Ideally, our backups work all the time without an issue. That’s an ideal situation. Then again, in an ideal situation, we don’t need to recover — or at least, don’t need to recover due to data loss situations.

There’s three fundamental approaches you can take to a failed backup. These are:
- Ignore
- Restart
- Investigate
Ignore
The ignore approach is (at times) surprisingly popular. Sometimes you can make a deliberate choice to not deal with a backup job that’s failed. It could be that you’re well aware the client was going to be taken offline, there was a general systems fault, or the backup job is a lower priority one (e.g., a development or test one) and the SLA allows for a backup failure.
That’s not always the case though. It could be that backup jobs aren’t always checked daily: you might not have dedicated backup administrators and it’s a shared responsibility. Perhaps your team is too busy to check the backup job emails, or perhaps it’s Joe’s turn to check backup jobs but Joe’s away today and it’s probably all OK. So by ‘ignore’ here, it’s sort of more like: I didn’t get around to it.
One thing I’ll note about backup environments these days: gone are the days when a backup administrator could spend the first half hour or hour of the day reading through the emailed status report of every single backup job that completed. So I can understand (seriously, I can), that it’s easy enough to not check the overnight backup jobs.
But, I can also understand how easy it is these days to check the overnight backup jobs, thanks to Data Protection Central:
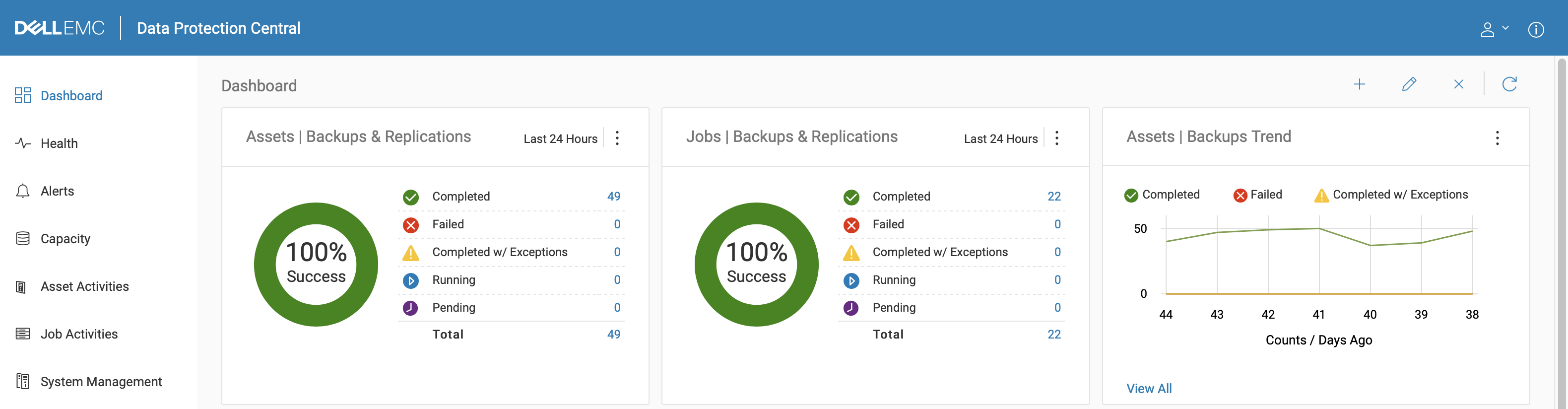
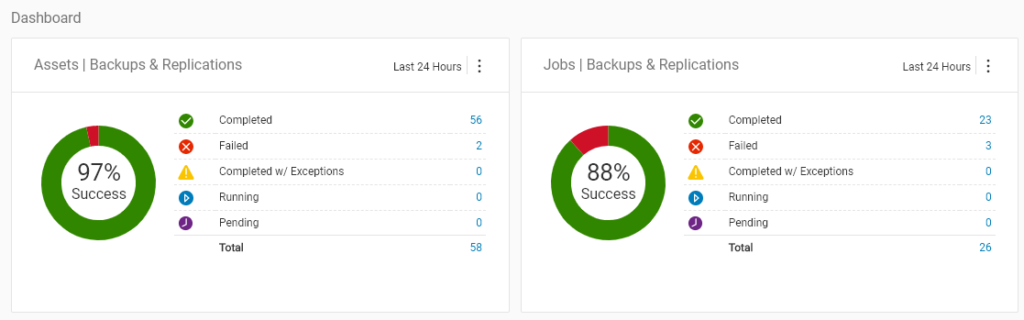
Data Protection Central is free if you’re using NetWorker and/or Avamar — it’s just a simple OVA that you download and deploy, and it can give you immediate dashboard visibility over multiple NetWorker and Avamar installs, multiple Data Domains, etc. While it’s got a lot more function than this, the way I describe it to my customers is: it gives you your mornings back. If you’ve got 50 or 100 email notifications to check from overnight backups, that’s potentially a lot of work—logging onto a central console that shows you everything at a glance though? That solves the I didn’t get around to it problem straight out of the box. So it doesn’t matter if Joe’s away and it’s his turn to check the backup results, or if it’s a shared responsibility for a team, it becomes trivial to check for backup failures when all you have to do is look at a couple of donut graphs. If you’ve got failed jobs, the number of failed jobs becomes a clickable link so you can drill down:
Restart
The next approach is restart. You can assume the error was transient and just go and restart the backup job — with NetWorker for instance you can do a Restart on the policy’s workflow (or if you’re still for some reason on NetWorker 8 or below, the group). Shown below you’ll see the Restart option in NMC:
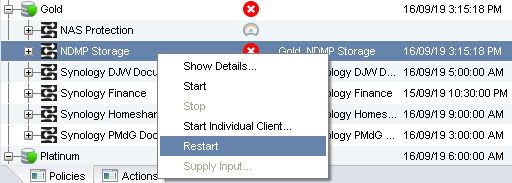
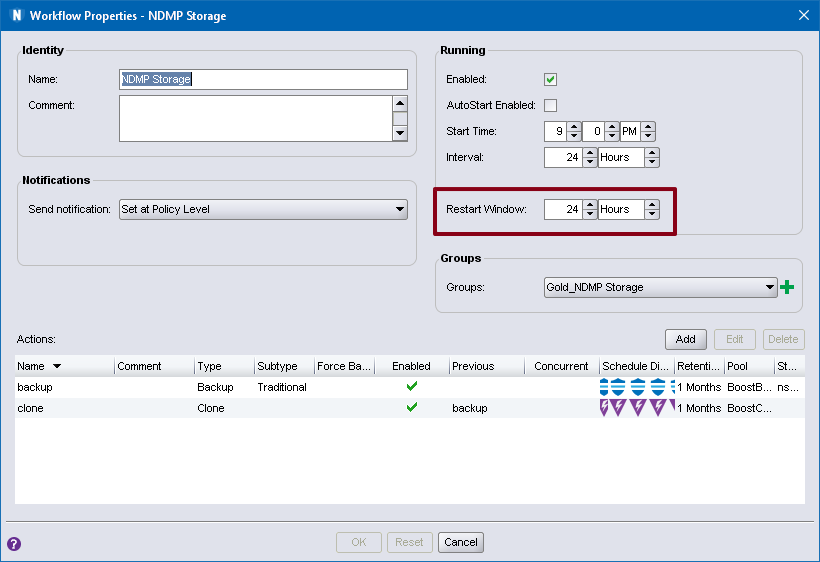
The option is greyed out if the group was successful. (If you want to re-run a particular client that had previously completed successfully, click the Start Individual Client option instead.) Under NetWorker 8 and below, it used to be that the default window for restart was 12 hours – i.e., you had 12 hours to restart a failed job or else NetWorker would simply just start all the savesets in the group again. Under more recent versions of NetWorker, the default restart window is 12 hours, but can be controlled by editing the workflow properties:
With Avamar, restarting is even easier if you’re using Data Protection Central – you don’t even have to go into the Avamar GUI if you’re logged into DPC. First, click on the hyperlink provided for the failed jobs. That’ll bring up a filtered version of the asset activities showing failed jobs:
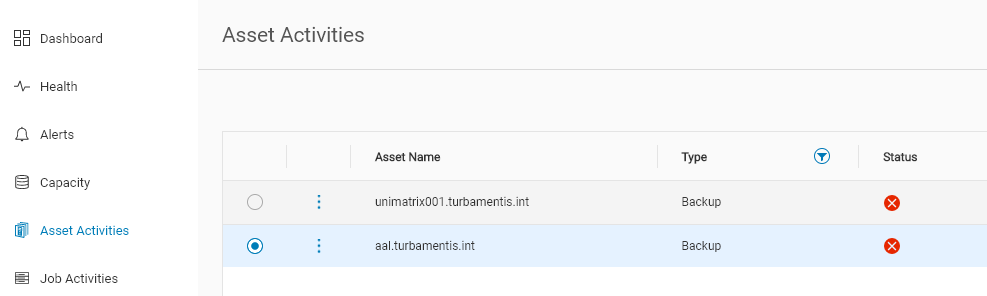
Then, for Avamar failed jobs, click the 3-circles menu next to the client name and click the “Rerun Asset Activity” option:
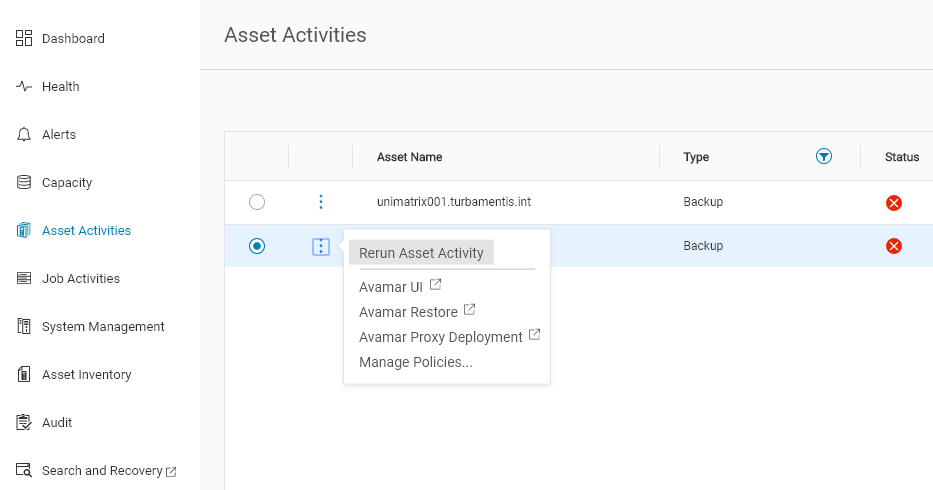
Sometimes just re-running the job works. Maybe the error was transient — maybe the client for instance was rebooted mid-way through the job. When I used to be a system administrator I’d sometime jokingly attribute random failures to solar flares, but as systems have become significantly more reliable over the past two decades, and particularly when you’ve got a well configured environment, random failures are far less likely.
What do I mean? If there’s a failure in a well-running environment, it’s probably more than just some weird quantum fluctuation. Simply re-running the job may not be sufficient.
Here’s a common question that comes up: Should I put failed clients into a separate policy in NetWorker to re-run them?
Answer: No. If you start the client out of another policy/workflow, that policy/workflow doesn’t have the history of what savesets were successful or not, so it’s going to have to start them all.
Investigate
So then there’s the third action you can take: investigate. Maybe the investigation will take less than 30 seconds — you’ll see that the client was rebooted, or the database restarted, during the backup. Maybe it’ll take longer, but investigations have a three-fold purpose: they don’t just help you resolve the problem, they also:
- Teach you more about the nitty-gritty of the product
- Help you isolate/see patterns in the environment
While it was not said in the same terms, the first job I had where I was a system/backup administrator effectively had a zero error policy. The stated policy was “the best system administrator is a lazy system administrator”, which had a correlation: “if you have to do something more than once, automate it”. At the start, that meant breaking up email notifications from backups depending on whether they were successful or failed, using email client rules. Eventually though there was more intelligence — actually parsing the notifications and pulling out additional information covering warnings, too. The net goal? Focus on project work and only intervene when there was a failure, or an unknown situation in the backups.
The consequence of that was learning to dig deeper and deeper into how products (in my case, NetWorker) behaved. There’s nothing wrong with logging a service request when there’s a failed backup job, but any time you can avoid that because you can already see what’s happened, you’ve probably saved yourself some time, regardless of how fast a customer service person gets back to you.
Beyond that deeper product expertise though, you also get to build up a more comprehensive view of the environment. Do certain backup jobs fail in clumps? Is the environment less reliable in the middle of the month? Does that one particular host tend to have slower and slower backups until it fails a couple of days in a row, gets rebooted and starts working again at full speed? Do weird problems happen every time there’s a full moon? (OK, the last is a bit of a stretch, but you get my drift.)
Developing that nitty-gritty knowledge and environment awareness can be a self-perpetuating cycle of speed as you build up your expertise, too: you know more, you’re able to diagnose issues faster and with less help, and the net result is that the environment continues to run better until you get it to the point that you’re managing by exception.
So you can deal with backup failures by ignoring them (risky), just restarting them (do you feel lucky, today?), or investigating them. There’s no prizes for working out which option I recommend as best practice.