Public Cloud is one of those things that works great until it doesn’t. Now, there’s a lot of reasons why public cloud might stop working for you – it could be cost, complexity, business requirements, or service interruptions (which in themselves can be of many varieties from link failure between your business and the public cloud through to data loss situations).
The recent challenges experienced by AWS for their RDS customers in Sydney got me thinking about this a little more.
One of the problems as I see it is that we (and by we I mean “IT, collectively”) have been designing datacentres for so long now that it would be easy for someone looking at it from a I-just-want-a-service-running-quickly-now-please perspective could think IT is about unnecessary gold plating.
How do we turn that perspective around? A key starting point is to be able to articulate, in very straight forward terms, what the essential components are to ensuring business data is protected. Now here, I’m not talking about data protection as a security or privacy function – those are still both essential, but they’ll usually be handled by different teams, and we need to keep the components straight forward.
The way I think we get that message across is to use something I’m calling the FARR model, and it looks like this:
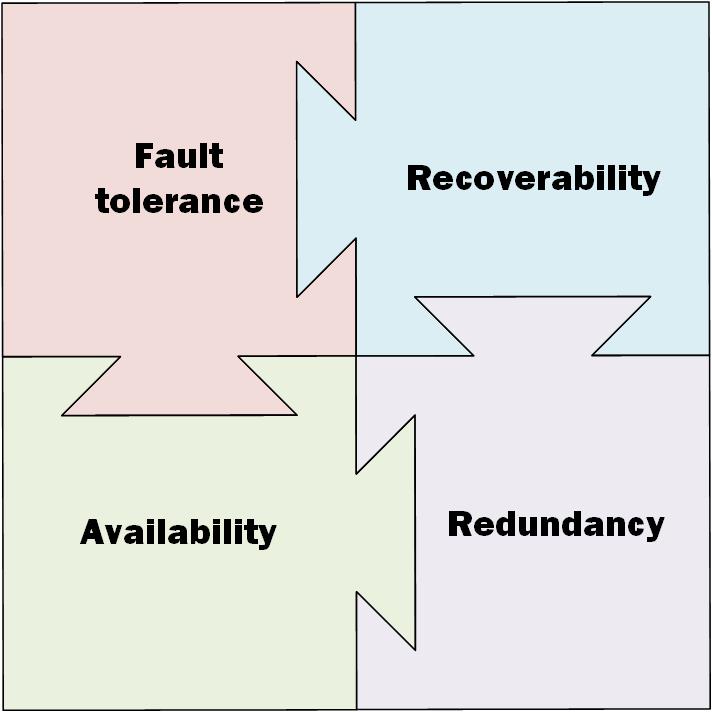
The FARR model can be applied to any environment, regardless of whether it’s cloud (public, hybrid or private), or a traditional datacentre/computer room environment. There’s four key considerations that have to be kept in mind:
- Fault tolerance: This is your baseline protection against individual storage component failure. If a disk (or flash) drive fails, you don’t want to lose your data. While we take fault tolerance for granted as something we can control and see alerts for within an on-premises environment, there’s less visibility and control in public cloud. More so, fault tolerance doesn’t give you protection from anything other than storage unit failure.
- Availability: “If a tree falls in the forest and no-one hears it, does it really make a noise?” That’s the old philosophical question that availability skirts around: if your data is online and error free, but you can’t access it, is it actually usable? Availability is about making sure you have protection against losing connectivity to the data/workload. For example: if your workload is one presented only back into the business, and the link between the business and the VPC in which it is running is lost, how do you get access to it again? Do you plan for multiple paths for availability, or do you accept a single point of failure on data/workload availability?
- Redundancy: You’re hosting your service in AWS Sydney, and there’s a fire in the datacentre – what’s your failover strategy? You’ve built a whiz-bang application for your customers that relies on a back-end RDS database, and the region hosting that database starts experiencing RDS services going down. How (and to where) do you failover your database service to allow customers to keep doing what they need to do?
- Recoverability: Ransomware gets into your VPC and encrypts all the data there. A developer accidentally issues a delete statement on the customer contact table within the production rather than development RDS environment. The CEO accidentally deletes critical O365 email folders. The block storage your service runs on suffers an outage and the cloud provider’s fault tolerance level was insufficient to prevent data corruption. Fault tolerance, availability and redundancy are all about avoiding as much as possible a data loss situation, but recoverability is how you handle the situation when the chips are down. Do you trust to cloud native protection, or use a mix of both? (Increasingly, mix of both is the safest, cheapest and most flexible way to go.)
What’s important to keep in mind about the FARR model is that it all has to be dealt with in the planning for the service or workload. It’s like the old chestnut about disaster recovery: if the first time you open your disaster recovery guide is when there’s a disaster to recover from, there’s a pretty good chance you won’t recover from the disaster (i.e., you won’t have planned properly).
The FARR model is in itself pretty self-evident to anyone who has worked in data protection as a storage/recovery function for a while, but in terms of quickly explaining the fundamentals of what we need to consider, regardless of where a workload is placed, it’s a good way to quickly get across the core concepts in a memorable way.
In the second edition of Data Protection: Ensuring Data Availability, I explore the FARR model in substantially more detail above, elaborating further on why it’s essential data protection architecture is built around these four fundamental pillars.
3 thoughts on “Basics – The FARR Model”