When NetWorker and Data Domain are working together, some operations can be done as a virtual synthetic full. It sounds like a tautology – virtual synthetic. In this basics post, I want to explain the difference between a synthetic full and a virtual synthetic full, so you can understand why this is actually a very important function in a modernised data protection environment.
The difference between the two operations is actually quite simple, and best explained through comparative diagrams. Let’s look at the process of creating a synthetic full, from the perspective of working with AFTDs (still less challenging than synthetic fulls from tape), and working with Data Domain Boost devices.
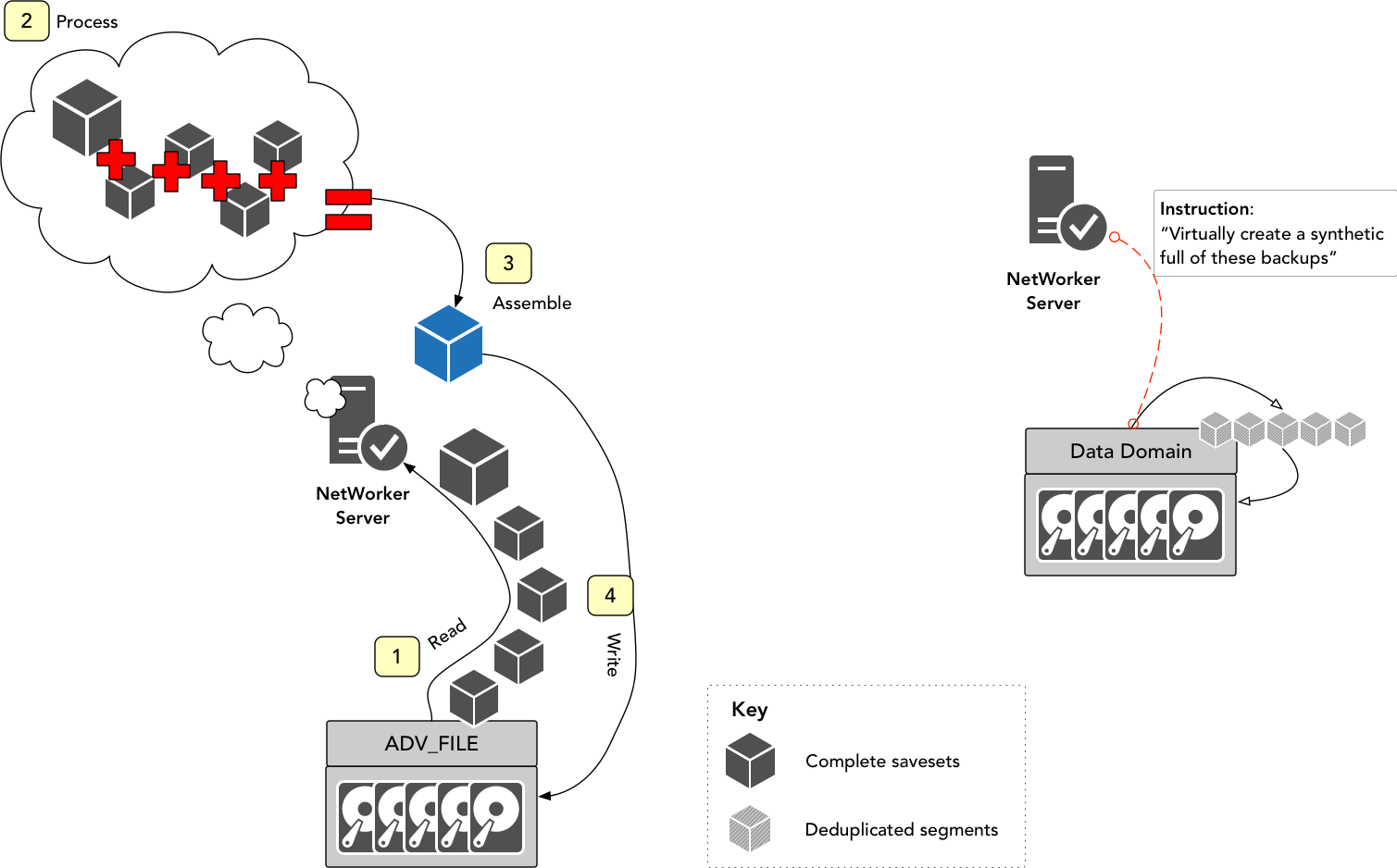
On the left, we have the process of creating a synthetic full when backups are stored on a regular AFTD device. I’ve simplified the operation, since it does happen in memory rather than requiring staging, etc. Effectively, the NetWorker server (or storage node) will read the various backups that need to be reconstituted into a new, synthetic full, up into memory, and as chunks of the new backup are constructed, they’re written back down onto the AFTD device as a new saveset.
When a Data Domain is involved though, the server gets a little lazier – instead, it just simply has the Data Domain virtually construct a synthetic full – remember, at the back end on the Data Domain, it’s all deduplicated segments of data along with metadata maps that define what a complete ‘file’ is that was sent to the system. (In the case of NetWorker, by ‘file’ I’m referring to a saveset.) So the Data Domain assembles details of a new full without any data being sent over the network.
The difference is simple, but profound. In a traditional synthetic full, the NetWorker server (or storage node) is doing all the grunt work. It’s reading all the data up into itself, combining it appropriately and writing it back down. If you’ve got a 1TB full backup and 6 incremental backups, it’s having do read all that data – 1TB or more, up from disk storage, process it, and write another ~1TB backup back down to disk. With a virtual synthetic full, the Data Domain is doing all the heavy lifting. It’s being told what it needs to do, but it’s doing the reading and processing, and doing it more efficiently than a traditional data read.
So, there’s actually a big difference between synthetic full and virtual synthetic full, and virtual synthetic full is anything but a tautology.
That’s very interesting. I am in the process of upgrading both Networker and DataDomain OS to the latest revisions. Perhaps I can then take advantage of virtual synthetic fulls for my vSphere backups.