
I promise this blog post has everything to do with data protection and the cloud shared responsibility model and nothing whatsoever to do with container ships in the Suez canal.
You’re probably familiar with the Cloud Shared Responsibility Model
It seems like everyone knows the “shared responsibility model” popularised by AWS. Certainly, for any cloud (or even managed) service you use, there’ll be a similar model. As a reminder, it looks like this:
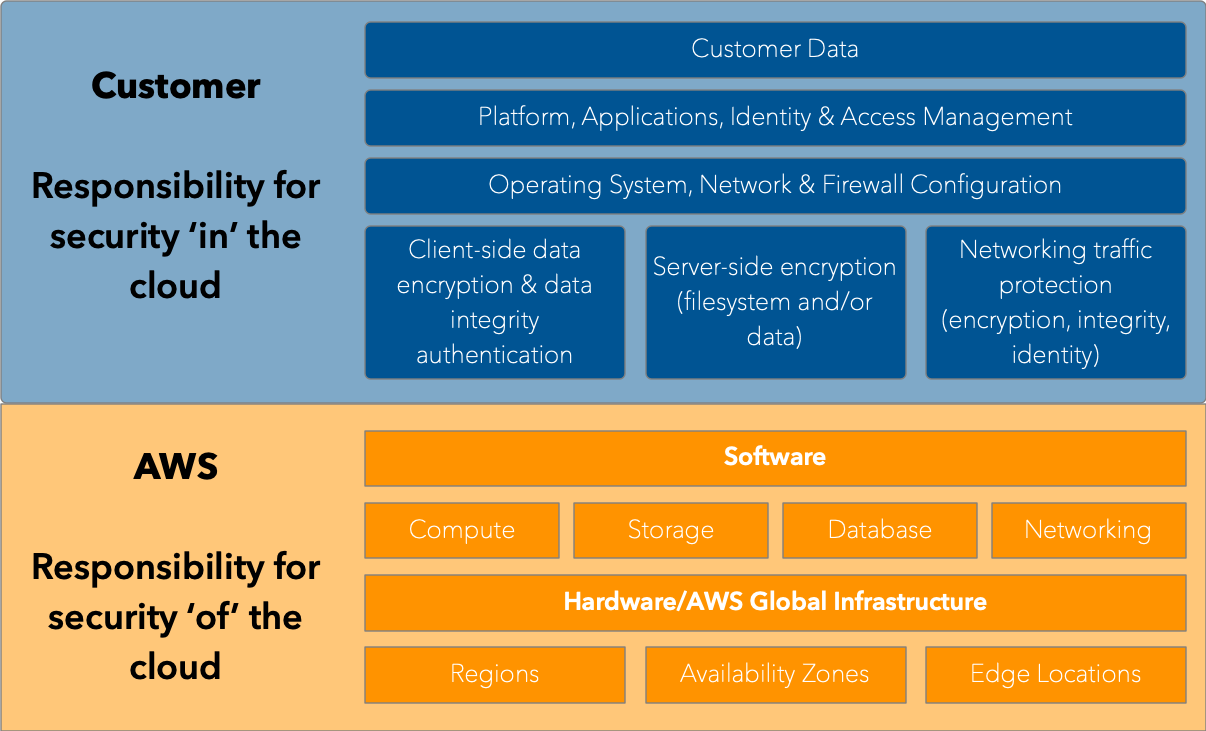
The purpose of the model is to provide customers of cloud service companies with some scope around what they are still responsible for, even when their data is hosted on someone else’s infrastructure. While shared responsibility models are focused on security, they also serve as a good grounding point for other areas, such as data protection. After all, “Customer Data” sits squarely in the purview of “Customer” responsibility, right?
But the Shared Responsibility Model Lies When it Comes to Data Protection
The shared responsibility model only gets you so far with data protection, however. Yes, customers have to be responsible for their data – it’s clearly shown in the model. And I 100% agree with this: any business making use of the public cloud is responsible for its data in the public cloud.
Imagine, if you will for a moment, a car that takes petrol (‘gasoline’, if you use USA-centric terminology for fuel). If your manufacturer produced a ‘shared responsibility model’ for vehicular ownership, putting petrol in the car would be pretty high on the list of customer responsibilities.
But what if the vehicle manufacturer didn’t actually provide a mechanism for efficiently filling the car with petrol? Indulge me a moment here – what if, every time you wanted to fill the car, you had to pop open a small cap, and pour a quarter cupful of petrol into a little reservoir, then wait a few minutes for that to happily gurgle down a pipe, before putting the next quarter cupful of fuel in?
Putting the ‘Shared’ in Shared Responsibility Model
So you probably get where I’m coming from, on this. In order for a customer to fill their car with petrol, there is a base level of work required of the car manufacturer to ensure the customer can fill their car with petrol, and in a way which minimises inconvenience.
So if I leave the world of fossil-fuelled vehicles behind and return to cloud, there’s a comparison waiting to be had. Yes, customers are responsible for their data. However, in order for customers to properly exercise their responsibility, there is a fundamental level of work required by the cloud vendors, too.
This is not always exercised. Do not @ me with ‘snowball’. If you think back to an earlier article of mine this year, 9 Essential Properties of Backup, 2 of those properties were:
- Sufficiently consistent
- Repeatable
Any snowball-esque egress technology fails both of those properties.
Why is this such a regular failure on behalf of the public cloud providers? Well, there are two key challenges at play, here:
Data protection is boring
I’ve been in the industry for more than 25 years now, and if there’s one thing I’ve learnt is that there is only a very small subset of the industry that finds data storage protection interesting. Regardless of whether you’re a developer, business user, infrastructure or application administrator, most people in and around tech industries find data protection to be at most a necessary evil. In the same way I still have people start a conversation with “no-one thought about backup when planning for this service”, it’s no wonder that cloud companies find it much more fun to release new services than they do to go back and add appropriate data protection hooks into existing services.
Data protection is data mobility
Providing access mechanisms for data protection functions (backup and recovery, for instance) is also technically makes it easier to completely remove the data from the original location. If you’ve ever watched a DBA refresh a development/test database from a production backup, you know exactly what I’m talking about, here. But herein is the problem: if cloud vendors made hooks for efficient data protection easily accessible across every service they had, it would also be easy to do it for workload repatriation, or workload relocation in a multi-cloud environment. Hey, that’s funny, cloud service providers like to spin the story of “avoid vendor lock-in”. Hmmm.
Shared Responsibility Isn’t Just a Hyperscaler Problem
It’s easy in this to think I’m targeting AWS, Azure and GCP. But if I did that, I’d be creating a diversion for perhaps the worst offender in the cloud market.
In so many ways, SaaS is the ultimate way to consume workloads within the public cloud. Bring your own data, we supply everything else.
Yes, some SaaS providers are good at providing data protection links – Salesforce and Microsoft 365 are two excellent examples of this. But for every one SaaS provider that enables backup and recovery integration, there are thousands that don’t. SaaS is powerful and liberating – and perhaps a little too liberating. With no power comes no responsibility.
A Better Shared Responsibility Model
I’m not trying to be King Canute, here, telling the tide to stop coming in. I’m clearly a data protection fuddy-duddy. In a modern, cloud-oriented era, I’d love to spend most of my time educating cloud engineering teams on the importance of data protection. My personal attitude is that if you can’t adequately protect the data, the service is useless. But clearly, I’m in the minority on this crazy opinion.
So, that means we need a new shared responsibility model, a more appropriate one. And it kind of looks like this:
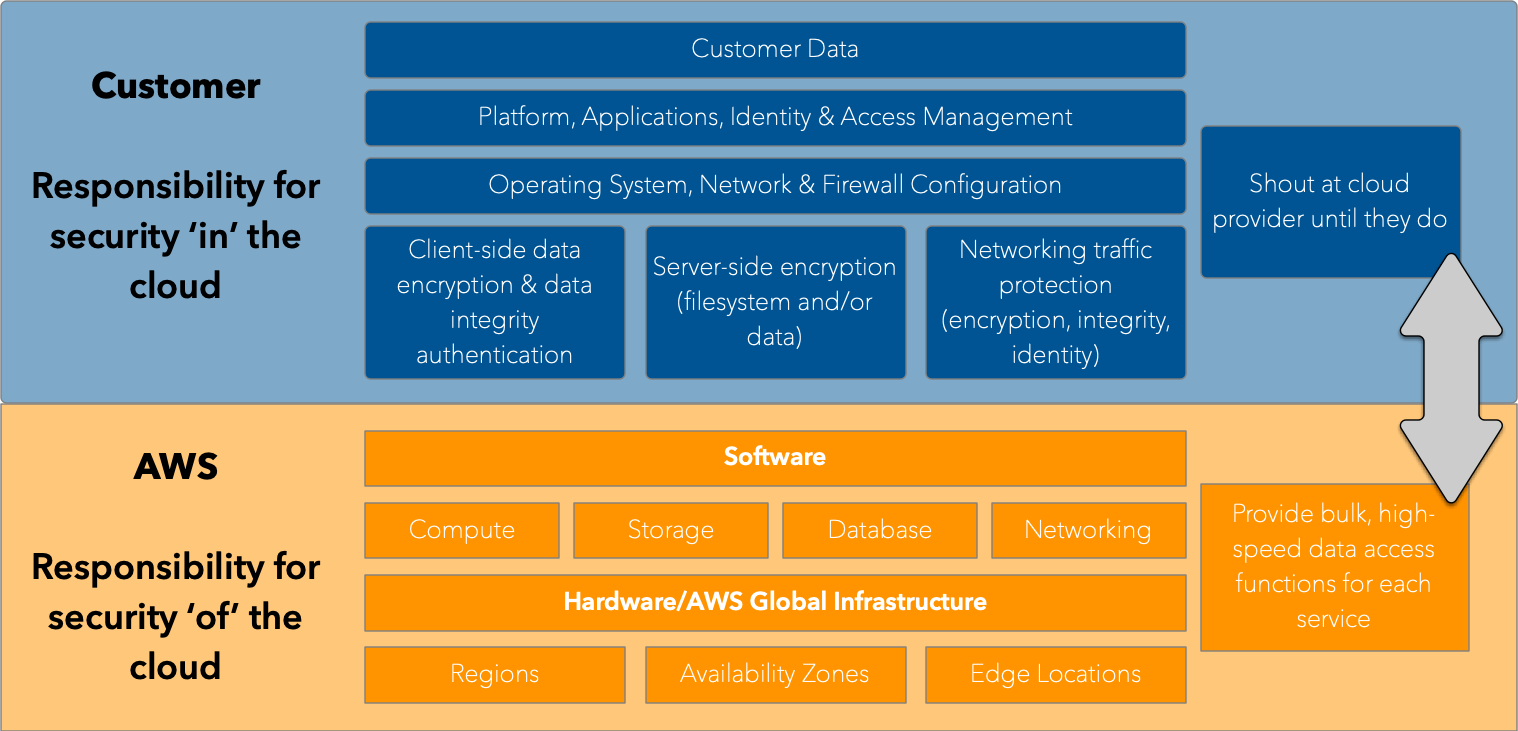
The challenges of data protection in the public cloud is not something that can be solved solely by the data protection vendors themselves. Any of them. Or indeed, all of them. And it shouldn’t be solved by finding private API calls or anything crazy like that.
At the end of the day, any consistent and repeatable data protection activity in the public cloud, like any other infrastructure, requires access hooks to be provided by the public cloud companies. (For instance, to backup Oracle databases consistently and repeatable, you rely on RMAN. Don’t @ me about dump & sweep.)
So we have two new responsibilities introduced into the shared responsibility model:
- Cloud providers have to provide bulk, high-speed data access functions for each service that creates data – functions that can be used for data protection.
- Customers need to shout at cloud service providers loudly until this functionality is provided.
Ten years ago, cloud was “the wild west” of the IT industry. That time has passed; cloud has grown up and that means doing grown up things, like taking responsibility for data protection.
With that in mind, please remember to shout at your public cloud account managers. Politely, of course – but loudly.
Finally opinion I can fully relate to. With Your kind permission, I’d like to mention this blog within my upcoming presentation at Cloud Computing online conference in Czech republic.
By all means.