At Dell Technologies world, PowerProtect was announced. This is next generation data protection software and appliances; these aren’t just an incremental update, but a pivot to a new approach to data protection.

I’ve been working in the data protection industry for a long time. I jokingly tell people I’m one of those rare geeks who likes backup and recovery and all other things data protection. The truth is of course, when you work for the data protection division of Dell EMC, you know that you’re surrounded by other people who are equally as passionate about data protection as you are.
And when you’re passionate about data protection, you’re not just thinking of how you solve today’s problems, but tomorrow’s, too.
Data protection has gone through several architectural changes over the decades. When I first started working as a system administrator, it was pretty common to see something like the following:
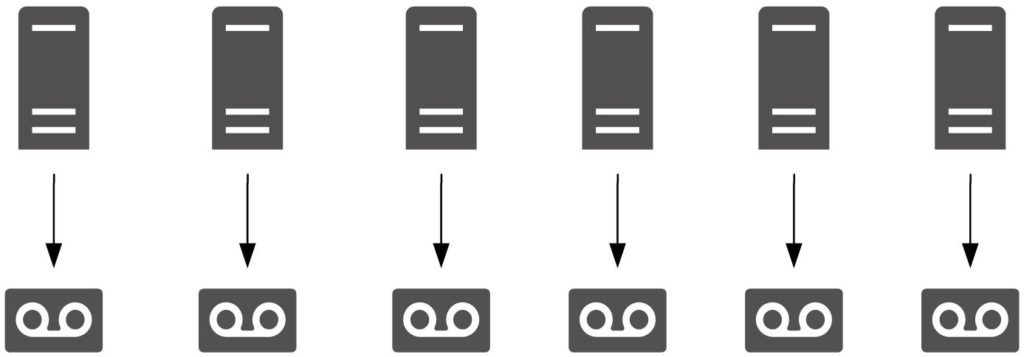
The earliest backup architecture really was “every server for itself”; you’d see a myriad of tape drives (more often than not things like QIC and DAT drives) in the average server room, one per server. Big servers might even have two tape drives. Then every morning, the protein based autoloaders (i.e., operators) would take a turn about the server-room, pulling out last night’s backup tapes, and putting new ones in.
Eventually that just didn’t scale any more, and so we ended up with the concept of a backup server.
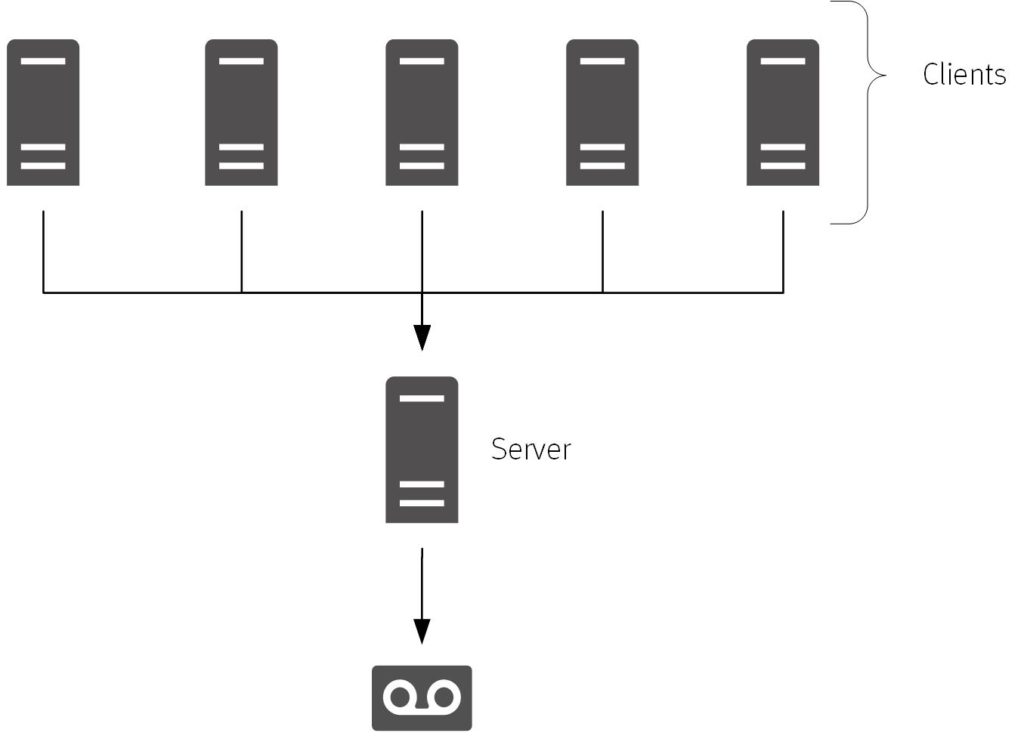
The backup server was a great architectural step at the time – instead of having to maintain backup configuration and monitoring on a plethora of hosts in the datacenter, you could just maintain it all from a single server. Of course, eventually you had to start stacking on tape drives, and then also tape libraries, in order to scale, but we hit a point when the backup server by itself couldn’t scale, and thus was born the storage node/media server – and the three-tier backup architecture.
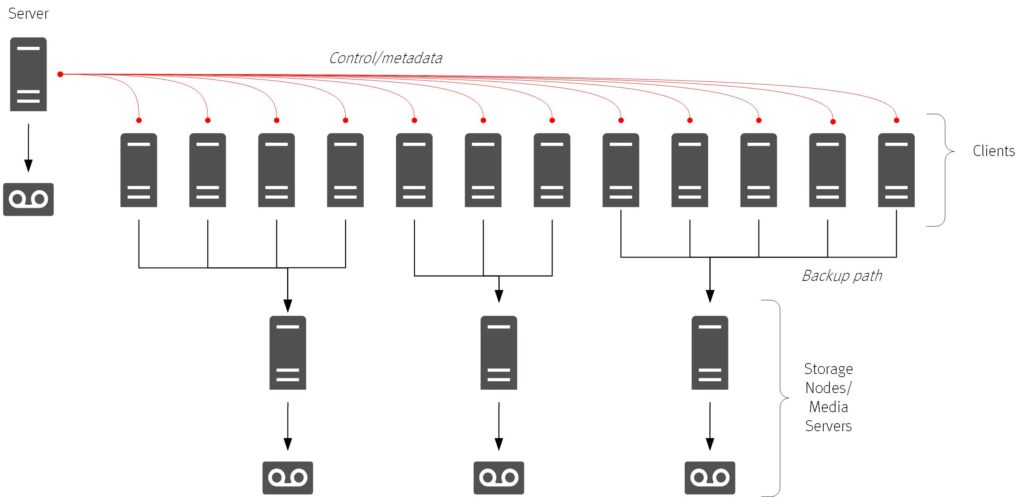
That three-tier architecture ran for quite a long time, being extended and supplemented with tape library sharing, disk backup, and so on. Eventually though, we hit the same bottlenecks: network transfers during backup (particularly full backups) drove more of the intermediary servers being required, driving up costs and management complexity.
It was deduplication that allowed for a simplified, flattened architecture – and particularly, source based deduplication.
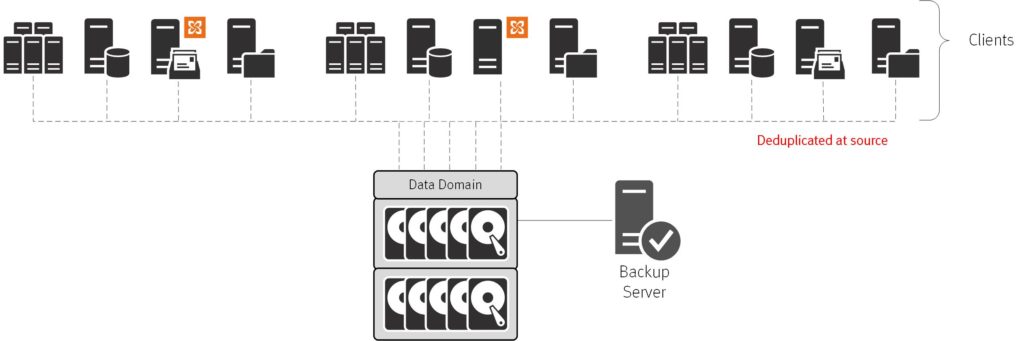
By getting rid of most of the data before it has to be transmitted, we didn’t just get a faster, more efficient backup, we also got a backup requiring less architecture. Those middle-tier servers were all point-B components existing to funnel data from point A to point C; by reducing to an absolute minimum the amount of data that needs to be transmitted in the first place, we get rid of point-B (or reduce it to traffic cop duties, such as in NetWorker).
That’s been the classic mainline architectural changes over the years: two-tier, three-tier, flattened.
But we can do better – we have to do better, because the volume of data of the future is more than a little bit scary.
I’d argue that Dell EMC has been leading the way on that for a while. The Boost plugins for Data Domain, for instance, were the first steps: providing a mechanism to have centralised data protection storage with decentralised operations. But we need more. That’s where PowerProtect comes in.
What PowerProtect is about is having a new data protection architecture. A modular, decoupled subscription architecture is the next generation approach to data protection.
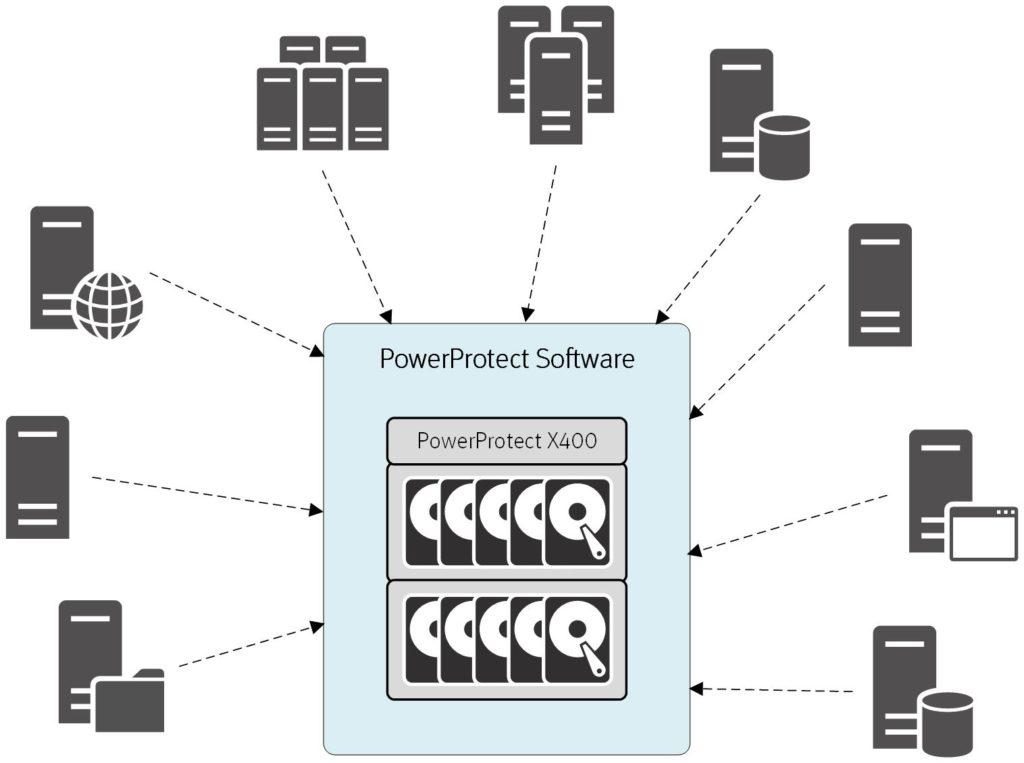
PowerProtect is about having a modular, subscription based data protection architecture. Your data protection teams provide a service to the rest of the environment to subscribe to. The service provides data protection policies regarding retention, number of copies, and so on, then the teams with the content needing protection can join the service and get their content protected following the ‘guard-rails’ that have been established.
This modular approach is more than just “hey you can join another client”, it’s modular from the ground up. We used to talk about whether your backup product was “monolithic” or “framework”. A monolithic backup product tries to do everything so you never need to customise it. That fails because there’s always limits on what can be supported, and it inevitably falls into the “jack of all trades, master of none” problem. I’ve been championing framework based products for close to two decades: they’re about accepting the product can’t do everything, and making it possible for people to extend it. Pre- and post-scripting, extensive CLIs, REST APIs, etc., allow us to adapt framework based data protection systems to do what we need to – within reason. But, the allusion in the introduction graphic was quite deliberate: monolithic architectures don’t cut it, and framework based architectures, like Moore’s law, eventually run up against a wall. The next architecture is a modular one. It allows all the extensions of a framework based architecture, but it also allows for new components to be slotted in quickly and efficiently, too.
There’s more to it than that, of course: I’m really only just scratching the surface here, but I wanted to start with the fundamentals, because to understand PowerProtect, you need to understand that data protection architecture is going to shift.
There’s some really good details about PowerProtect from the official channels – I definitely recommend checking out each of the following:
I’ll be talking more about PowerProtect over the coming weeks and months. It’s going to be a great journey.
After reading the complete document. I was expecting may be at end you would show up some snippets from your lab implementating the same..
It’s still not GA, Will share the snippets from LAB after it is GA