
How often do you hear the term “stick to your knitting!” these days? It seems whenever a celebrity or sportsperson says something like “Maybe we should do something about climate change”, there’s a raft of conservatives ready to jump up and down shouting “Stick to your knitting!” I.e., focus on your job.
I want to turn that phrase around today and talk about why backup administrators should stick to their knitting.
Of course, I don’t mean literally. Much as the idea of knitting has always fascinated me, between typing muscle-memory, RSI and now the start of arthritis, I believe knitting is one of those things that will forever elude me.
But there’s one particular thing about knitting I want to talk about today: patterns.
Patterns are essential for knitting. If you don’t know how to knit a beanie, for instance, you could try to make it up as you go, or you could find a pattern and follow it.
Backup/recovery, and data protection more broadly, is all about patterns. You want consistent results, after all. Using NetWorker as an example, every backup and recovery action you take can be reduced to a pattern.
There are several advantages to making patterns for your data protection. These include:
- They can form a foundation layer to understanding the security and communication requirements of the data protection environment.
- Pre-deployment, they help document what you need to implement, and test.
- Post-deployment, they help document the intended function of the solution.
- They can help establish boundaries for the data protection solution. That doesn’t mean the solution shouldn’t adapt after the patterns have been developed (you should always be prepared to develop new patterns). Rather, it helps establish the view that if you’re going to do something new, you should work through a formal process for it!
- Patterns are the foundation for automation: for understanding what can be automated, and how that can be achieved.
Let’s think of filesystem backups on conventional clients. If using Data Domain, your pattern might look like the following:
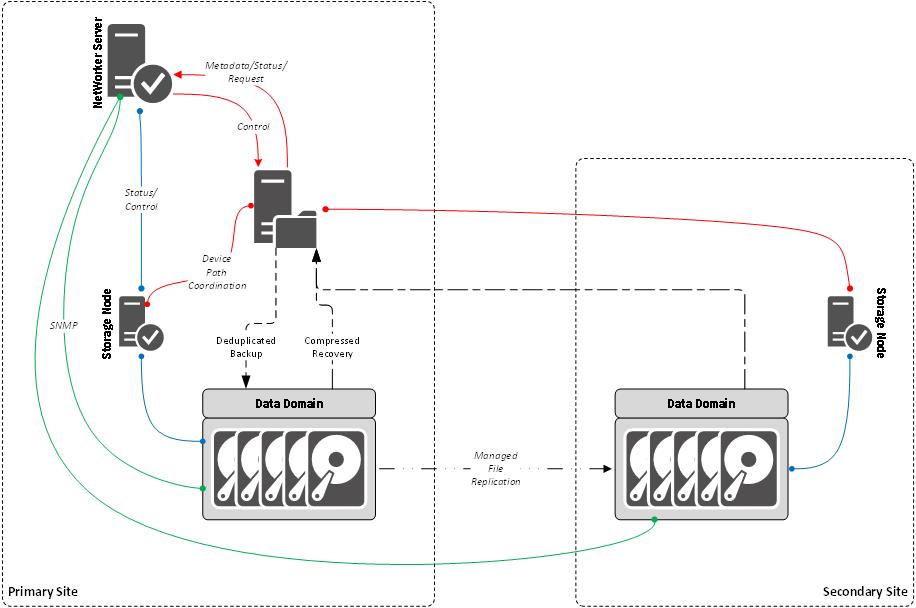
I’m not trying to encapsulate everything in the diagram, but it gives you an overview of the pattern. The diagrammed pattern above gives a view of client-direct backup to Data Domain, with managed file replication, and compressed recovery options from either the local or remote Data Domain.
Likewise, you could generate tape-based patterns such as the following:
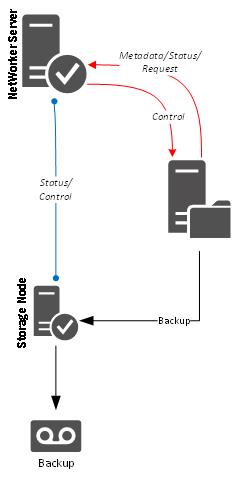
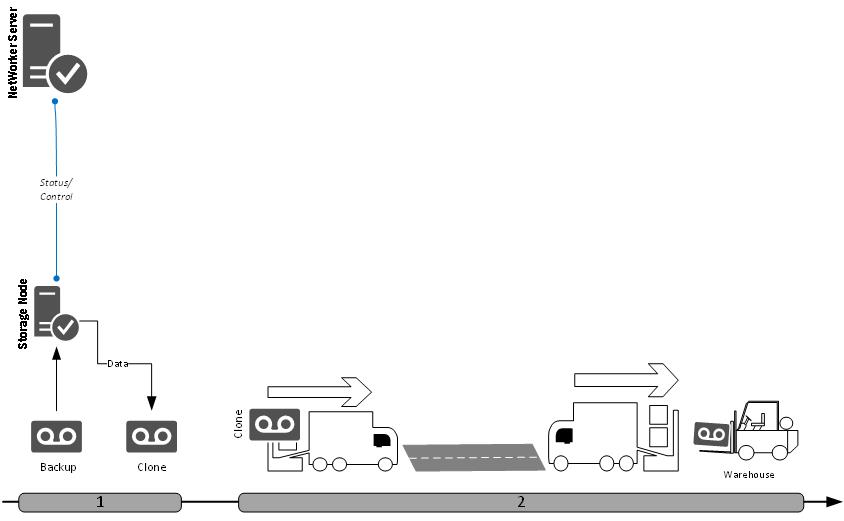
In the final diagram above I’ve introduced numbering to indicate disparate steps. You might even go further and number the communications sequence – but you do run the risk of increasing diagram complexity. For instance, while I was able to cram a lot into the initial Data Domain pattern, once I start enumerating a workflow, it needs to be broken out into multiple diagrams. You might start with the backup/off-siting workflow:
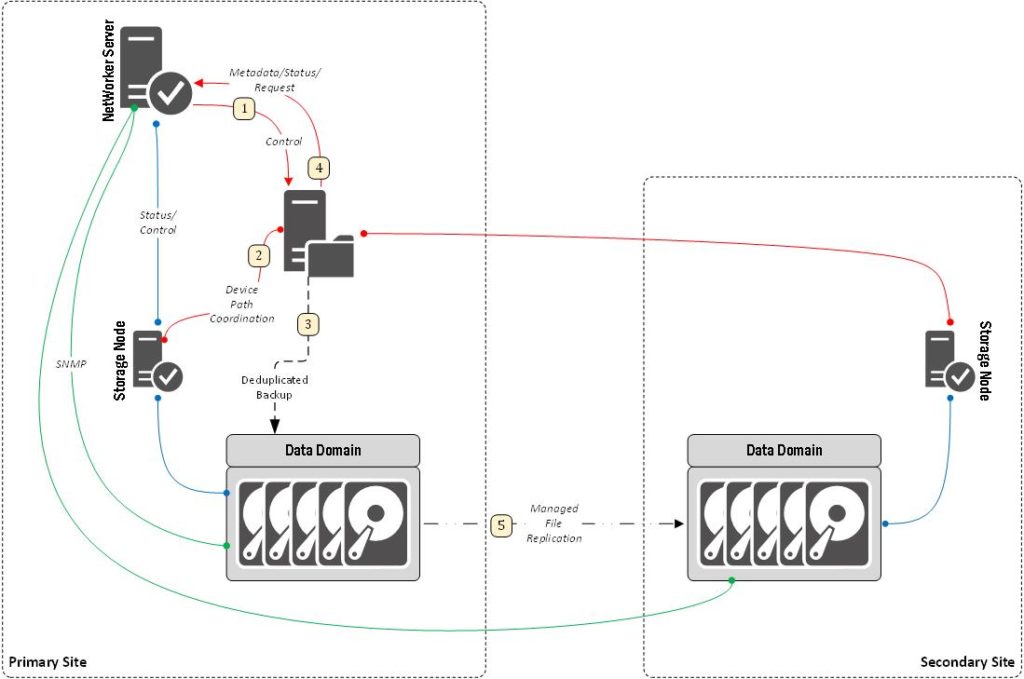
Remember the purpose here is still to keep things to a high-level. The pattern view isn’t meant to show inter-process communication, but the overall process. So from the above, the enumeration would be:
- The server instructs the client to start its backup.
- The client communicates with the storage node to get a path to talk to the Data Domain.
- The client sends deduplicated backup data to the Data Domain.
- The client informs the server of status and sends index information.
- The backup is cloned after successful completion.
You’ll note in the above diagram that some lines aren’t numbered. This marks the difference between background connections and transient connections related to the pattern itself. (You could either continue to show these background connections in every pattern, or you could separate out background and transient connections into separate patterns.)
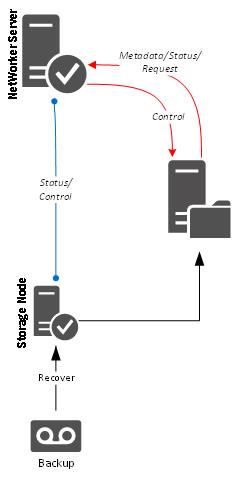
When you start enumerating patterns, you’ll need to leave scope for alternate options within a scenario. For instance, if we look at recovery from the above Data Domain backup, we have two different recovery sources:
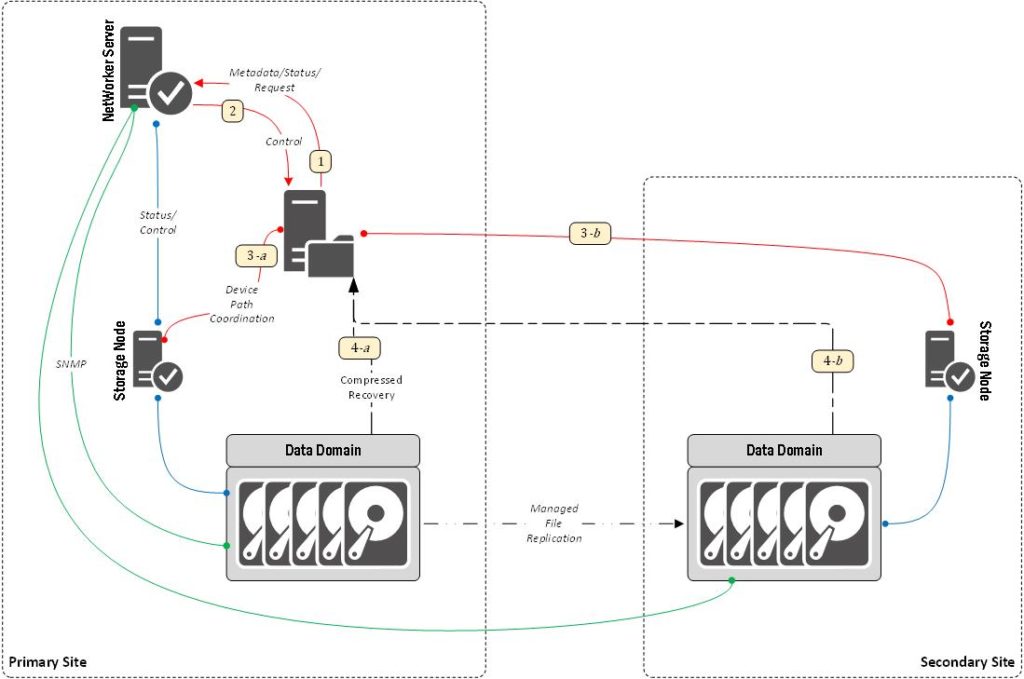
The above diagram shows a client-initiated recovery (as opposed to one you might run from within say, NMC), with enumeration as follows:
- The client connects to the server to request a recovery.
- The server authorises client recovery and directs the client to recover from a nominated storage node.
- The client communicates with the nominated storage node (3-a or 3-b) for access to the data.
- The client retrieves the data from the nominated Data Domain (4-a or 4-b).
One important thing to keep in mind here is to not become mired in complexity: patterns will always gloss over the minutiae; they’re not there for that. (For instance, unless you’re doing a saveset recover, steps 1-2 above are likely to be a bit of a loop to facilitate filesystem browsing. This is not essential to show the overall pattern though.)
Patterns can be developed and documented in a variety of ways. Earlier in my career, I’d have probably just executed them as procedures and merely tried to write a bullet list of how it would work – like the list-form of a flowchart. But I believe there is a real benefit in starting with a drawing of the pattern. It not only lets you visualise it, but it gives you a tool to help you introduce someone else (technical or management) to the process.
As shown in the above diagrams, you can start with a high-level pattern that condenses a lot of potential activity into a single diagram, and from there produce a series of more targeted patterns with enumerated diagrams. These enumerated diagram patterns can then be turned into the procedures I alluded to previously.
If you want a reliable, predictable data protection environment, you should stick to your knitting.