If you use NetWorker with Data Domain, you’ve probably sometimes wanted to know which of your clients have the best deduplication – or perhaps more correctly, you’ve probably wanted to occasionally drill into clients delivering lower deduplication levels.
There are NMC and DPA reports that’ll pull this data for you, but likewise, you can get information directly from mminfo that’ll tell you details about deduplication for Data Domain Boost devices.
You’ll find the information you’re after within the output of mminfo -S. The -S option in mminfo provides a veritable treasure trove of extended details about individual savesets. To give you an example, let’s look at just one saveset in -S format. First, below, you’ll see the mminfo command to identify a saveset ID, then the -S option invoked against a single saveset.
[Sun Oct 24 13:43:02]
## ~
## root@orilla
$ mminfo -q "name=/nsr/scripts,savetime>=4 hours ago" -r "ssid,savetime(20)"
ssid date time
3816067119 24/10/21 09:43:58
3665074337 24/10/21 10:20:00
[Sun Oct 24 13:43:10]
## ~
## root@orilla
$ mminfo -q "ssid=3665074337" -S
ssid=3665074337 savetime=24/10/21 10:20:00 (1635031200) orilla.turbamentis.int:/nsr/scripts
level=manual sflags=vF size=2453183044 files=18 insert=24/10/21
create=24/10/21 complete=24/10/21 browse=24/11/21 10:20:00 retent=24/11/21 23:59:59
clientid=c6fb4ece-00000004-5fdabaf1-5fdabaf0-00019ed8-a41317f3
*backup start time: 1635031200;
*ss data domain backup cloneid: 1635031201;
*ss data domain dedup statistics: "v1:1635031201:2459622768:395458878:151768627";
group: NAS_PMdG;
saveset features: CLIENT_SAVETIME;
Clone #1: cloneid=1635031201 time=24/10/21 10:20:01 retent=24/11/21 flags=
frag@ 0 volid=3923434705 file/rec= 0/0 rn=0 last=24/10/21
There’s a support article that explains how to review this information, here. The line you’re looking for in particular though is the “*ss data domain dedup statistics” – outlined in that aforementioned support article.
I recently wanted to review some deduplication details, and while DPA and NMC are options, I needed to analyse some data over the weekend1 and as such didn’t have access to the live DPA or NMC host for a particular environment. So, since I’m not doing anything social while Melbourne’s COVID case numbers remain so high, I tasked myself with writing a script to analyse deduplication statistics from raw mminfo -S output.
The script I wrote (in Perl, of course), can either be run on a NetWorker server via a query option, or against the saved output of mminfo -S. The usage syntax is this:
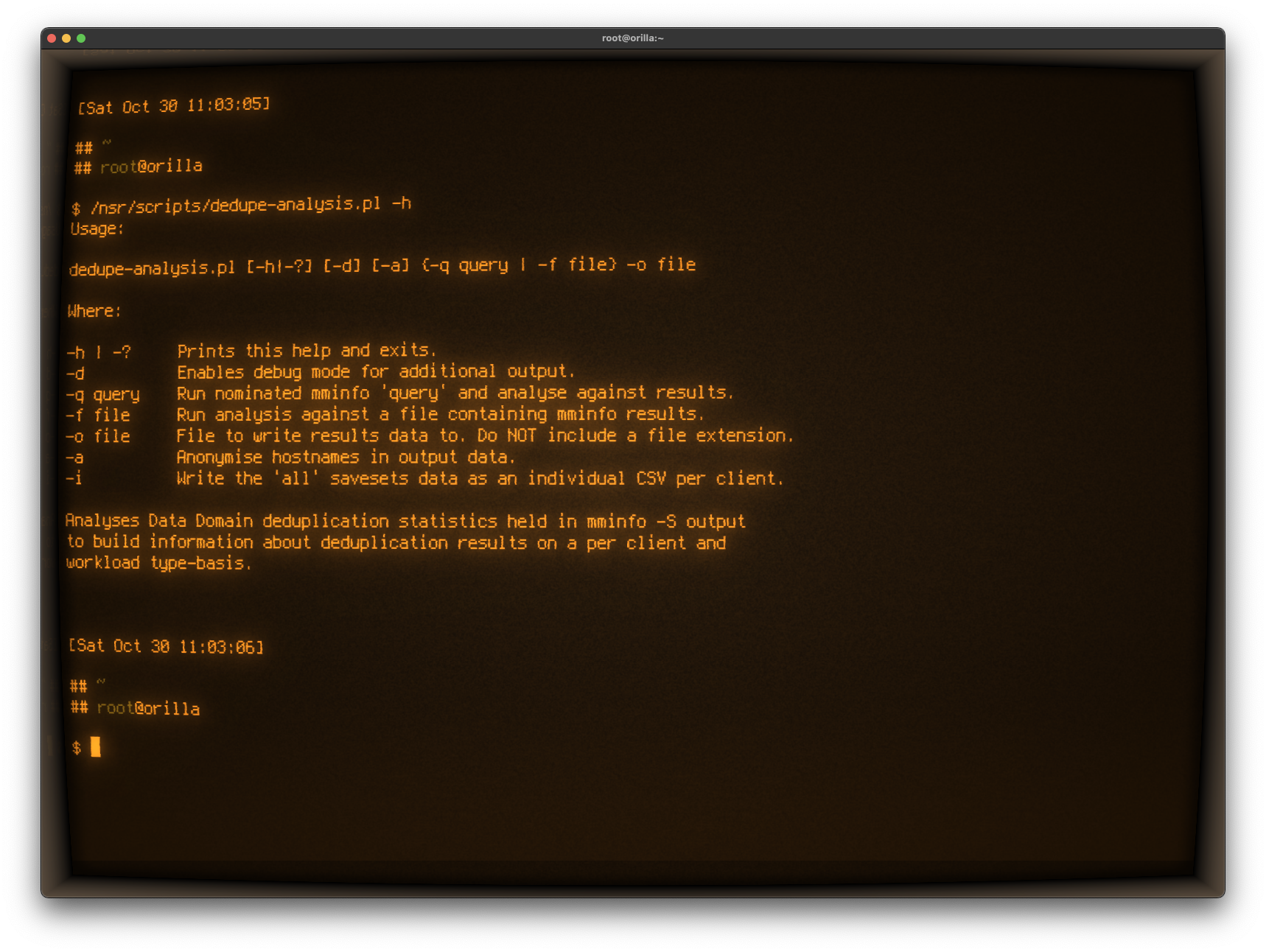
The script pulls the data and outputs at least three key data files, all in CSV format:
- An “all” file that contains deduplication details for each saveset
- A “client” file that contains summarised deduplication details for each client
- A “type” file that contains summarised deduplication details for each client and backup type within the client (e.g., SQL, SAP, Oracle, Exchange, etc.)
Since a saveset, via cloning, can live on more than one Data Domain, the volume IDs are included in the output – and the second two files actually provide the breakdowns first by volume ID – so you can see stats on a per-Data Domain basis. There’s also an option to anonymise the host names in the output, and if you invoke that, a CSV will also be written containing the original hostname to anonymised hostname conversion2. I.e., this would allow you to send the anonymised version to someone for discussion, but privately lookup the real host in any subsequent discussion.
There’s an additional output option too, which can be handy if you’re analysing millions of savesets: it’s an option to create one output file per client. You still get the rollup data, but you’ll also get a per-client CSV file so you can deep-drill into individual client results with a better chance of avoiding Excel’s 1,000,000 row limit.
Here’s an example of an analysis run against my lab environment, with anonymisation turned on:
[Sat Oct 30 11:09:12] ## /nsr/scripts ## root@orilla $ ./dedupe-analysis.pl -q "savetime>=20 years ago" -i -a -o PrestonLab Processing saveset details ...processed 0 savesets ...processed 261 savesets total Writing PrestonLab-all.csv ...written 0 saveset details ...wrote 261 saveset details Written per-saveset details to PrestonLab-all.csv Individual (per-client) file results requested. Processing. ...Writing noumenon.turbamentis.int data to PrestonLab/host-00000000.csv ...Writing orilla.turbamentis.int data to PrestonLab/host-00000001.csv Writing PrestonLab-client.csv Written per-client details to PrestonLab-client.csv Writing PrestonLab-type.csv Written per-client/type details to PrestonLab-type.csv Writing host anonymisation mappings for private reference - do not distribute. ...anonymisation mappings written to PrestonLab-anonmap.csv.
So what sort of output does it generate? For some output examples, I’ve imported the generated CSV files into Excel and converted them to a table. Here’s an example of the “per-saveset” data:
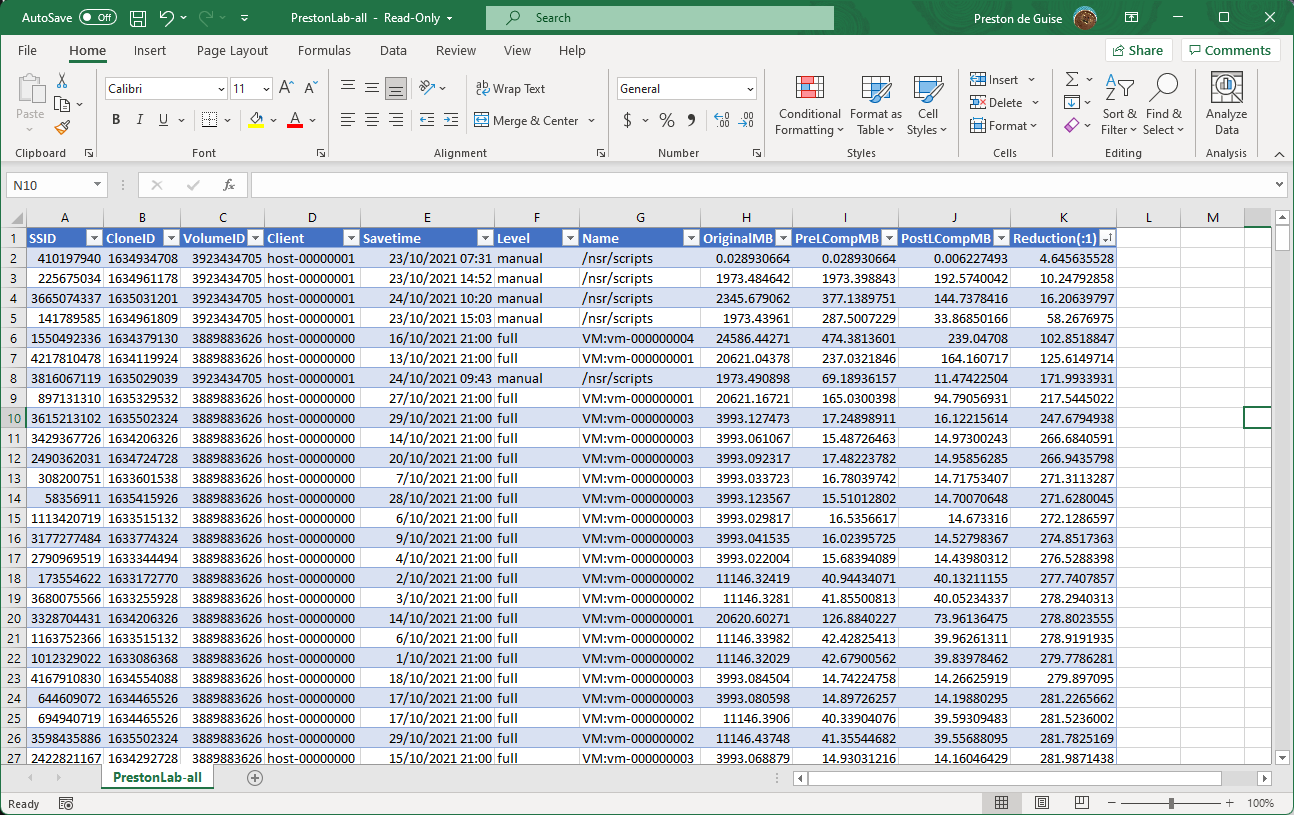
When going by client rollup you’ll see content such as the following:
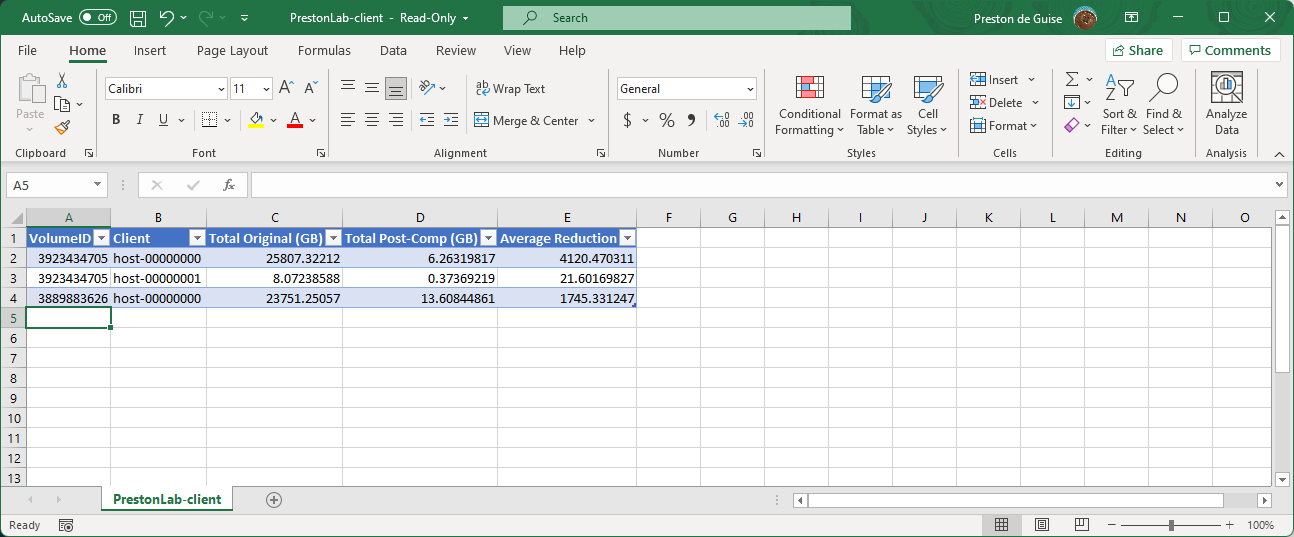
And the backup type output looks like the following:
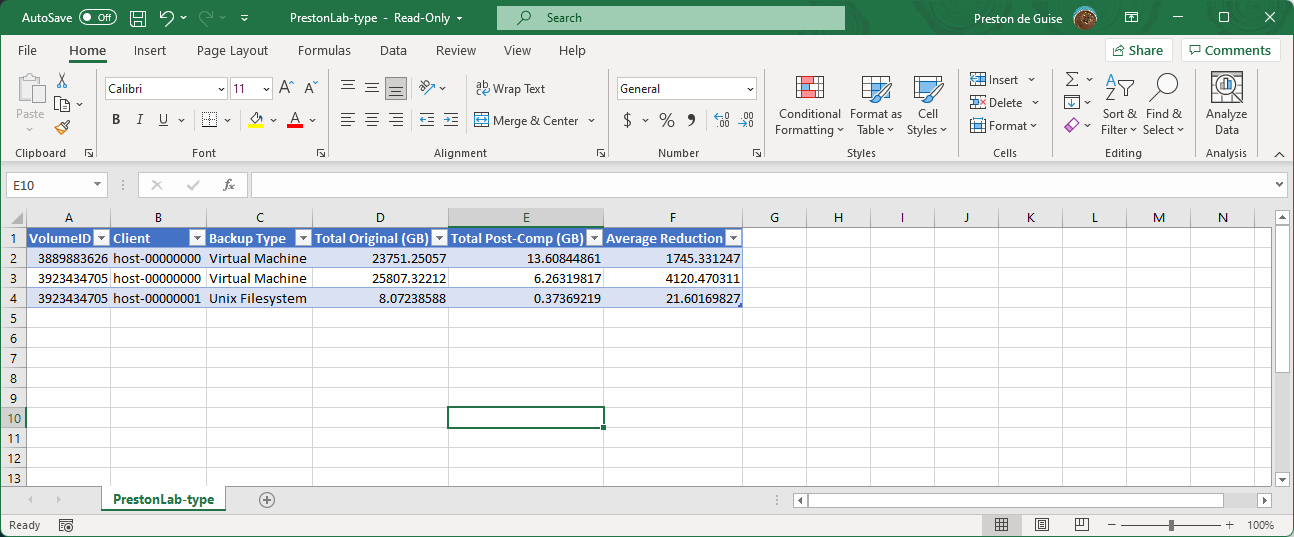
Now, they’re just lab environments there — and while accurate, they’re hardly edifying. What I was working towards was the analysis of a production environment. With host anonymisation turned on, here’s an example of that output:
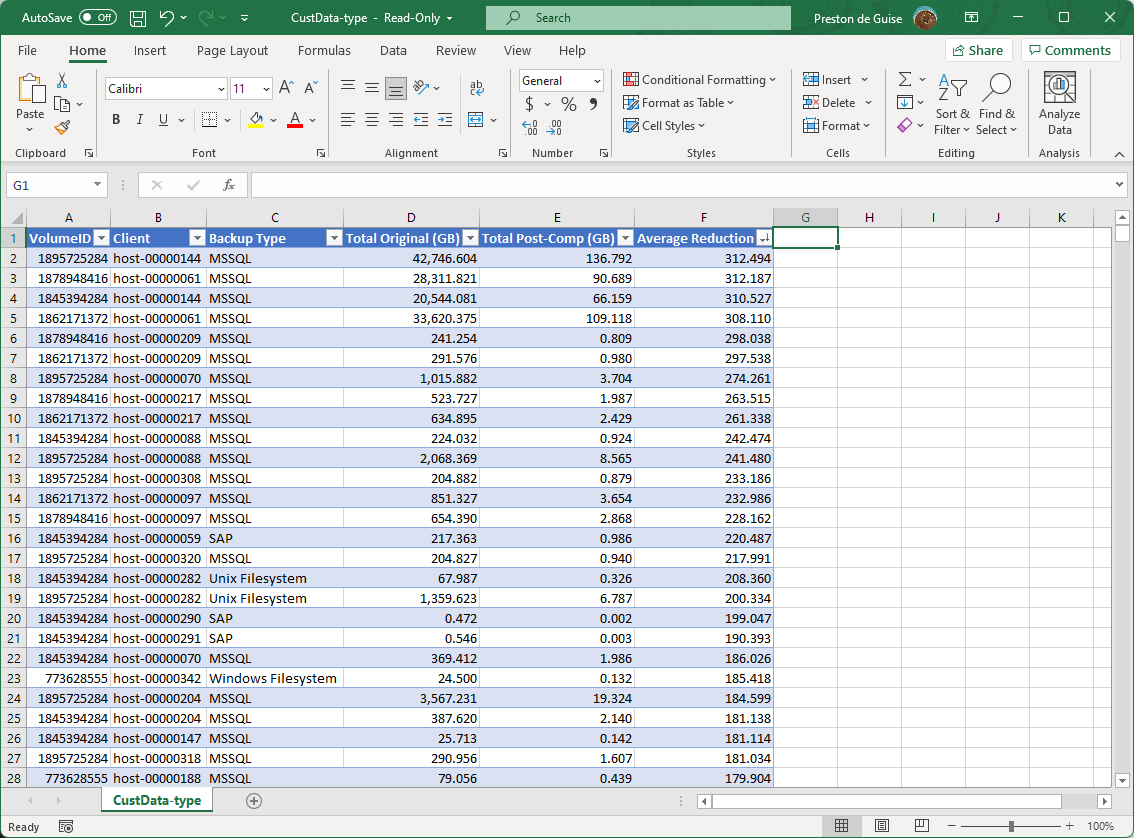
The only additional thing I’ve done in the example output there is to set number formatting on the Original/Post-Comp/Average Reduction columns.
If you’re interested in being able to run this against your own environment (or mminfo -S output, in general), here’s the script:
#!/usr/bin/perl -w
###########################################################################
# Modules
###########################################################################
use strict;
use File::Basename;
use Getopt::Std;
use Sys::Hostname;
###########################################################################
# Subroutines
###########################################################################
# in_list($elem,@list) returns true iff $elem appears in @list.
sub in_list {
return 0 if (@_+0 < 2);
my $element = $_[0];
return 0 if (!defined($element));
shift @_;
my @list = @_;
return 0 if (!@_ || @_+0 == 0);
my $foundCount = 0;
my $e = quotemeta($element);
foreach my $item (@list) {
my $i = quotemeta($item);
$foundCount++ if ($e eq $i);
}
return $foundCount;
}
# show_help([@messages]) shows help, any additional messages, then exits.
sub show_help {
my $self = basename($0);
print <<EOF;
Usage:
$self [-h|-?] [-d] [-a] {-q query | -f file} -o file
Where:
-h | -? Prints this help and exits.
-d Enables debug mode for additional output.
-q query Run nominated mminfo 'query' and analyse against results.
-f file Run analysis against a file containing mminfo results.
-o file File to write results data to. Do NOT include a file extension.
-a Anonymise hostnames in output data.
-i Write the 'all' savesets data as an individual CSV per client.
Analyses Data Domain deduplication statistics held in mminfo -S output
to build information about deduplication results on a per client and
workload type-basis.
EOF
if (@_+0 > 0) {
my @messages = @_;
foreach my $message (@messages) {
my $tmp = $message;
chomp $tmp;
print "$tmp\n";
}
}
die "\n";
}
# get_backup_type($savesetname) returns the guessed backup type based on the saveset name.
sub get_backup_type {
return "Other" if (@_+0 != 1);
my $saveset = $_[0];
my $backupType = "";
if ($saveset =~ /^RMAN/) {
$backupType = "Oracle";
} elsif ($saveset =~ /^backint/) {
$backupType = "SAP";
} elsif ($saveset =~ /^SAPHANA/) {
$backupType = "SAP HANA";
} elsif ($saveset =~ /^VM/) {
$backupType = "Virtual Machine";
} elsif ($saveset =~ /^MSSQL/) {
$backupType = "MSSQL";
} elsif ($saveset =~ /^\// ||
$saveset =~ /^\<\d+\>\//) {
$backupType = "Unix Filesystem";
} elsif ($saveset =~ /^APPLICATIONS.*Exchange/) {
$backupType = "Exchange";
} elsif ($saveset =~ /^[A-Z]\:/ ||
$saveset =~ /SYSTEM/ ||
$saveset =~ /DISASTER/ ||
$saveset =~ /WINDOWS ROLES/ ||
$saveset =~ /\\VOLUME\{/ ||
$saveset =~ /\\\?\\GLOBALROOT/) { # Might need more test cases here
$backupType = "Windows Filesystem";
} elsif ($saveset =~ /^index/ || $saveset =~ /^bootstrap/ ) {
$backupType = "NetWorker";
} else {
$backupType = "Other";
}
return $backupType;
}
###########################################################################
# Globals & main.
###########################################################################
my %opts = ();
my $version = "1.1";
my $method = "query"; # Default method is to seek a query from the command line.
my $query = "";
my $file = "";
my $debug = 0; # Change to 1 for lots of messy debug output.
my $outFile = "";
my $baseOut = "";
my $byClientOut = "";
my $byTypeOut = "";
my $anonOut = "";
my $anonHosts = 0;
my %hostMap = (); # Used for mapping hostnames to anonymised names.
my %vmMap = (); # Used for mapping VM names to anonymised names.
my $hostCount = 0; # Used for iterating anonymised hostnames.
my $vmCount = 0; # Used for iterating anonymised VM names.
my $individualFile = 0;
my %clientElems = (); # If we're doing individual file out, use this to speedily iterate through gathered data.
# Capture command line arguments.
if (getopts('h?vq:f:o:adi',\%opts)) {
show_help() if (defined($opts{'h'}) || defined($opts{'?'}));
show_help("This release: v$version") if (defined($opts{'v'}));
if (defined($opts{'q'})) {
$query = $opts{'q'};
} elsif (defined($opts{'f'})) {
$method = "file";
$file = $opts{'f'};
if (! -f $file) {
show_help("Nominated file, '$file' does not exist or cannot be accessed.");
}
} else {
show_help("You must specify a -q 'query' or -f 'file' option.")
}
$anonHosts = 1 if (defined($opts{'a'}));
$individualFile = 1 if (defined($opts{'i'}));
$debug = 1 if (defined($opts{'d'}));
if (defined($opts{'o'})) {
$outFile = $opts{'o'};
if ($outFile =~ /\./) {
show_help("Please don't give a file extension for the output base filename.");
}
$baseOut = $outFile . "-all.csv";
$byClientOut = $outFile . "-client.csv";
$byTypeOut = $outFile . "-type.csv";
$anonOut = $outFile . "-anonmap.csv";
if (-f $outFile || -f $baseOut || -f $byClientOut || -f $byTypeOut || -f $anonOut) {
show_help("Output file exists. Pick another name.\nSelected output files are:\n" . join("\n",($baseOut,$byClientOut,$byTypeOut,$anonOut)));
}
if ($individualFile && -d $outFile) {
show_help("Individual/per-client output specified but directory $outFile already exists.");
}
} else {
show_help("You have not specified an output file.");
}
}
my %dataSets = ();
my @rawData = ();
my $ssidCount = 0;
my $ddSavesets = 0;
my %volumeIDsbyCloneID = ();
if ($method eq "query") {
my $queryCommand = "mminfo -q \'$query\' -S";
if (open(MMI,"$queryCommand 2>&1 |")) {
while (<MMI>) {
my $line = $_;
chomp $line;
push(@rawData,$line);
if ($line =~ /ss data domain dedup statistics/) {
$ddSavesets++;
}
if ($line =~ /^ssid=\d+/) {
$ssidCount++;
if ($ssidCount % 100000 == 0) {
print "...read $ssidCount saveset details ($ddSavesets on Data Domain)\n";
}
}
}
}
close(MMI);
} elsif ($method eq "file") {
if (open(FILE,$file)) {
while (<FILE>) {
my $line = $_;
chomp $line;
push(@rawData,$line);
if ($line =~ /ss data domain dedup statistics/) {
$ddSavesets++;
}
if ($line =~ /^ssid=\d+/) {
$ssidCount++;
if ($ssidCount % 100000 == 0) {
print "...read $ssidCount saveset details ($ddSavesets on Data Domain)\n";
}
}
}
}
close(FILE);
}
if ($ssidCount == 0) {
die ("Did not find any savesets in an expected format in the $method.\n");
}
if ($ddSavesets == 0) {
die ("Did not find any savesets on a Data Domain in the $method.\n");
}
# Now step through and discard all savesets that aren't on Data Domain devices.
my $count = 0;
my @dataSeg = ();
my $foundADDBoostSS = 0;
for (my $index = 0; $index < (@rawData+0); $index++) {
my $line = $rawData[$index];
if ($line =~ /^ssid/) {
if ($index != 0) {
# If we're at index 0 we're at the start of the file. We'll see
# a line starting with 'ssid' but we won't have a prior record
# to add to our dataSets.
if ($foundADDBoostSS) {
$debug && print "DEBUG: Boost saveset processing at index $index\n";
$dataSets{$count} = join("\n",@dataSeg);
@dataSeg = ();
$foundADDBoostSS = 0;
$count++;
$debug && print "DEBUG: Incremented count to $count\n";
}
}
@dataSeg = ($line);
} else {
push (@dataSeg,$line);
}
if ($line =~ /ss data domain dedup statistics/) {
$foundADDBoostSS = 1;
}
}
# Explicitly free up the initially read data. This is useful if you have >1M savesets
# in reducing the runtime footprint. (E.g., on sample of 1.7M savesets it uses 1/3 less
# memory over runtime.)
$debug && print "DEBUG: Deallocating raw data.\n";
undef @rawData;
my %procData = ();
my $datum = 0;
my $procCount = 0;
print "\n\nProcessing saveset details\n";
foreach my $key (sort {$a <=> $b} keys %dataSets) {
my $block = $dataSets{$key};
my @block = split(/\n/,$block);
my $ssid = "";
my $savetime = "";
my $nsavetime = "";
my $client = "";
my $saveset = "";
my $level = "";
my $ssflags = "";
my $totalsize = 0;
my $retention = "";
my $dedupeStats = "";
my $vmname = "";
if ($procCount % 100000 == 0) {
print " ...processed $procCount savesets\n";
}
$procCount++;
my $vm = 0;
my $blockIndex = 0;
foreach my $item (@block) {
if ($item =~ /^ssid=(\d+) savetime=(.*) \((\d+)\) ([^:]*):(.*)/) {
$ssid = $1;
$savetime = $2;
$nsavetime = $3;
$client = $4;
$saveset = $5;
$procData{$datum}{ssid} = $ssid;
$procData{$datum}{savetime} = $savetime;
$procData{$datum}{client} = $client;
$procData{$datum}{nsavetime} = $nsavetime;
$procData{$datum}{saveset} = $saveset;
if ($anonHosts) {
if (%hostMap && defined($hostMap{$client})) {
# Nothing to do here.
} else {
$hostMap{$client} = sprintf("host-%08d",$hostCount);
$hostCount++;
}
}
$debug && print "\nDEBUG: START $ssid ($savetime - $nsavetime): $client|$saveset\n";
}
if ($item =~ /^\s*Clone \#\d+: cloneid=(\d+)/) {
my $cloneID = $1;
my $volID = 0;
# Here we assume any DD saveset only has a single frag to keep
# things simple. This may break if someone clones something out
# to tape.
my $nextLine = $block[$blockIndex+1];
if (!defined($nextLine)) {
# Orphaned saveset/clone instance without a volume. Set VolID to Zero.
$volID = 0;
} else {
if ($nextLine =~ /.*volid=\s*(\d+) /) {
$volID = $1;
} else {
# Something odd going on here. Set VolID to Zero.
$volID = 0;
}
}
$volumeIDsbyCloneID{$ssid}{$cloneID} = $volID;
}
if ($item =~ /vcenter_hostname/) {
$vm = 1;
}
if ($vm == 1 && $item =~ /^\s+\\"name\\": \\"(.*)\\"/) {
$vmname = $1;
if ($anonHosts) {
if (%vmMap && defined($vmMap{$vmname})) {
$procData{$datum}{vmname} = $vmMap{$vmname};
} else {
$vmMap{$vmname} = sprintf("vm-%09d",$vmCount);
$vmCount++;
$procData{$datum}{vmname} = $vmMap{$vmname};
}
} else {
$procData{$datum}{vmname} = $vmname;
}
$vm = 0;
}
if ($item =~ /^\s+level=([^\s]*)\s+sflags=([^\s]*)\s+size=(\d+).*/) {
$level = $1;
$ssflags = $2;
$totalsize = $3;
$procData{$datum}{level} = $level;
$procData{$datum}{ssflags} = $ssflags;
$procData{$datum}{totalsize} = $totalsize;
$debug && print "DEBUG: ----> Level = $level, ssflags = $ssflags, totalsize = $totalsize\n";
}
if ($item =~ /create=.* complete=.* browse=.* retent=(.*)$/) {
$retention = $1;
$procData{$datum}{retention} = $retention;
$debug && print "DEBUG: ----> Retention = $retention\n";
}
if ($item =~ /^\*ss data domain dedup statistics: "(.*)"(\,|;)\s*$/) {
$dedupeStats = $1;
my $eol = $2;
if ($eol eq ",") {
my $stop = 0;
my $lookahead = $blockIndex + 1;
while (!$stop) {
my $tmpLine = $block[$lookahead];
if ($tmpLine =~ /^\s*"(.*)"(\,|;)\s*$/) {
my $tmpstat = $1;
my $tmpset = $2;
$dedupeStats .= "\n" . $tmpstat;
$stop = 1 if ($tmpset eq ";");
}
$lookahead++;
}
}
$procData{$datum}{dedupe_stats} = $dedupeStats;
$debug && print "DEBUG: ----> Dedupe stats: " . join("|||",split(/\n/,$dedupeStats)) . "\n";
} elsif ($item =~ /^\*ss data domain dedup statistics: \\\s*$/) {
my $stop = 0;
my $lookahead = $blockIndex + 1;
while (!$stop) {
my $tmpLine = $block[$lookahead];
if ($tmpLine =~ /^\s*"(.*)"(\,|;)\s*$/) {
my $tmpstat = $1;
my $tmpset = $2;
$dedupeStats .= "\n" . $tmpstat;
$stop = 1 if ($tmpset eq ";");
}
$lookahead++;
}
$dedupeStats =~ s/^\n(.*)/$1/s;
$procData{$datum}{dedupe_stats} = $dedupeStats;
$debug && print "DEBUG: ----> Dedupe stats: " . join("|||",split(/\n/,$dedupeStats)) . "\n";
}
$blockIndex++;
}
$datum++;
}
print (" ...processed $procCount savesets total\n");
# Now dump $dataSets to save memory. This doesn't save as much
# as the previous @rawData drop but retaining in case it's useful
# for someone on a low-memory system.
$debug && print "DEBUG: Deallocating pre-parsed datasets.\n";
undef %dataSets;
# Now do a quick post-process through the clients if we have host anonymisation turned on
# to catch any index savesets and adjust them. It should be safe to do so here.
if ($anonHosts) {
foreach my $elem (keys %procData) {
if ($procData{$elem}{saveset} =~ /^index:(.*)/) {
my $indexHostname = $1;
if (%hostMap && defined($hostMap{$indexHostname})) {
$procData{$elem}{saveset} = "index:" . $hostMap{$indexHostname};
} else {
$hostMap{$indexHostname} = sprintf("host-%08d",$hostCount);
$hostCount++;
$procData{$elem}{saveset} = "index:" . $hostMap{$indexHostname};
}
}
}
}
my %clientData = ();
# As we write out the base file, assemble the client rollup data.
my @clients = ();
print ("\n\nWriting $baseOut\n");
my $countOut = 0;
if (open(OUTP,">$baseOut")) {
print OUTP ("SSID,CloneID,VolumeID,Client,Savetime,Level,Name,OriginalMB,PreLCompMB,PostLCompMB,Reduction(:1)\n");
foreach my $elem (keys %procData) {
my $dedupeStats = $procData{$elem}{dedupe_stats};
my @dedupeStats = split("\n",$dedupeStats);
if ($countOut % 100000 == 0) {
print " ...written $countOut saveset details\n";
}
$countOut++;
foreach my $stat (@dedupeStats) {
if ($stat =~ /^v1:(\d+):(\d+):(\d+):(\d+)/) {
my $clID = $1;
my $original = $2;
my $precomp = $3;
my $postcomp = $4;
my $client = $procData{$elem}{client};
my $saveset = $procData{$elem}{saveset};
my $savetime = $procData{$elem}{savetime};
my $ssid = $procData{$elem}{ssid};
my $level = $procData{$elem}{level};
my $vmName = (defined($procData{$elem}{vmname})) ? $procData{$elem}{vmname} : "";
my $volumeID = $volumeIDsbyCloneID{$ssid}{$clID};
# Only build up the client<>element mappings if we have to output
# individual clients.
if ($individualFile) {
if (in_list($client,@clients)) {
push(@{$clientElems{$client}},$elem);
} else {
push (@clients,$client);
@{$clientElems{$client}} = ($elem);
}
}
if ($vmName ne "") {
$saveset = "VM:$vmName";
}
$original = $original / 1024 / 1024; #MB
$precomp = $precomp / 1024 / 1024; #MB
$postcomp = $postcomp / 1024 / 1024; #MB
my $reduction = $original / $postcomp; #:1
my $backupType = get_backup_type($saveset);
$procData{$elem}{backuptype} = $backupType; # Store this in case we need it for individuals.
if (%clientData &&
defined($clientData{by_client}) &&
defined($clientData{by_client}{$volumeID}) &&
defined($clientData{by_client}{$volumeID}{$client})) {
$clientData{by_client}{$volumeID}{$client}{original} += $original / 1024;
$clientData{by_client}{$volumeID}{$client}{postcomp} += $postcomp / 1024;
$clientData{by_client}{$volumeID}{$client}{count}++;
} else {
$clientData{by_client}{$volumeID}{$client}{original} = $original / 1024; # Store in GB
$clientData{by_client}{$volumeID}{$client}{postcomp} = $postcomp / 1024; # Store in GB
$clientData{by_client}{$volumeID}{$client}{count} = 1;
}
if (%clientData &&
defined($clientData{by_type}) &&
defined($clientData{by_type}{$volumeID}) &&
defined($clientData{by_type}{$volumeID}{$client}) &&
defined($clientData{by_type}{$volumeID}{$client}{$backupType})) {
$clientData{by_type}{$volumeID}{$client}{$backupType}{original} += $original / 1024; # Store in GB
$clientData{by_type}{$volumeID}{$client}{$backupType}{postcomp} += $postcomp / 1024; # Store in GB
$clientData{by_type}{$volumeID}{$client}{$backupType}{count}++;
} else {
$clientData{by_type}{$volumeID}{$client}{$backupType}{original} = $original / 1024; # Store in GB
$clientData{by_type}{$volumeID}{$client}{$backupType}{postcomp} = $postcomp / 1024; # Store in GB
$clientData{by_type}{$volumeID}{$client}{$backupType}{count} = 1;
}
my $finalClientName = ($anonHosts == 1) ? $hostMap{$client} : $client;
print OUTP ("$ssid,$clID,$volumeID,$finalClientName,$savetime,$level,$saveset,$original,$precomp,$postcomp,$reduction\n");
if ($debug) {
print ("DEBUG: " . $client . "," . $saveset . " (ClID $clID)\n");
printf ("DEBUG: Original Size: %.2f MB\n",$original);
printf ("DEBUG: Pre-LComp: %0.2f MB\n",$precomp);
printf ("DEBUG: Post-LComp: %0.2f MB\n",$postcomp);
printf ("Debug: Reduction: %0.2f:1\n",$reduction);
print "DEBUG: \n";
}
}
}
}
}
close(OUTP);
print " ...wrote $countOut saveset details\n";
print "Written per-saveset details to $baseOut\n";
# If we need to output per-client details, do that now.
if ($individualFile) {
print "Individual (per-client) file results requested. Processing.\n";
mkdir("$outFile");
if (-d $outFile) {
foreach my $client (sort {$a cmp $b} @clients) {
my $filename = $client;
# Override here.
if ($anonHosts) {
$filename = $hostMap{$client};
}
$filename =~ s/\./_/g;
$filename = $outFile . "/" . $filename . ".csv";
if (open(OUTP,">$filename")) {
print " ...Writing $client data to $filename\n";
print OUTP ("SSID,CloneID,VolumeID,Client,VMName,Savetime,Level,Name,OriginalMB,PreLCompMB,PostLCompMB,Reduction(:1)\n");
my @elemList = @{$clientElems{$client}};
foreach my $elem (@elemList) {
next if ($procData{$elem}{client} ne $client);
# Else...
my $dedupeStats = $procData{$elem}{dedupe_stats};
my @dedupeStats = split("\n",$dedupeStats);
foreach my $stat (@dedupeStats) {
if ($stat =~ /^v1:(\d+):(\d+):(\d+):(\d+)/) {
my $clID = $1;
my $original = $2;
my $precomp = $3;
my $postcomp = $4;
my $saveset = $procData{$elem}{saveset};
my $savetime = $procData{$elem}{savetime};
my $ssid = $procData{$elem}{ssid};
my $level = $procData{$elem}{level};
my $vmName = (defined($procData{$elem}{vmname})) ? $procData{$elem}{vmname} : "";
my $volumeID = $volumeIDsbyCloneID{$ssid}{$clID};
push (@clients,$client) if (!in_list($client,@clients));
if ($vmName ne "") {
$saveset = "VM:$vmName";
}
$original = $original / 1024 / 1024; #MB
$precomp = $precomp / 1024 / 1024; #MB
$postcomp = $postcomp / 1024 / 1024; #MB
my $reduction = $original / $postcomp; #:1
my $backupType = $procData{$elem}{backuptype};
my $finalClient = ($anonHosts == 1) ? $hostMap{$client} : $client;
my $finalSaveset = "";
if ($anonHosts) {
if ($vmName ne "") {
$finalSaveset = $vmName;
} else {
$finalSaveset = $saveset;
}
} else {
$finalSaveset = $saveset;
}
print OUTP ("$ssid,$clID,$volumeID,$finalClient,$vmName,$savetime,$level,$finalSaveset,$original,$precomp,$postcomp,$reduction\n");
}
}
}
}
close(OUTP);
}
} else {
die "Unable to create directory $outFile\n";
}
}
# Write file: Summary by VolumeID and Client.
print("\n\nWriting $byClientOut\n");
if (open(OUTP,">$byClientOut")) {
print OUTP ("VolumeID,Client,Total Original (GB),Total Post-Comp (GB),Average Reduction\n");
foreach my $volumeID (keys %{$clientData{by_client}}) {
foreach my $client (sort {$a cmp $b} keys %{$clientData{by_client}{$volumeID}}) {
my $finalClientName = ($anonHosts == 1) ? $hostMap{$client} : $client;
printf OUTP ("%s,%s,%.8f,%.8f,%.8f\n",
$volumeID,
$finalClientName,
$clientData{by_client}{$volumeID}{$client}{original},
$clientData{by_client}{$volumeID}{$client}{postcomp},
$clientData{by_client}{$volumeID}{$client}{original} / $clientData{by_client}{$volumeID}{$client}{postcomp});
}
}
}
close(OUTP);
print "Written per-client details to $byClientOut\n";
# Write file: Summary by VolumeID, Client and BackupType.
print ("\n\nWriting $byTypeOut\n");
if (open(OUTP,">$byTypeOut")) {
print OUTP ("VolumeID,Client,Backup Type,Total Original (GB),Total Post-Comp (GB),Average Reduction\n");
foreach my $volumeID (sort {$a cmp $b} keys %{$clientData{by_type}}) {
foreach my $client (sort {$a cmp $b} keys %{$clientData{by_type}{$volumeID}}) {
foreach my $type (sort {$a cmp $b} keys %{$clientData{by_type}{$volumeID}{$client}}) {
my $finalClientName = ($anonHosts == 1) ? $hostMap{$client} : $client;
printf OUTP ("%s,%s,%s,%.8f,%.8f,%.8f\n",
$volumeID,
$finalClientName,
$type,
$clientData{by_type}{$volumeID}{$client}{$type}{original},
$clientData{by_type}{$volumeID}{$client}{$type}{postcomp},
$clientData{by_type}{$volumeID}{$client}{$type}{original} / $clientData{by_type}{$volumeID}{$client}{$type}{postcomp});
}
}
}
}
close(OUTP);
print "Written per-client/type details to $byTypeOut\n";
# If we're anonymising hosts, write data that can be kept private to map
# anonymised hostnames to real hostnames.
if ($anonHosts) {
print "\n\nWriting host anonymisation mappings for private reference - do not distribute.\n";
if (open(ANONMAP,">$anonOut")) {
print ANONMAP "Client Name,Anonymous Mapping\n";
foreach my $client (sort {$a cmp $b} keys %hostMap) {
print ANONMAP "$client,$hostMap{$client}\n";
}
print ANONMAP "\n";
print ANONMAP "Virtual Machine,Anonymous Mapping\n";
foreach my $vm (sort {$a cmp $b} keys %vmMap) {
print ANONMAP "$vm,$vmMap{$vm}\n";
}
close (ANONMAP);
}
print "...anonymisation mappings written to $anonOut.\n";
}
One thing to note in the script — the breakdown of what types of backups there are was dependent on the saveset information that I had available to me. So it while it covers things like Windows and Unix filesystems, Oracle, SAP and MSSQL, it doesn’t include coverage for identifying Lotus Notes, DB2, and so on. (There’s a subroutine, get_backup_type, that interprets the backup type from the saveset name, that you’d need to modify if you wanted additional types.)
Cool and helpful scrip -> thx. for sharing this!
Kr,
Michael