
I’ve seen a lot of talk lately of data hoarding. Data can bring us new insights, new business opportunities, and all those other good things — so it stands to reason that even if you can’t think of a use for data today, you might think of a use later. Therefore, once you capture the data into the gravity-well of your infrastructure, you don’t let it go, because it might be a missed opportunity.
In short, deleting data when you might need later could be deadly to the business.
But here’s the rub: hoarding data you don’t need yet without managing it is just as deadly.
Leveraging data can bring in new income streams, or amplify existing ones. But data also has a cost — the cost of storing it, protecting it and managing it. When you’re hoarding data, you’re accepting there is an up-front cost associated with that hoarding which only might someday pay off for the business.
Here’s a slight modification to a data lifecycle management diagram I included in the second edition of Data Protection:
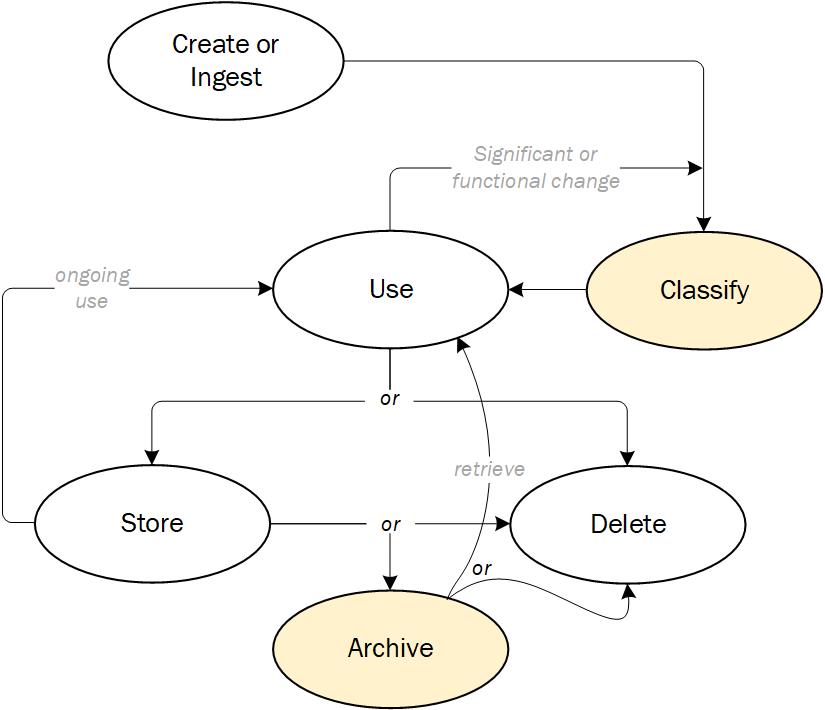
My take is this: if you’re hoarding data but not managing it like the above, you’re needlessly wasting money.
For every 1TB of data you have sitting in primary storage, you’re probably consuming 30-50TB or more in protection/logical storage. RAID, Snapshots, Replica, Operational Backup Retention, Replicated Operational Backup Retention, Long-Term Backup Retention, Replication Long-Term Backup Retention. Then, assuming you’re not wall-to-wall with tape, all those backups will have RAID and a some of them will have snapshots, too.
That 1TB of data you decide to store on your primary systems is the proverbial pebble kicking off a land-slide down the side of the mountain. Yes, to be sure, deduplication can help save your storage footprint along the way, for primary storage and data protection, but it’s not magic. Deduplication is not a singularity — it doesn’t crush data away to nothing. (Sure, you could deduplicate everything down to a single 0 and a single 1, but the metadata will then crush you.)
Ask yourself this: how much of your annual data growth comes from true data growth, and how much comes from hoarded data? You know, the data that no-one wants to delete, just in case.
If your business is going to do data-hoarding, it needs to do archive. The only way you stop every TB of data you hoard just in case from crippling storage, infrastructure and data protection costs is to remove it from those equations. Take it off primary storage. Limit the infrastructure for storage. Remove it from data protection. Properly archived, it can sit in your environment for as long as you want, still be accessible, still be found, still be indexed, ready and waiting for its purpose to be discovered.
If you’re looking for a cost-effective way to hoard data, you’d do well to look into ECS.