
I got a real-world reminder in cascading failures this weekend, and that’s as good a time as any for me to pull up a chair, and chat about why we backup.
Cascading Failures Averted
I have a few RAID systems in my environment at home. The latest is an OWC 8-bay Thunderbolt-3 enclosure attached to my Mac Mini. When I retired my 2013 Mac Pro last year, I kept it around to run vSphere within VMware Fusion, and attached to it is a 4-drive Thunderbolt-2 Promise system.
In addition to those direct-attach units, I’ve got three Synology systems as well. A DS1513+ (5-drive) with an extension pack, a DS414 (4-drive) and a DS414j (4-drive). The DS1513+ is our “home storage” platform, and that’s where I likely averted a cascading failure late last year.
That system had been set up with 5 x 3TB drives initially, and around November last year, I realised the drive stats were showing that those drives had managed to log over 61,000 hours of operation – pretty much 7 years of run time. That made me a wee bit nervous, so I made use of the Synology Hybrid RAID function to not only replace the drives but also expand the home-share capacity using 6TB drives.
What I didn’t think to do was to check the drives in the DS414. It turned out, they’d been running for almost as long.
Cascading Failures in Play
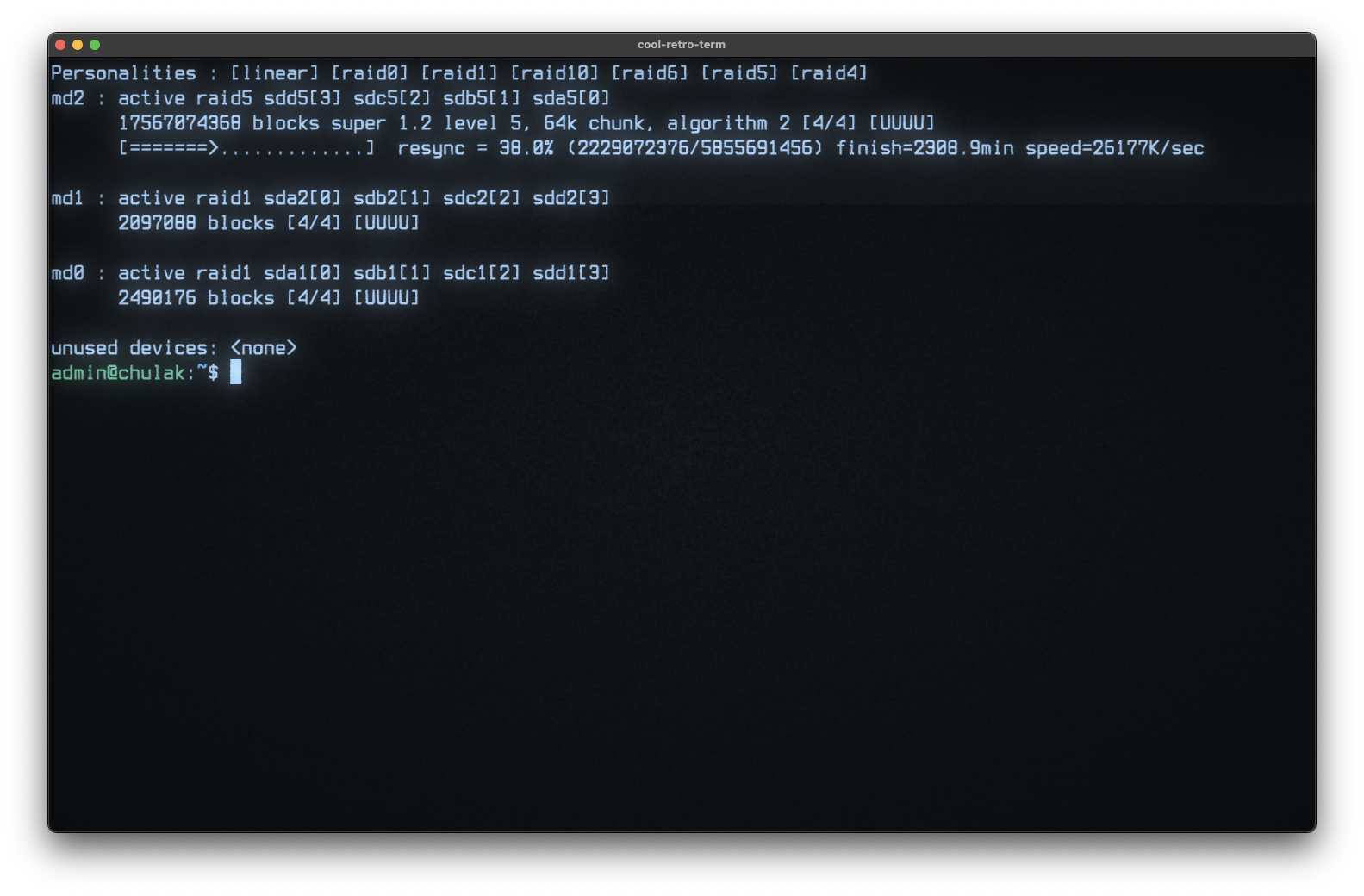
So on Friday, I got an email from my DS414 warning that the number of bad sectors being remapped on one of its drives had increased quite a bit. So, I logged on and triggered a deep S.M.A.R.T. test, which a few hours prompted an alert that the drive was failing and should be replaced ASAP.
Of course, all 4 drives in the Synology had been purchased at the same time, were the same age, and as you’d expect, had similar run hours. In fact, like the DS1513+ when I replaced its drives, these were all now coming up to the 61,000 hour mark.
So with some trepidation, I pulled the failing drive, added a spare 3TB drive, and let it start rebuilding the RAID unit.
Then Saturday morning, I woke to news of multiple IO failures during the rebuild. Thankfully, they weren’t total drive failures, but two different drives had suffered IO timeouts that eventually rendered the data filesystem corrupted during the rebuild. (Thankfully, the OS partitions had been spared – so I was at least able to get an email about the news.) I was offered the opportunity to reboot and run fsck – and 7 hours later from that, I was told the filesystem was unrecoverable.
So it was time to pull out my wallet and fork out some $$$ for four new drives to replace what was rapidly turning into a house of horrors within the DS414.
Lucky Failure
All things considered, I’m counting myself lucky with the failure. The DS414 was a backup storage volume. While I lost some backups, they weren’t long-term retention backups, so the data loss could be dealt with (in the scheme of home storage failures) by running new backups. (My long-term retention/critical backups get cloud as well as local protection.)
I can summarise a few quick notes from the overall process:
- Synology has an excellent online compatibility guide for drive models these days. However, you also have to check the CPU compatibility guide. I bought 4 x 6TB drives which would present 16.36TB of storage after RAID-5, and the system obstinately refused to create a volume/filesystem greater than 16TB because the CPU in that model is only 32-bit. So, some fiddling later, I managed to get two volumes created – a 16TB filesystem and another <1TB.
- I often joke that there is nothing in IT slower than installing an Apple Watch OS update. This was my periodic reminder that there is something slower: Linux md RAID rebuilds.
Data Protection is Born from Cascading Failures
A good data protection architecture is built on four pillars:
- Fault tolerance – Hardware-level protection against component failure
- Availability – Multipathed access to data
- Redundancy – Higher level ‘failover’ protection for services
- Recoverability – Being able to get the data back if all else fails
I know I’ve been banging on a bit about the FARR model of late, but the reason I’ve been doing so is that it’s so damn important. We build up protection using all four of those pillars – rather than a single one – because cascading failures happen all the time. Our lives in data protection would be simpler if we could just limit ourselves to one of the four pillars. But that’s just not how the world – or technology – works.
In the second edition of Data Protection, I spent a fair chunk of a chapter elaborating on the FARR model, and I’m glad I went to that effort. I genuinely believe it represents the fundamental pillars you have to establish as part of a data protection model, and perhaps most importantly, you can use those pillars to get the budget owners in the business to understand, too. And this weekend reminded me personally why the FARR model is so important.
1 thought on “Of Cascading Failures”