
Bad Things Happened at OVH
If you work in infrastructure, you probably saw some reference in the last week to OVH’s datacentre fire in Strasbourg where bad things happened. (An update on Friday March 12 suggested this might have come about from UPS issues.)
It’s fair to say that if you subscribe to datacentre services (regardless whether it’s private, co-location or cloud), these sorts of incident notes are not ones that you’d ever want to read:
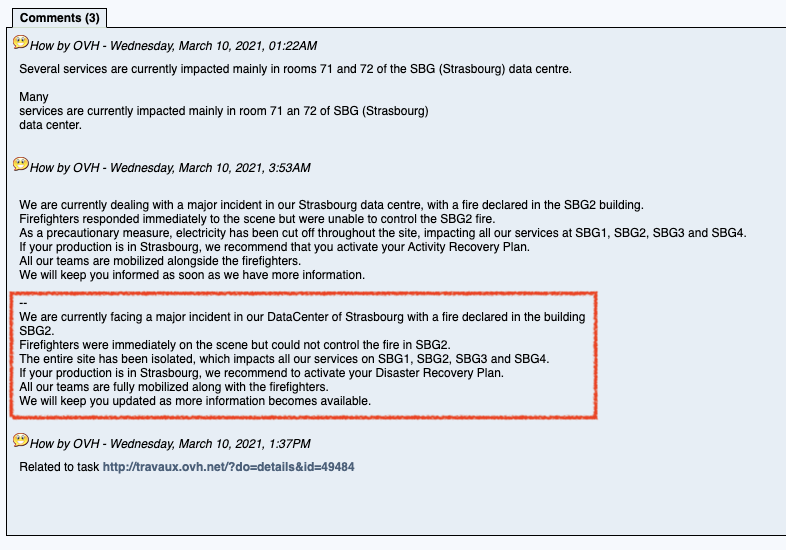
Bad things can happen at any datacentre
In fact, bad things can happen at any datacentre, and if you scratch the average infastructure worker, they’ll probably have a story or two to tell. Off-hand, I’ve been witness to several, including:
- A telecommunications worker was left (briefly) unsupervised in a datacentre and accidentally hit the “emergency stop” button instead of the “exit” button. (Not his fault: these were identical buttons side by side and senior team members had been arguing for some time that this was inviting an issue.)
- Fire suppression systems misfiring and causing a multi-day outage in a Colo service.
- The top-of-building water reservoir at a Colo provider burst and flooded into one of the computer rooms maintained by the provider for managed service customers.
- A similar top-of-building water incident, but for a single customer’s datacentre. (They were lucky in that ceiling tiles collapsed in such a way that it directed water away from their most expensive equipment, but they still lost more than half of their –at the time– legacy compute services over the course of a weekend.)
- A customer reporting that a tape library was dropping tapes because the datacentre’s air control systems weren’t filtering out dumped aviation fuel (under a flight-path) and tapes were getting slippery. (Hint: They worked out it wasn’t just the tape library that was getting damaged, after they started investigating.)
- A customer whose primary and disaster recovery datacentres were spaced some distance apart, but both located in short proximity to, and below the flood-line, of a river.
In the above, I’m not counting purely electronic failures – like a system administrator who accidentally executed “rm -rf /” (due to a faulty environment variable) shortly after getting automount configured across a large number of servers, or the rogue operator who snuck a “dead man’s switch” onto 200+ servers to ‘pay back’ an organisation if he were ever to be fired.
Bad things can happen to you
The obvious “preaching to the choir” message I’m leading towards here is: it doesn’t matter where you put your data, bad things can happen to it.
Despite jokes to the contrary about public cloud providers, datacentres aren’t atomic building blocks, even when the datacentre is privately owned. In single-building environments, each floor of the datacentre is broken up into halls or rooms. Within those individual halls, you’ll of course have a series of racks. In larger complexes, you’ll have multiple buildings, similarly broken up.
It’s fair to say that a primary goal of datacentre design is to limit the fault domain to the smallest unit possible. Rack or less than a rack? Minor incident. Multiple racks? Incident. Entire hall? Major incident. Complete floor? Massive incident. Entire building? Craptapular incident.
I don’t care what public cloud providers tell you: the cloud is another datacentre. Or to be more precise, there is an atomic level/definition in a cloud service provider that equates to “one or more datacentres in proximity to one another”.
I don’t care whether the availability zone (or whatever it’s referred to) is a datacentre, datacentre complex, literally running in a container, sitting in a sealed unit under the sea or launched into orbit. (OK, launched into orbit would be pretty cool though.) It’s still susceptible to a failure that can compromise your business, and you have to take appropriate steps to protect yourself.
We Know All This
Yes, maybe we as in you and I do know this. Lamentably, that’s not everyone.
Indeed, OVH is an example of why we have to keep on speaking up and repeating our message so the people at the back of the room can hear us. I’ve been in the business of data protection now for 25+ years and I’m still having to repeat basic details like:
- RAID isn’t backup.
- Snapshots aren’t backup.
- Replication isn’t backup.
- If you can’t reach your data, it’s useless.
This article isn’t about me dissing on OVH, or dissing on public cloud.
Fundamental reliability for data services can only be obtained using a robust protection architecture such as the FARR model where you design for:
- Fault tolerance
- Availability
- Redundancy
- Recoverability
It doesn’t matter where data is – if you can’t elaborate on how you can meet all four of the above pillars for data protection for any service for which you’re the architect, owner or administrator, then your service may not be reliable. (I cover the FARR model in a lot more detail here.)
Bad things happen. Our role in infrastructure is neither to snicker nor hide from the lesson offered when events like the OVH disaster happen. We need learned people in the industry to stop shrugging and saying, “we all know this”, whenever one of these events happen, too. If your employer (or customer) has chosen to stick their head in the sand over fault types (backup, disaster recovery, availability, etc.), this is your opportunity to start sharing information and point out to the people in control of the budget how their setup might have come to grief had they been hosting within OVH’s Strasbourg datacentre. Already we’re seeing examples of customers who didn’t build in sufficient redundancy:
Facepunch Studios, the game studio behind Rust, confirmed that even after it was back online that it would not be able to restore any data.
OVH datacenter disaster shows why recovery plans and backups are vital, Paul Sawers, Venturebeat, 10 March 2021.
And closing out – good luck to the staff and other customers at OVH: may all the rest of the recoveries be smooth and lossless.