
(…though most businesses get Long Term Retention wrong even with databases)
Introduction
The information age is one that has a curious dichotomy. We are at a time, more so than ever, where we can preserve almost limitless amounts of data. Yet this makes us vulnerable to significant amounts of data loss. This may be deletion, it may be availability, or it may be compatibility.
It is of compatibility that I want to talk about today.
To explain compatibility, I’ll start by explaining what I meant by “Look to the Database Model”.
Most relational databases differentiate between data restoration and database recovery. There is, in fact, a very important difference between the two, which is often forgotten outside of databases. (Hint: everyone who works in data protection should always be mindful of restore vs recover.)
While some database vendors may switch the terms around, the breakdown between them is often as follows:
- Restore: Retrieve the data file(s) from the backup medium
- Recover: Integrate the data file(s) and any archive logs to achieve database consistency.
In essence, there is a differentiation between getting the files back and having usable data. This is, in my mind, the problem that is ignored when businesses are planning for long-term retention. And this is where I noted at the top of the article that ironically, this problem also happens with databases. Let me explain:
Congratulations, you can restore the files from your Oracle 9 database backup that was taken on an AIX PowerPC platform! Now, how do you integrate them into your x86_64 Exadata Oracle 21 platform?
In that one example, you’re dealing with:
- Different operating systems
- Different database versions
- Different CPUs
- Different endian formats
This sort of long-term retention can trigger the eBay problem: i.e., step 1 of your recovery is to go to eBay and hope that you can find compatible hardware on the second-hand market to recover with.
There is nothing invalid about using your backup and recovery environment for long-term retention. But you have to ask yourself a fundamental question: if it more important to get the file back, or the data? They’re not the same thing, after all. The file contains the data, of course, but it contains it in a specific format. Do you need the data in that format, or do you need the data accessible? Which is more important to the business?
There are two ways to address this:
- Über-backups or Golden-State Backups.
- Data-only backups.
What’s an Über backup/Golden-state backup?
An über backup is one that includes everything you need to recover the full state of the data you’re protecting. Yes, that includes the file(s) that you need to protect, but it includes everything you need to then access those files. Let’s think of the Oracle example:
- The database backup.
- Operating system installation media.
- Database server installation media.
- Database server patches.
- Configuration documentation for the database installation.
- Configuration documentation for the operating system installation.
- Data protection client software used for the backup.
- Data protection server software used for the backup.
- License information for the operating system.
- License information for the database server.
- License information for the data protection software.
- Recovery documentation.
In short: in several years X from now, to fully recover the database backup you’re taking today, you may need to reconstruct the operating system, make sure filesystem layouts are the same, deploy the same backup software, redeploy the database server software, and then recover the database.
Do you need to store all that data with every long-term retention backup? Probably not, unless you’re extremely paranoid, or under heinously strict compliance requirements. So to avoid onerously complex and large backups, you’ll settle for a ‘golden-state backup’; in addition to those compliance backups, you’ll make sure you periodically backup all the surrounding elements described above – maybe with the same frequency as your compliance backups, maybe a little less frequently … but likely at least every three months or so. A quarterly copy of all of the software installers, operating systems, data protection applications, etc., with the same retention as all the systems being protected is a sensible alternative to the über backup scenario.
The problem of course with either an über backup or a golden-state backup is that they only address the soft items required for full data access. If you need completely different hardware to deploy that software on, then you’re still looking at eBay being a step in your recovery process.
In fact, they may not even address all the soft issues, either. For example, Microsoft Windows has increasingly relied on an online activation process for operating system installs as part of Microsoft’s defence process against piracy. Let’s say you’ve saved ISOs for Windows 2003 as part of the backup … but, did you want to activate the Windows 2003 server install? Here’s a gotcha: the activation services for that operating system no longer exist. So, would you make it past the installation?
So, über backups or golden-state backups will put you closer to the goal of being able to recover your data — i.e., recover it in a usable format. But they’re not a 100% guarantee if hardware platforms have significantly shifted underneath, or necessary licensing systems are no longer available for use.
What’s a data-only backup?
A data-only backup is built around the idea that after potentially many years, all you really care about is getting the data back.
Using our database example from before, you might ask yourself: do you need to be able to recover an Oracle 9 database in 7 years time, or do you need to recover the data that was held in the database? If this is the case, is an export more cross-generational compatible for recovery purposes? Sure, it may not look as pretty, but it has all the content you want, and it you’ll be able to read it regardless of whether your business is using Oracle, Ingres, Sybase, PostgreSQL or megaVi3000+.
In this model, we’re very much fixated on the difference between a file is a container for data and data is only part of the file. Even at an individual file level, as soon as you have any hint of a proprietary format for a file, you have the core data within the file, and then you have the file structure (the “document format”) that encapsulates it.
A modern Microsoft Word document for instance is actually just a fancy zip file that contains a bunch of individual files which comprise the content, styles, and media within the document:
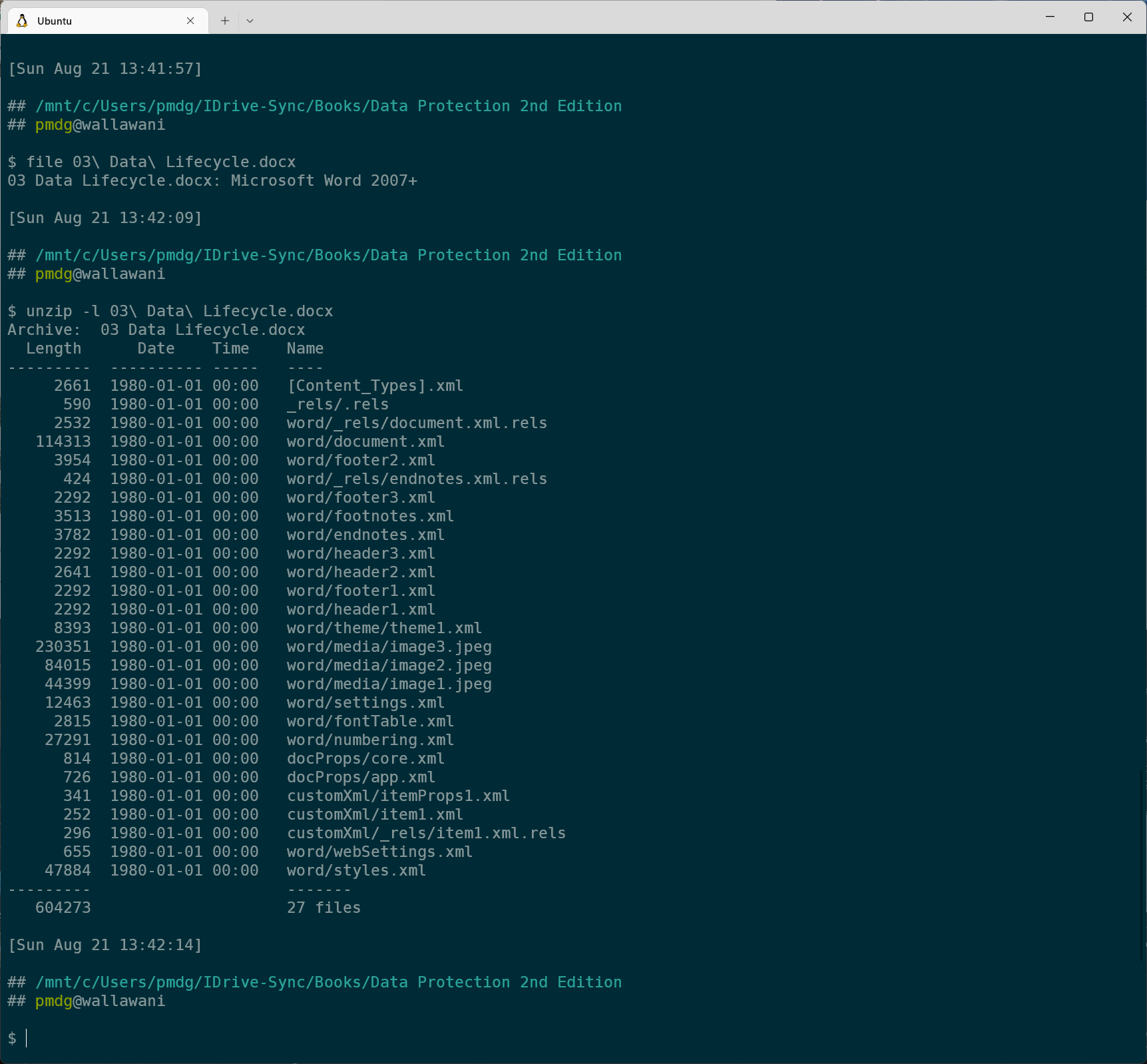
This sort of containerised content is actually pretty common among many platforms these days. (Apple’s macOS likewise disguises often complex file and folder hierarchies as a single app bundle.)
If you’re talking to true archival businesses (e.g., government national archives), you’ll find they have an obsessive paranoia about the long-term reliability of data — or rather, file — formats. It’s not uncommon to see a requirement for all data to be stored in at least three different formats. A Microsoft Word document might be stored in its original format, for sure. But it’ll likely be stored in other formats as well, such as Rich Text Format (RTF), PDF, and even plain ASCII text.
If your long-term retention stretches into the multi-decade view, you might want to consider adopting a similar paranoia about individual file formats as well. But even if you don’t extend to that level, you might consider some basic protections — such as having über-backups and data-only backups. Or at least, multi-format backups. For instance, you might want to keep your virtual machine image-level backups for the full compliance retention for ‘easy’ recovery, but you may also do agent-based file-level backups too, so that if you change your virtualisation platform (or its data format drifts too much) you’ll still be able to get some form of the data back.
Work now, or Work Later?
Unless your business is a considerable outlier (or a national archives service), you’ll find that the vast majority of your recoveries are done against data backed up in a window of around 1-7 days.
Yet, if you’re keeping compliance copy backups, the vast majority of your backups are going to be long-term retention backups. In fact, long-term retention backups may represent up to 95% of your total backup storage.
So you have to ask yourself: do you put in the work now for making sure the data from those long-term retention backups are not only restorable, but also recoverable, or do you trust that for the entire time you have to retain them, there won’t be any sufficient shift in platform, product or data format that’ll make it challenging to get the data back in a form you can use?
I’ll leave you with a parting quote:
“Oxford economics historian Avner Offer believes that we’re hopelessly myopic. When left to our own devices, we’ll choose what’s nice for us today over what’s best for us tomorrow. In a life of noise and speed, we’re constantly making decisions that our future self wouldn’t make.”
“The Freedom of Choice”, p12, New Philosopher, Issue 6: November 2014 – January 2015.
You’ll note from the similar links below that this isn’t the first time I’ve written about this topic. I hadn’t forgotten the previous times, but I think this topic is far more important than most businesses give credit to, so I like to revisit it periodically.
1 thought on “When planning for long term retention, look to the database model”