)
So that’s where we revisit dump and sweep. Sometimes, that’s the way you have to go because there just isn’t a better option. In that case, you make it a better process – such as using BoostFS to at least ensure you (a) get your dump off-platform and (b) transfer it efficiently.
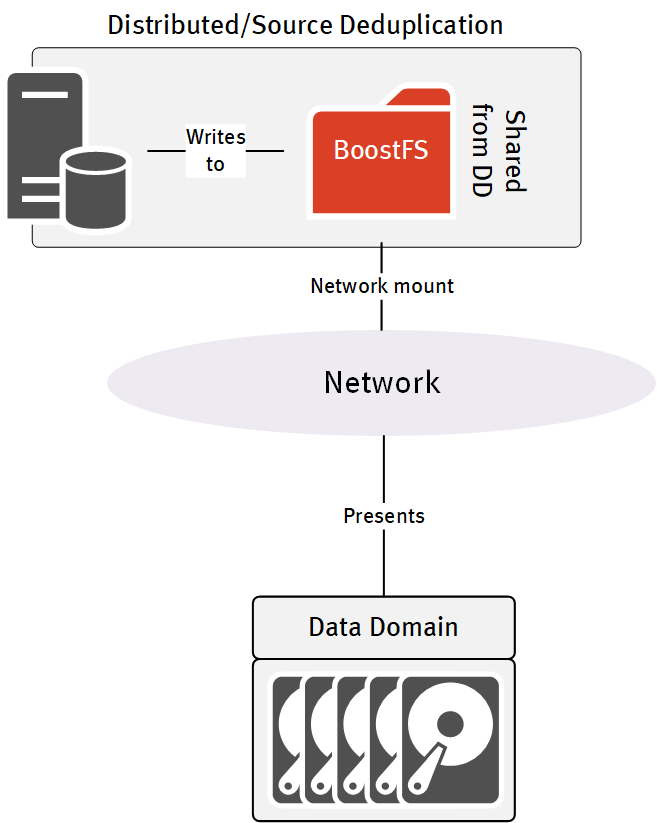
(In short: if you’re going to do dump and sweep, do it well, and for a good reason.)
In Summary
So that’s the quick overview of the various modes of database backup you can do within an environment. I’d be very surprised if your organisation doesn’t do at least one of the above, and I hope if you’re still doing dump and sweep, that you might have seen there are, at least for traditional databases, usually much better ways at getting an off-platform copy.
If you found this interesting, check out Data Protection: Ensuring Data Availability.
Preston, in “Storage Integrated Data Protection (SIDP)” you mentioned hot backup mode. Why do you need hot backup mode when using RMAN? Orace DBAs have moved away from hot backup mode when backing up with RMAN, it is not required. It used to be used in the old days when RMAN was not available. Hot backup mode does place some overhead on the database.
Oops, thanks for that! I’d forgotten that detail of RMAN, and had used ‘hot backup mode’ erroneously. I’ve corrected the article.
No worries Preston.
Remove “The database exits backup mode” as well.